 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCLR: Improving Conditional Modeling in Visual Generative Models via Inter-Class Likelihood-Ratio Maximization and Establishing the Equivalence between Classifier-Free Guidance and Alignment Objectives
Mar 23, 2026Diffusion models have achieved state-of-the-art performance in generative modeling, but their success often relies heavily on classifier-free guidance (CFG), an inference-time heuristic that modifies the sampling trajectory. From a theoretical perspective, diffusion models trained with standard denoising score matching (DSM) are expected to recover the target data distribution, raising the question of why inference-time guidance is necessary in practice. In this work, we ask whether the DSM training objective can be modified in a principled manner such that standard reverse-time sampling, without inference-time guidance, yields effects comparable to CFG. We identify insufficient inter-class separation as a key limitation of standard diffusion models. To address this, we propose MCLR, a principled alignment objective that explicitly maximizes inter-class likelihood-ratios during training. Models fine-tuned with MCLR exhibit CFG-like improvements under standard sampling, achieving comparable qualitative and quantitative gains without requiring inference-time guidance. Beyond empirical benefits, we provide a theoretical result showing that the CFG-guided score is exactly the optimal solution to a weighted MCLR objective. This establishes a formal equivalence between classifier-free guidance and alignment-based objectives, offering a mechanistic interpretation of CFG.
Low-Bit Quantization of Bandlimited Graph Signals via Iterative Methods
Jan 26, 2026We study the quantization of real-valued bandlimited signals on graphs, focusing on low-bit representations. We propose iterative noise-shaping algorithms for quantization, including sampling approaches with and without vertex replacement. The methods leverage the spectral properties of the graph Laplacian and exploit graph incoherence to achieve high-fidelity approximations. Theoretical guarantees are provided for the random sampling method, and extensive numerical experiments on synthetic and real-world graphs illustrate the efficiency and robustness of the proposed schemes.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
NERD: Network-Regularized Diffusion Sampling For 3D Computed Tomography
Nov 18, 2025Numerous diffusion model (DM)-based methods have been proposed for solving inverse imaging problems. Among these, a recent line of work has demonstrated strong performance by formulating sampling as an optimization procedure that enforces measurement consistency, forward diffusion consistency, and both step-wise and backward diffusion consistency. However, these methods have only considered 2D reconstruction tasks and do not directly extend to 3D image reconstruction problems, such as in Computed Tomography (CT). To bridge this gap, we propose NEtwork-Regularized diffusion sampling for 3D CT (NERD) by incorporating an L1 regularization into the optimization objective. This regularizer encourages spatial continuity across adjacent slices, reducing inter-slice artifacts and promoting coherent volumetric reconstructions. Additionally, we introduce two efficient optimization strategies to solve the resulting objective: one based on the Alternating Direction Method of Multipliers (ADMM) and another based on the Primal-Dual Hybrid Gradient (PDHG) method. Experiments on medical 3D CT data demonstrate that our approach achieves either state-of-the-art or highly competitive results.
On the Convergence of Moral Self-Correction in Large Language Models
Oct 08, 2025



Large Language Models (LLMs) are able to improve their responses when instructed to do so, a capability known as self-correction. When instructions provide only a general and abstract goal without specific details about potential issues in the response, LLMs must rely on their internal knowledge to improve response quality, a process referred to as intrinsic self-correction. The empirical success of intrinsic self-correction is evident in various applications, but how and why it is effective remains unknown. Focusing on moral self-correction in LLMs, we reveal a key characteristic of intrinsic self-correction: performance convergence through multi-round interactions; and provide a mechanistic analysis of this convergence behavior. Based on our experimental results and analysis, we uncover the underlying mechanism of convergence: consistently injected self-correction instructions activate moral concepts that reduce model uncertainty, leading to converged performance as the activated moral concepts stabilize over successive rounds. This paper demonstrates the strong potential of moral self-correction by showing that it exhibits a desirable property of converged performance.
Variational Learning Finds Flatter Solutions at the Edge of Stability
Jun 15, 2025Variational Learning (VL) has recently gained popularity for training deep neural networks and is competitive to standard learning methods. Part of its empirical success can be explained by theories such as PAC-Bayes bounds, minimum description length and marginal likelihood, but there are few tools to unravel the implicit regularization in play. Here, we analyze the implicit regularization of VL through the Edge of Stability (EoS) framework. EoS has previously been used to show that gradient descent can find flat solutions and we extend this result to VL to show that it can find even flatter solutions. This is obtained by controlling the posterior covariance and the number of Monte Carlo samples from the posterior. These results are derived in a similar fashion as the standard EoS literature for deep learning, by first deriving a result for a quadratic problem and then extending it to deep neural networks. We empirically validate these findings on a wide variety of large networks, such as ResNet and ViT, to find that the theoretical results closely match the empirical ones. Ours is the first work to analyze the EoS dynamics in VL.
Towards Understanding the Mechanisms of Classifier-Free Guidance
May 25, 2025Classifier-free guidance (CFG) is a core technique powering state-of-the-art image generation systems, yet its underlying mechanisms remain poorly understood. In this work, we begin by analyzing CFG in a simplified linear diffusion model, where we show its behavior closely resembles that observed in the nonlinear case. Our analysis reveals that linear CFG improves generation quality via three distinct components: (i) a mean-shift term that approximately steers samples in the direction of class means, (ii) a positive Contrastive Principal Components (CPC) term that amplifies class-specific features, and (iii) a negative CPC term that suppresses generic features prevalent in unconditional data. We then verify that these insights in real-world, nonlinear diffusion models: over a broad range of noise levels, linear CFG resembles the behavior of its nonlinear counterpart. Although the two eventually diverge at low noise levels, we discuss how the insights from the linear analysis still shed light on the CFG's mechanism in the nonlinear regime.
Learning Dynamics of Deep Linear Networks Beyond the Edge of Stability
Feb 27, 2025



