 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Reinforcement Learning for Fluid Transitions Between Clinical Mental Healthcare and Everyday Wellness Support
Jun 05, 2026Mental health struggles wax and wane, yet clinical and wellness interventions typically operate separately, causing frequent breakdowns at care transitions. We explore reinforcement learning (RL) as a means to build digital health systems that deliver clinical and wellness interventions proactively, as part of a coherent care journey. We ask: what complexities does designing such a system involve? We built a contextual bandit that dynamically selects journaling prompts from clinical and wellness repertoires to optimize for an overarching health goal (sustained journaling) and deployed it in a four-week exploratory study (N=38). We found that, first, many benefits of RL-optimized intervention sequences appeared only after interventions ended, raising the question: Should systems that offer coherent clinical-wellness care journeys include stepping-back periods? If so, when and how? Second, participants most engaged with RL-generated interventions deepened their engagement over time, while those most engaged with a constant intervention tended to burn out and drop out later. It raises the question: When should a system blending clinical and wellness interventions reduce intensity to prevent burnout in versus sustain it to maximize treatment gains?
Synthetic Data from Cross-Domain Events for Large-Scale Recommendation Systems
May 29, 2026Large-scale recommendation systems operate across diverse domains, yet they face the challenges of data sparsity and noisy implicit feedback. Traditional approaches mitigate this via model-specific knowledge distillation from source domains to a target domain. Inspired by the transformative success of synthetic data generation in large language models (LLMs), we introduce Synthetic Cross-domain Augmentation and Learning for Recommendation (SCALR), a framework that generates synthetic user-item interaction events for a target recommendation domain by leveraging observed events from a source domain. SCALR decomposes cross-domain learning into two modular stages. First, it translates observed user events in source domains by framing event generation as estimating the likelihood that a user would interact with a target-domain item, conditioned on their observed interactions in a source domain. Second, downstream models train on these synthetic events as cross-domain learning objectives, where the synthetic events augment the target domain's training data in a model-agnostic manner. Our approach yields statistically significant improvements in online A/B tests on an industrial recommendation platform. To the best of our knowledge, this is among the first works to explicitly frame cross-domain event transfer as synthetic data generation for recommendation systems.
Enhancing Visual Token Representations for Video Large Language Models via Training-Free Spatial-Temporal Pooling and Gridding
May 21, 2026Recent advances in Multimodal Large Language Models (MLLMs) have significantly advanced video understanding tasks, yet challenges remain in efficiently compressing visual tokens while preserving spatiotemporal interactions. Existing methods, such as LLaVA family, utilize simplistic pooling or interpolation techniques that overlook the intricate dynamics of visual tokens. To bridge this gap, we propose ST-GridPool, a novel training-free visual token enhancement method designed specifically for Video LLMs. Our approach integrates Pyramid Temporal Gridding (PTG), which captures multi-grained spatiotemporal interactions through hierarchical temporal gridding, and Norm-based Spatial Pooling (NSP), which preserves high-information visual regions by leveraging the correlation between token norms and semantic richness. Extensive experiments on various benchmarks demonstrate that ST-GridPool consistently enhances performance of Video LLMs without requiring costly retraining. Our method offers an efficient and plug-and-play solution for improving visual token representations. Our code is available in https://github.com/bingjunluo/ST-GridPool.
ST-SimDiff: Balancing Spatiotemporal Similarity and Difference for Efficient Video Understanding with MLLMs
May 21, 2026Multimodal Large Language Models (MLLMs) face significant computational overhead when processing long videos due to the massive number of visual tokens required. To improve efficiency, existing methods primarily reduce redundancy by pruning or merging tokens based on importance or similarity. However, these approaches largely overlook a critical dimension of video content, i.e., changes and turning points, and they lack a collaborative model for spatio-temporal relationships. To address this, we propose a new perspective: similarity is for identifying redundancy, while difference is for capturing key events. Based on this, we designed a training-free framework named ST-SimDiff. We first construct a spatio-temporal graph from the visual tokens to uniformly model their complex associations. Subsequently, we employ a parallel dual-selection strategy: 1) similarity-based selection uses community detection to retain representative tokens, compressing static information; 2) temporal difference-based selection precisely locates content-changing points to preserve tokens that capture key dynamic shifts. This allows it to preserve both static and dynamic content with a minimal number of tokens. Extensive experiments show our method significantly outperforms state-of-the-art approaches while substantially reducing computational costs. Our code is available in https://github.com/bingjunluo/ST-SimDiff.
