 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sample Complexity of Learning for Blind Inverse Problems
Dec 29, 2025Blind inverse problems arise in many experimental settings where the forward operator is partially or entirely unknown. In this context, methods developed for the non-blind case cannot be adapted in a straightforward manner. Recently, data-driven approaches have been proposed to address blind inverse problems, demonstrating strong empirical performance and adaptability. However, these methods often lack interpretability and are not supported by rigorous theoretical guarantees, limiting their reliability in applied domains such as imaging inverse problems. In this work, we shed light on learning in blind inverse problems within the simplified yet insightful framework of Linear Minimum Mean Square Estimators (LMMSEs). We provide an in-depth theoretical analysis, deriving closed-form expressions for optimal estimators and extending classical results. In particular, we establish equivalences with suitably chosen Tikhonov-regularized formulations, where the regularization depends explicitly on the distributions of the unknown signal, the noise, and the random forward operators. We also prove convergence results under appropriate source condition assumptions. Furthermore, we derive rigorous finite-sample error bounds that characterize the performance of learned estimators as a function of the noise level, problem conditioning, and number of available samples. These bounds explicitly quantify the impact of operator randomness and reveal the associated convergence rates as this randomness vanishes. Finally, we validate our theoretical findings through illustrative numerical experiments that confirm the predicted convergence behavior.
A Structured Tour of Optimization with Finite Differences
May 26, 2025Finite-difference methods are widely used for zeroth-order optimization in settings where gradient information is unavailable or expensive to compute. These procedures mimic first-order strategies by approximating gradients through function evaluations along a set of random directions. From a theoretical perspective, recent studies indicate that imposing structure (such as orthogonality) on the chosen directions allows for the derivation of convergence rates comparable to those achieved with unstructured random directions (i.e., directions sampled independently from a distribution). Empirically, although structured directions are expected to enhance performance, they often introduce additional computational costs, which can limit their applicability in high-dimensional settings. In this work, we examine the impact of structured direction selection in finite-difference methods. We review and extend several strategies for constructing structured direction matrices and compare them with unstructured approaches in terms of computational cost, gradient approximation quality, and convergence behavior. Our evaluation spans both synthetic tasks and real-world applications such as adversarial perturbation. The results demonstrate that structured directions can be generated with computational costs comparable to unstructured ones while significantly improving gradient estimation accuracy and optimization performance.
Computational Efficiency under Covariate Shift in Kernel Ridge Regression
May 20, 2025This paper addresses the covariate shift problem in the context of nonparametric regression within reproducing kernel Hilbert spaces (RKHSs). Covariate shift arises in supervised learning when the input distributions of the training and test data differ, presenting additional challenges for learning. Although kernel methods have optimal statistical properties, their high computational demands in terms of time and, particularly, memory, limit their scalability to large datasets. To address this limitation, the main focus of this paper is to explore the trade-off between computational efficiency and statistical accuracy under covariate shift. We investigate the use of random projections where the hypothesis space consists of a random subspace within a given RKHS. Our results show that, even in the presence of covariate shift, significant computational savings can be achieved without compromising learning performance.
Towards a Learning Theory of Representation Alignment
Feb 19, 2025
It has recently been argued that AI models' representations are becoming aligned as their scale and performance increase. Empirical analyses have been designed to support this idea and conjecture the possible alignment of different representations toward a shared statistical model of reality. In this paper, we propose a learning-theoretic perspective to representation alignment. First, we review and connect different notions of alignment based on metric, probabilistic, and spectral ideas. Then, we focus on stitching, a particular approach to understanding the interplay between different representations in the context of a task. Our main contribution here is relating properties of stitching to the kernel alignment of the underlying representation. Our results can be seen as a first step toward casting representation alignment as a learning-theoretic problem.
Re-examining Double Descent and Scaling Laws under Norm-based Capacity via Deterministic Equivalence
Feb 03, 2025



We investigate double descent and scaling laws in terms of weights rather than the number of parameters. Specifically, we analyze linear and random features models using the deterministic equivalence approach from random matrix theory. We precisely characterize how the weights norm concentrate around deterministic quantities and elucidate the relationship between the expected test error and the norm-based capacity (complexity). Our results rigorously answer whether double descent exists under norm-based capacity and reshape the corresponding scaling laws. Moreover, they prompt a rethinking of the data-parameter paradigm - from under-parameterized to over-parameterized regimes - by shifting the focus to norms (weights) rather than parameter count.
