 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Illusion of Unlearning? Assessing Machine Unlearning Through Internal Representations
Apr 09, 2026While numerous machine unlearning (MU) methods have recently been developed with promising results in erasing the influence of forgotten data, classes, or concepts, they are also highly vulnerable-for example, simple fine-tuning can inadvertently reintroduce erased concepts. In this paper, we address this contradiction by examining the internal representations of unlearned models, in contrast to prior work that focuses primarily on output-level behavior. Our analysis shows that many state-of-the-art MU methods appear successful mainly due to a misalignment between last-layer features and the classifier, a phenomenon we call feature-classifier misalignment. In fact, hidden features remain highly discriminative, and simple linear probing can recover near-original accuracy. Assuming neural collapse in the original model, we further demonstrate that adjusting only the classifier can achieve negligible forget accuracy while preserving retain accuracy, and we corroborate this with experiments using classifier-only fine-tuning. Motivated by these findings, we propose MU methods based on a class-mean features (CMF) classifier, which explicitly enforces alignment between features and classifiers. Experiments on standard benchmarks show that CMF-based unlearning reduces forgotten information in representations while maintaining high retain accuracy, highlighting the need for faithful representation-level evaluation of MU.
Deep Neural Regression Collapse
Mar 25, 2026Neural Collapse is a phenomenon that helps identify sparse and low rank structures in deep classifiers. Recent work has extended the definition of neural collapse to regression problems, albeit only measuring the phenomenon at the last layer. In this paper, we establish that Neural Regression Collapse (NRC) also occurs below the last layer across different types of models. We show that in the collapsed layers of neural regression models, features lie in a subspace that corresponds to the target dimension, the feature covariance aligns with the target covariance, the input subspace of the layer weights aligns with the feature subspace, and the linear prediction error of the features is close to the overall prediction error of the model. In addition to establishing Deep NRC, we also show that models that exhibit Deep NRC learn the intrinsic dimension of low rank targets and explore the necessity of weight decay in inducing Deep NRC. This paper provides a more complete picture of the simple structure learned by deep networks in the context of regression.
Low Rank and Sparse Fourier Structure in Recurrent Networks Trained on Modular Addition
Mar 28, 2025Modular addition tasks serve as a useful test bed for observing empirical phenomena in deep learning, including the phenomenon of \emph{grokking}. Prior work has shown that one-layer transformer architectures learn Fourier Multiplication circuits to solve modular addition tasks. In this paper, we show that Recurrent Neural Networks (RNNs) trained on modular addition tasks also use a Fourier Multiplication strategy. We identify low rank structures in the model weights, and attribute model components to specific Fourier frequencies, resulting in a sparse representation in the Fourier space. We also show empirically that the RNN is robust to removing individual frequencies, while the performance degrades drastically as more frequencies are ablated from the model.
On Generalization Bounds for Neural Networks with Low Rank Layers
Nov 20, 2024
While previous optimization results have suggested that deep neural networks tend to favour low-rank weight matrices, the implications of this inductive bias on generalization bounds remain underexplored. In this paper, we apply Maurer's chain rule for Gaussian complexity to analyze how low-rank layers in deep networks can prevent the accumulation of rank and dimensionality factors that typically multiply across layers. This approach yields generalization bounds for rank and spectral norm constrained networks. We compare our results to prior generalization bounds for deep networks, highlighting how deep networks with low-rank layers can achieve better generalization than those with full-rank layers. Additionally, we discuss how this framework provides new perspectives on the generalization capabilities of deep networks exhibiting neural collapse.
Neural-guided, Bidirectional Program Search for Abstraction and Reasoning
Oct 26, 2021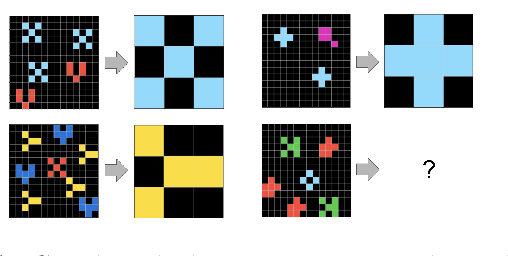



One of the challenges facing artificial intelligence research today is designing systems capable of utilizing systematic reasoning to generalize to new tasks. The Abstraction and Reasoning Corpus (ARC) measures such a capability through a set of visual reasoning tasks. In this paper we report incremental progress on ARC and lay the foundations for two approaches to abstraction and reasoning not based in brute-force search. We first apply an existing program synthesis system called DreamCoder to create symbolic abstractions out of tasks solved so far, and show how it enables solving of progressively more challenging ARC tasks. Second, we design a reasoning algorithm motivated by the way humans approach ARC. Our algorithm constructs a search graph and reasons over this graph structure to discover task solutions. More specifically, we extend existing execution-guided program synthesis approaches with deductive reasoning based on function inverse semantics to enable a neural-guided bidirectional search algorithm. We demonstrate the effectiveness of the algorithm on three domains: ARC, 24-Game tasks, and a 'double-and-add' arithmetic puzzle.