CPGPrompt: Translating Clinical Guidelines into LLM-Executable Decision Support
Jan 07, 2026Clinical practice guidelines (CPGs) provide evidence-based recommendations for patient care; however, integrating them into Artificial Intelligence (AI) remains challenging. Previous approaches, such as rule-based systems, face significant limitations, including poor interpretability, inconsistent adherence to guidelines, and narrow domain applicability. To address this, we develop and validate CPGPrompt, an auto-prompting system that converts narrative clinical guidelines into large language models (LLMs). Our framework translates CPGs into structured decision trees and utilizes an LLM to dynamically navigate them for patient case evaluation. Synthetic vignettes were generated across three domains (headache, lower back pain, and prostate cancer) and distributed into four categories to test different decision scenarios. System performance was assessed on both binary specialty-referral decisions and fine-grained pathway-classification tasks. The binary specialty referral classification achieved consistently strong performance across all domains (F1: 0.85-1.00), with high recall (1.00 $\pm$ 0.00). In contrast, multi-class pathway assignment showed reduced performance, with domain-specific variations: headache (F1: 0.47), lower back pain (F1: 0.72), and prostate cancer (F1: 0.77). Domain-specific performance differences reflected the structure of each guideline. The headache guideline highlighted challenges with negation handling. The lower back pain guideline required temporal reasoning. In contrast, prostate cancer pathways benefited from quantifiable laboratory tests, resulting in more reliable decision-making.
Reinforcement Learning for Monetary Policy Under Macroeconomic Uncertainty: Analyzing Tabular and Function Approximation Methods
Dec 09, 2025We study how a central bank should dynamically set short-term nominal interest rates to stabilize inflation and unemployment when macroeconomic relationships are uncertain and time-varying. We model monetary policy as a sequential decision-making problem where the central bank observes macroeconomic conditions quarterly and chooses interest rate adjustments. Using publically accessible historical Federal Reserve Economic Data (FRED), we construct a linear-Gaussian transition model and implement a discrete-action Markov Decision Process with a quadratic loss reward function. We chose to compare nine different reinforcement learning style approaches against Taylor Rule and naive baselines, including tabular Q-learning variants, SARSA, Actor-Critic, Deep Q-Networks, Bayesian Q-learning with uncertainty quantification, and POMDP formulations with partial observability. Surprisingly, standard tabular Q-learning achieved the best performance (-615.13 +- 309.58 mean return), outperforming both enhanced RL methods and traditional policy rules. Our results suggest that while sophisticated RL techniques show promise for monetary policy applications, simpler approaches may be more robust in this domain, highlighting important challenges in applying modern RL to macroeconomic policy.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Facilitating Longitudinal Interaction Studies of AI Systems
Aug 14, 2025UIST researchers develop tools to address user challenges. However, user interactions with AI evolve over time through learning, adaptation, and repurposing, making one time evaluations insufficient. Capturing these dynamics requires longer-term studies, but challenges in deployment, evaluation design, and data collection have made such longitudinal research difficult to implement. Our workshop aims to tackle these challenges and prepare researchers with practical strategies for longitudinal studies. The workshop includes a keynote, panel discussions, and interactive breakout groups for discussion and hands-on protocol design and tool prototyping sessions. We seek to foster a community around longitudinal system research and promote it as a more embraced method for designing, building, and evaluating UIST tools.
RaSCL: Radar to Satellite Crossview Localization
Apr 22, 2025GNSS is unreliable, inaccurate, and insufficient in many real-time autonomous field applications. In this work, we present a GNSS-free global localization solution that contains a method of registering imaging radar on the ground with overhead RGB imagery, with joint optimization of relative poses from odometry and global poses from our overhead registration. Previous works have used various combinations of ground sensors and overhead imagery, and different feature extraction and matching methods. These include various handcrafted and deep-learning-based methods for extracting features from overhead imagery. Our work presents insights on extracting essential features from RGB overhead images for effective global localization against overhead imagery using only ground radar and a single georeferenced initial guess. We motivate our method by evaluating it on datasets in diverse geographic conditions and robotic platforms, including on an Unmanned Surface Vessel (USV) as well as urban and suburban driving datasets.