Learning convolution operators on compact Abelian groups
Jan 09, 2025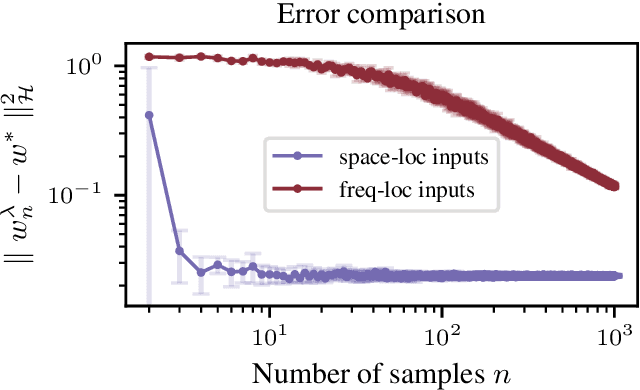
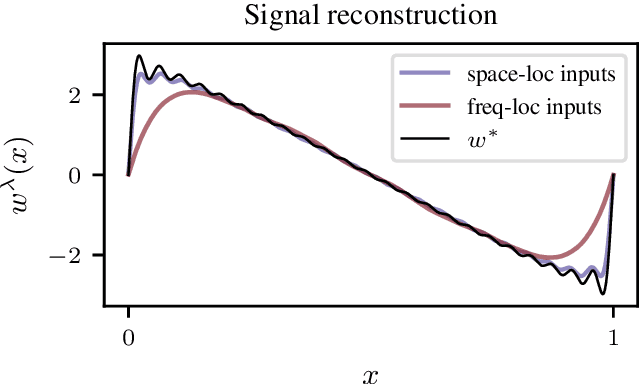
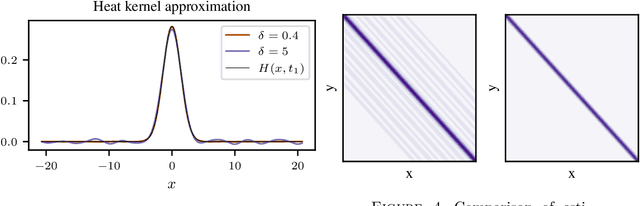
We consider the problem of learning convolution operators associated to compact Abelian groups. We study a regularization-based approach and provide corresponding learning guarantees, discussing natural regularity condition on the convolution kernel. More precisely, we assume the convolution kernel is a function in a translation invariant Hilbert space and analyze a natural ridge regression (RR) estimator. Building on existing results for RR, we characterize the accuracy of the estimator in terms of finite sample bounds. Interestingly, regularity assumptions which are classical in the analysis of RR, have a novel and natural interpretation in terms of space/frequency localization. Theoretical results are illustrated by numerical simulations.
Optimization Insights into Deep Diagonal Linear Networks
Dec 21, 2024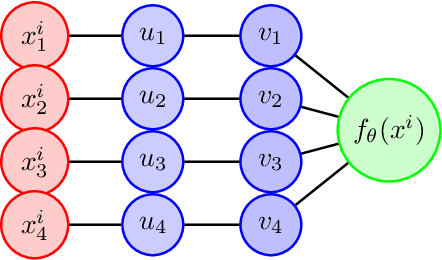
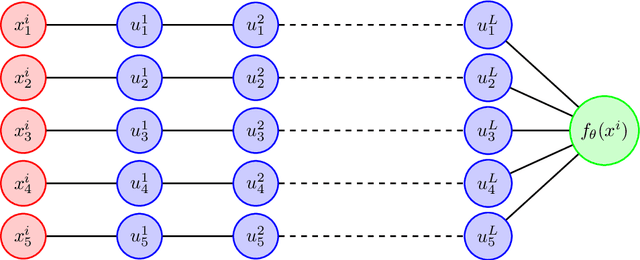
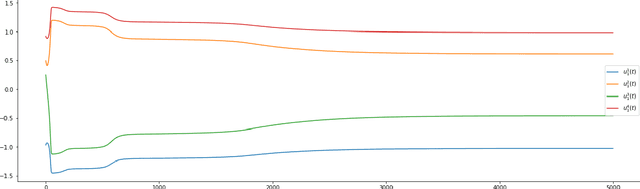
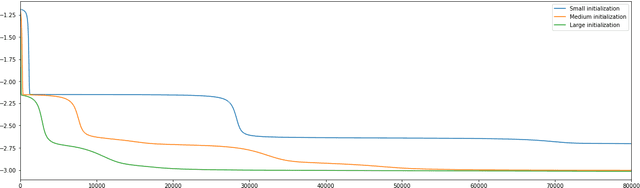
Overparameterized models trained with (stochastic) gradient descent are ubiquitous in modern machine learning. These large models achieve unprecedented performance on test data, but their theoretical understanding is still limited. In this paper, we take a step towards filling this gap by adopting an optimization perspective. More precisely, we study the implicit regularization properties of the gradient flow "algorithm" for estimating the parameters of a deep diagonal neural network. Our main contribution is showing that this gradient flow induces a mirror flow dynamic on the model, meaning that it is biased towards a specific solution of the problem depending on the initialization of the network. Along the way, we prove several properties of the trajectory.