Deep neural networks trained using gradient descent with a fixed learning rate $\eta$ often operate in the regime of "edge of stability" (EOS), where the largest eigenvalue of the Hessian equilibrates about the stability threshold $2/\eta$. In this work, we present a fine-grained analysis of the learning dynamics of (deep) linear networks (DLNs) within the deep matrix factorization loss beyond EOS. For DLNs, loss oscillations beyond EOS follow a period-doubling route to chaos. We theoretically analyze the regime of the 2-period orbit and show that the loss oscillations occur within a small subspace, with the dimension of the subspace precisely characterized by the learning rate. The crux of our analysis lies in showing that the symmetry-induced conservation law for gradient flow, defined as the balancing gap among the singular values across layers, breaks at EOS and decays monotonically to zero. Overall, our results contribute to explaining two key phenomena in deep networks: (i) shallow models and simple tasks do not always exhibit EOS; and (ii) oscillations occur within top features. We present experiments to support our theory, along with examples demonstrating how these phenomena occur in nonlinear networks and how they differ from those which have benign landscape such as in DLNs.
Understanding Untrained Deep Models for Inverse Problems: Algorithms and Theory
Feb 25, 2025


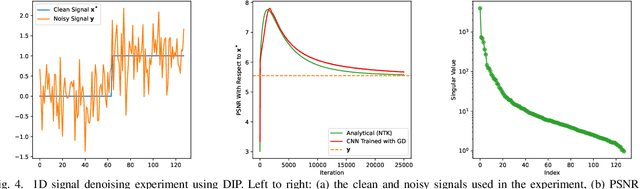
In recent years, deep learning methods have been extensively developed for inverse imaging problems (IIPs), encompassing supervised, self-supervised, and generative approaches. Most of these methods require large amounts of labeled or unlabeled training data to learn effective models. However, in many practical applications, such as medical image reconstruction, extensive training datasets are often unavailable or limited. A significant milestone in addressing this challenge came in 2018 with the work of Ulyanov et al., which introduced the Deep Image Prior (DIP)--the first training-data-free neural network method for IIPs. Unlike conventional deep learning approaches, DIP requires only a convolutional neural network, the noisy measurements, and a forward operator. By leveraging the implicit regularization of deep networks initialized with random noise, DIP can learn and restore image structures without relying on external datasets. However, a well-known limitation of DIP is its susceptibility to overfitting, primarily due to the over-parameterization of the network. In this tutorial paper, we provide a comprehensive review of DIP, including a theoretical analysis of its training dynamics. We also categorize and discuss recent advancements in DIP-based methods aimed at mitigating overfitting, including techniques such as regularization, network re-parameterization, and early stopping. Furthermore, we discuss approaches that combine DIP with pre-trained neural networks, present empirical comparison results against data-centric methods, and highlight open research questions and future directions.
Smaller Large Language Models Can Do Moral Self-Correction
Oct 30, 2024
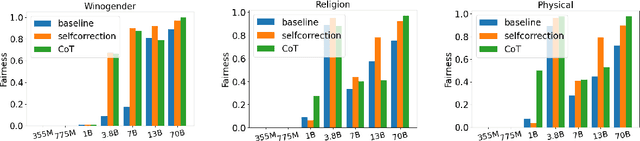
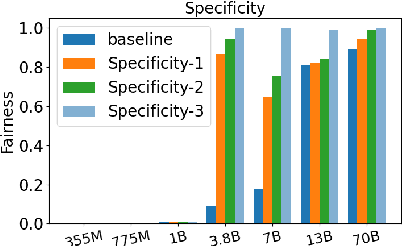
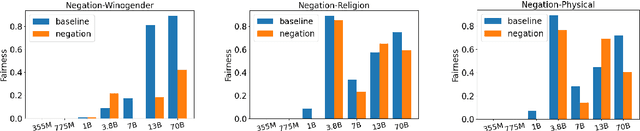
Self-correction is one of the most amazing emerging capabilities of Large Language Models (LLMs), enabling LLMs to self-modify an inappropriate output given a natural language feedback which describes the problems of that output. Moral self-correction is a post-hoc approach correcting unethical generations without requiring a gradient update, making it both computationally lightweight and capable of preserving the language modeling ability. Previous works have shown that LLMs can self-debias, and it has been reported that small models, i.e., those with less than 22B parameters, are not capable of moral self-correction. However, there is no direct proof as to why such smaller models fall short of moral self-correction, though previous research hypothesizes that larger models are skilled in following instructions and understanding abstract social norms. In this paper, we empirically validate this hypothesis in the context of social stereotyping, through meticulous prompting. Our experimental results indicate that (i) surprisingly, 3.8B LLMs with proper safety alignment fine-tuning can achieve very good moral self-correction performance, highlighting the significant effects of safety alignment; and (ii) small LLMs are indeed weaker than larger-scale models in terms of comprehending social norms and self-explanation through CoT, but all scales of LLMs show bad self-correction performance given unethical instructions.