For interpolating kernel machines, the minimum norm ERM solution is the most stable
Jun 28, 2020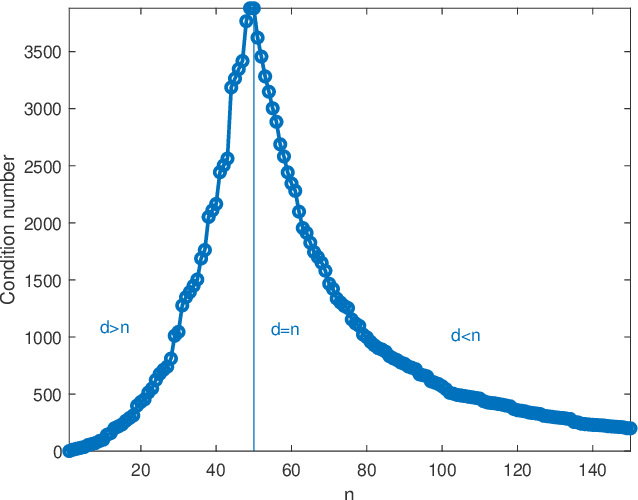
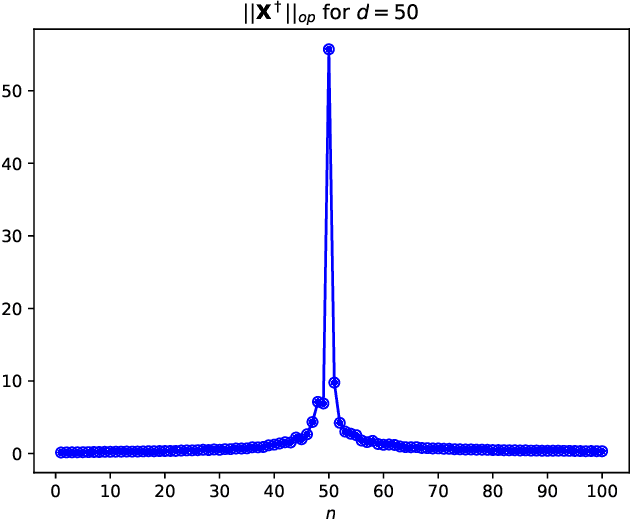
We study the average $\mbox{CV}_{loo}$ stability of kernel ridge-less regression and derive corresponding risk bounds. We show that the interpolating solution with minimum norm has the best $\mbox{CV}_{loo}$ stability, which in turn is controlled by the condition number of the empirical kernel matrix. The latter can be characterized in the asymptotic regime where both the dimension and cardinality of the data go to infinity. Under the assumption of random kernel matrices, the corresponding test error follows a double descent curve.
A Scale Invariant Flatness Measure for Deep Network Minima
Feb 06, 2019



It has been empirically observed that the flatness of minima obtained from training deep networks seems to correlate with better generalization. However, for deep networks with positively homogeneous activations, most measures of sharpness/flatness are not invariant to rescaling of the network parameters, corresponding to the same function. This means that the measure of flatness/sharpness can be made as small or as large as possible through rescaling, rendering the quantitative measures meaningless. In this paper we show that for deep networks with positively homogenous activations, these rescalings constitute equivalence relations, and that these equivalence relations induce a quotient manifold structure in the parameter space. Using this manifold structure and an appropriate metric, we propose a Hessian-based measure for flatness that is invariant to rescaling. We use this new measure to confirm the proposition that Large-Batch SGD minima are indeed sharper than Small-Batch SGD minima.