Automatic Gain Tuning for Humanoid Robots Walking Architectures Using Gradient-Free Optimization Techniques
Sep 27, 2024



Developing sophisticated control architectures has endowed robots, particularly humanoid robots, with numerous capabilities. However, tuning these architectures remains a challenging and time-consuming task that requires expert intervention. In this work, we propose a methodology to automatically tune the gains of all layers of a hierarchical control architecture for walking humanoids. We tested our methodology by employing different gradient-free optimization methods: Genetic Algorithm (GA), Covariance Matrix Adaptation Evolution Strategy (CMA-ES), Evolution Strategy (ES), and Differential Evolution (DE). We validated the parameter found both in simulation and on the real ergoCub humanoid robot. Our results show that GA achieves the fastest convergence (10 x 10^3 function evaluations vs 25 x 10^3 needed by the other algorithms) and 100% success rate in completing the task both in simulation and when transferred on the real robotic platform. These findings highlight the potential of our proposed method to automate the tuning process, reducing the need for manual intervention.
Trust And Balance: Few Trusted Samples Pseudo-Labeling and Temperature Scaled Loss for Effective Source-Free Unsupervised Domain Adaptation
Sep 01, 2024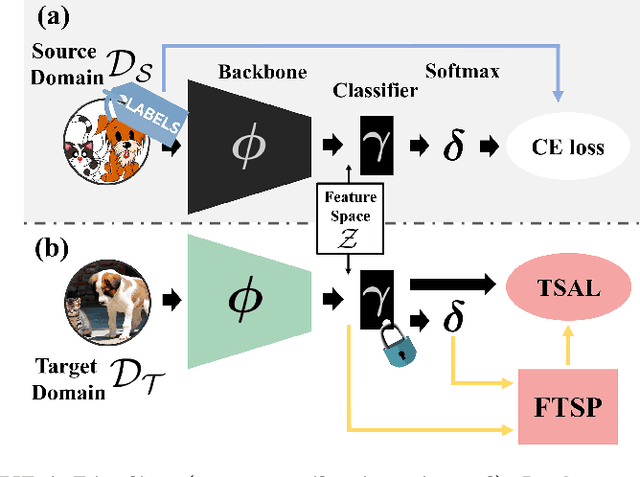
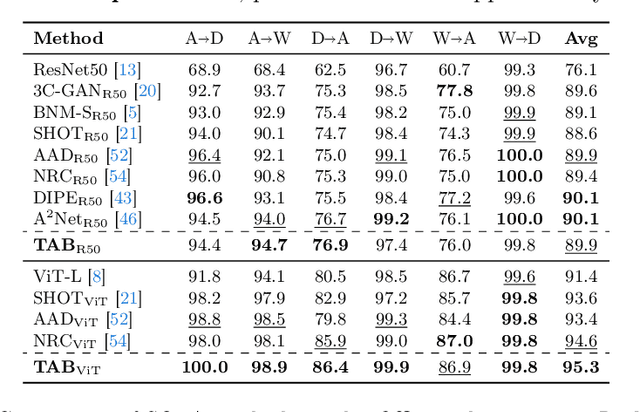
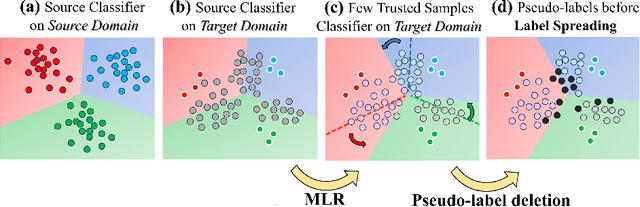
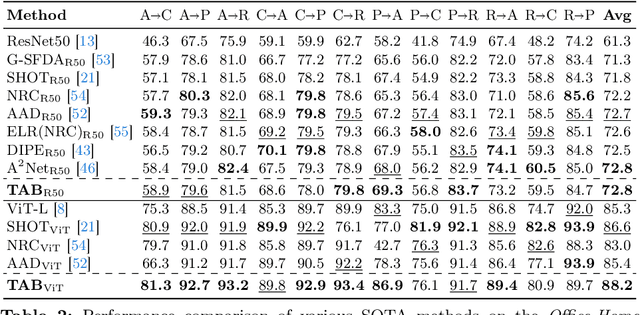
Deep Neural Networks have significantly impacted many computer vision tasks. However, their effectiveness diminishes when test data distribution (target domain) deviates from the one of training data (source domain). In situations where target labels are unavailable and the access to the labeled source domain is restricted due to data privacy or memory constraints, Source-Free Unsupervised Domain Adaptation (SF-UDA) has emerged as a valuable tool. Recognizing the key role of SF-UDA under these constraints, we introduce a novel approach marked by two key contributions: Few Trusted Samples Pseudo-labeling (FTSP) and