AGENTiGraph: An Interactive Knowledge Graph Platform for LLM-based Chatbots Utilizing Private Data
Oct 15, 2024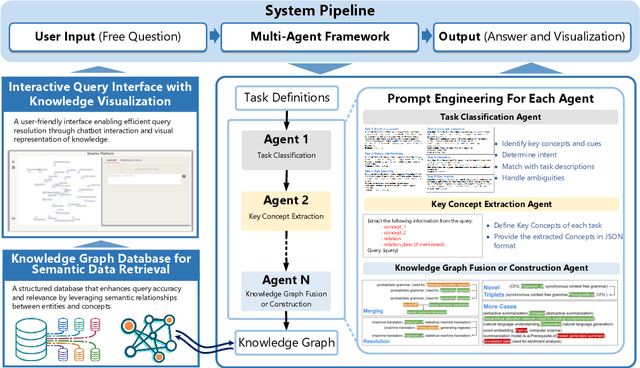
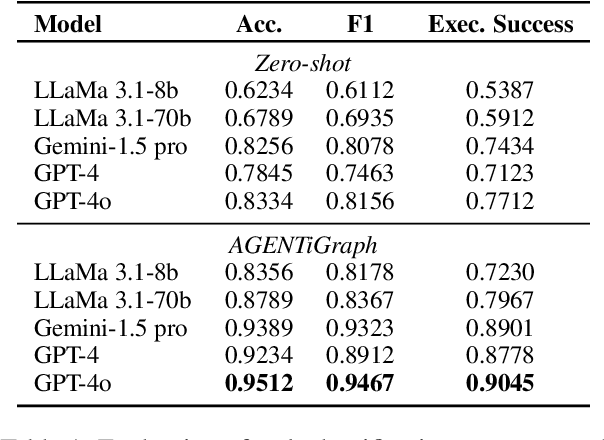
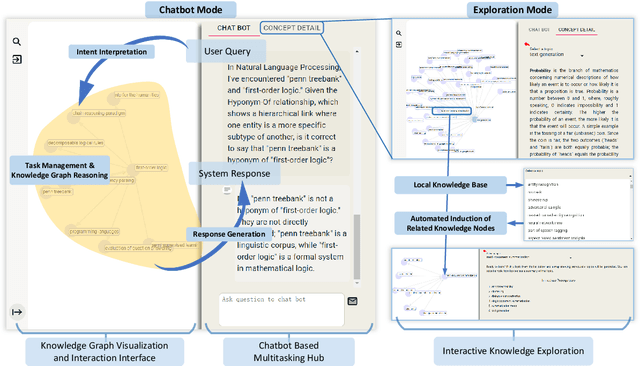
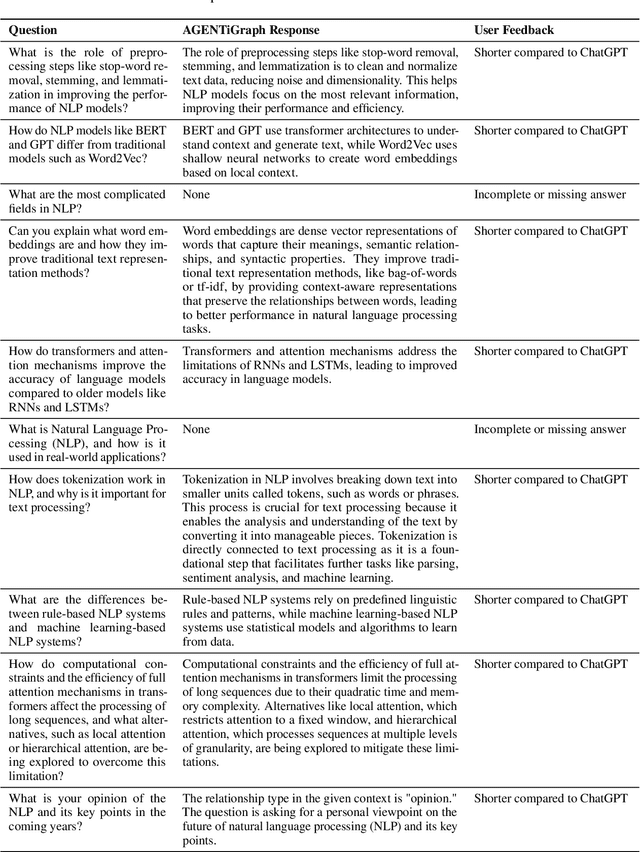
Large Language Models~(LLMs) have demonstrated capabilities across various applications but face challenges such as hallucination, limited reasoning abilities, and factual inconsistencies, especially when tackling complex, domain-specific tasks like question answering~(QA). While Knowledge Graphs~(KGs) have been shown to help mitigate these issues, research on the integration of LLMs with background KGs remains limited. In particular, user accessibility and the flexibility of the underlying KG have not been thoroughly explored. We introduce AGENTiGraph (Adaptive Generative ENgine for Task-based Interaction and Graphical Representation), a platform for knowledge management through natural language interaction. It integrates knowledge extraction, integration, and real-time visualization. AGENTiGraph employs a multi-agent architecture to dynamically interpret user intents, manage tasks, and integrate new knowledge, ensuring adaptability to evolving user requirements and data contexts. Our approach demonstrates superior performance in knowledge graph interactions, particularly for complex domain-specific tasks. Experimental results on a dataset of 3,500 test cases show AGENTiGraph significantly outperforms state-of-the-art zero-shot baselines, achieving 95.12\% accuracy in task classification and 90.45\% success rate in task execution. User studies corroborate its effectiveness in real-world scenarios. To showcase versatility, we extended AGENTiGraph to legislation and healthcare domains, constructing specialized KGs capable of answering complex queries in legal and medical contexts.