Automated software vulnerability detection with machine learning
Aug 02, 2018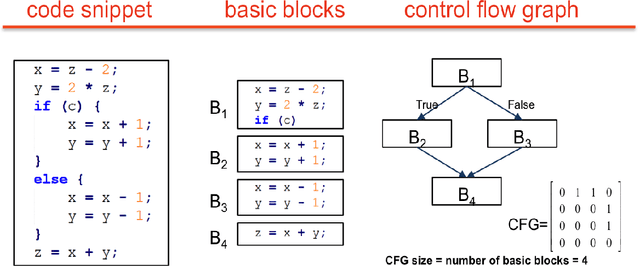
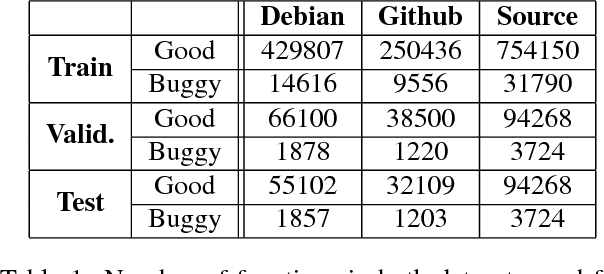
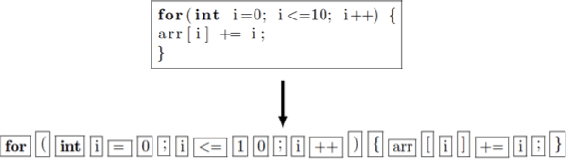
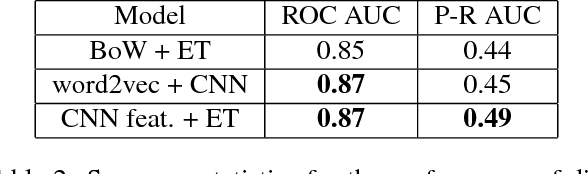
Thousands of security vulnerabilities are discovered in production software each year, either reported publicly to the Common Vulnerabilities and Exposures database or discovered internally in proprietary code. Vulnerabilities often manifest themselves in subtle ways that are not obvious to code reviewers or the developers themselves. With the wealth of open source code available for analysis, there is an opportunity to learn the patterns of bugs that can lead to security vulnerabilities directly from data. In this paper, we present a data-driven approach to vulnerability detection using machine learning, specifically applied to C and C++ programs. We first compile a large dataset of hundreds of thousands of open-source functions labeled with the outputs of a static analyzer. We then compare methods applied directly to source code with methods applied to artifacts extracted from the build process, finding that source-based models perform better. We also compare the application of deep neural network models with more traditional models such as random forests and find the best performance comes from combining features learned by deep models with tree-based models. Ultimately, our highest performing model achieves an area under the precision-recall curve of 0.49 and an area under the ROC curve of 0.87.
Sparse Coding and Autoencoders
Oct 20, 2017
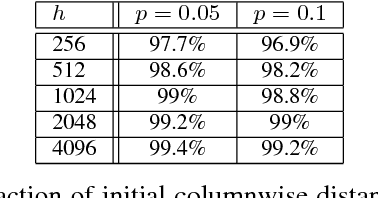
In "Dictionary Learning" one tries to recover incoherent matrices $A^* \in \mathbb{R}^{n \times h}$ (typically overcomplete and whose columns are assumed to be normalized) and sparse vectors $x^* \in \mathbb{R}^h$ with a small support of size $h^p$ for some $0 <p < 1$ while having access to observations $y \in \mathbb{R}^n$ where $y = A^*x^*$. In this work we undertake a rigorous analysis of whether gradient descent on the squared loss of an autoencoder can solve the dictionary learning problem. The "Autoencoder" architecture we consider is a $\mathbb{R}^n \rightarrow \mathbb{R}^n$ mapping with a single ReLU activation layer of size $h$. Under very mild distributional assumptions on $x^*$, we prove that the norm of the expected gradient of the standard squared loss function is asymptotically (in sparse code dimension) negligible for all points in a small neighborhood of $A^*$. This is supported with experimental evidence using synthetic data. We also conduct experiments to suggest that $A^*$ is a local minimum. Along the way we prove that a layer of ReLU gates can be set up to automatically recover the support of the sparse codes. This property holds independent of the loss function. We believe that it could be of independent interest.