Temperature Scaled Adaptive Loss (TSAL). FTSP employs a limited subset of trusted samples from the target data to construct a classifier to infer pseudo-labels for the entire domain, showing simplicity and improved accuracy. Simultaneously, TSAL, designed with a unique dual temperature scheduling, adeptly balance diversity, discriminability, and the incorporation of pseudo-labels in the unsupervised adaptation objective. Our methodology, that we name Trust And Balance (TAB) adaptation, is rigorously evaluated on standard datasets like Office31 and Office-Home, and on less common benchmarks such as ImageCLEF-DA and Adaptiope, employing both ResNet50 and ViT-Large architectures. Our results compare favorably with, and in most cases surpass, contemporary state-of-the-art techniques, underscoring the effectiveness of our methodology in the SF-UDA landscape.
A New Formulation for Zeroth-Order Optimization of Adversarial EXEmples in Malware Detection
May 23, 2024
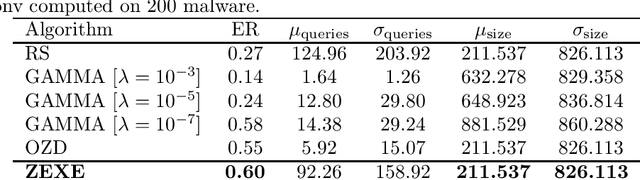
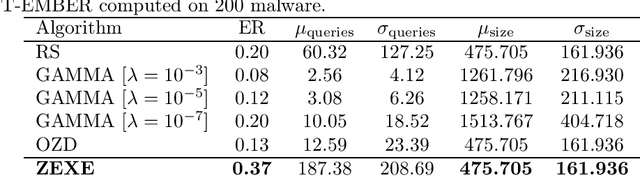
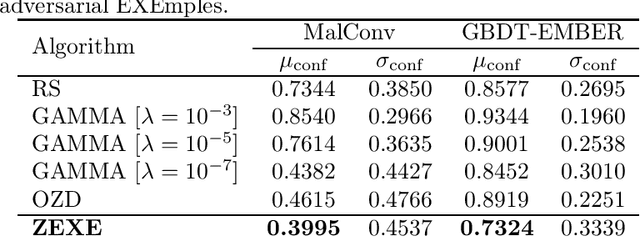
Machine learning malware detectors are vulnerable to adversarial EXEmples, i.e. carefully-crafted Windows programs tailored to evade detection. Unlike other adversarial problems, attacks in this context must be functionality-preserving, a constraint which is challenging to address. As a consequence heuristic algorithms are typically used, that inject new content, either randomly-picked or harvested from legitimate programs. In this paper, we show how learning malware detectors can be cast within a zeroth-order optimization framework which allows to incorporate functionality-preserving manipulations. This permits the deployment of sound and efficient gradient-free optimization algorithms, which come with theoretical guarantees and allow for minimal hyper-parameters tuning. As a by-product, we propose and study ZEXE, a novel zero-order attack against Windows malware detection. Compared to state-of-the-art techniques, ZEXE provides drastic improvement in the evasion rate, while reducing to less than one third the size of the injected content.