 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord2Minecraft: Generating 3D Game Levels through Large Language Models
Mar 18, 2025We present Word2Minecraft, a system that leverages large language models to generate playable game levels in Minecraft based on structured stories. The system transforms narrative elements-such as protagonist goals, antagonist challenges, and environmental settings-into game levels with both spatial and gameplay constraints. We introduce a flexible framework that allows for the customization of story complexity, enabling dynamic level generation. The system employs a scaling algorithm to maintain spatial consistency while adapting key game elements. We evaluate Word2Minecraft using both metric-based and human-based methods. Our results show that GPT-4-Turbo outperforms GPT-4o-Mini in most areas, including story coherence and objective enjoyment, while the latter excels in aesthetic appeal. We also demonstrate the system' s ability to generate levels with high map enjoyment, offering a promising step forward in the intersection of story generation and game design. We open-source the code at https://github.com/JMZ-kk/Word2Minecraft/tree/word2mc_v0
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Towards a Learning Theory of Representation Alignment
Feb 19, 2025
It has recently been argued that AI models' representations are becoming aligned as their scale and performance increase. Empirical analyses have been designed to support this idea and conjecture the possible alignment of different representations toward a shared statistical model of reality. In this paper, we propose a learning-theoretic perspective to representation alignment. First, we review and connect different notions of alignment based on metric, probabilistic, and spectral ideas. Then, we focus on stitching, a particular approach to understanding the interplay between different representations in the context of a task. Our main contribution here is relating properties of stitching to the kernel alignment of the underlying representation. Our results can be seen as a first step toward casting representation alignment as a learning-theoretic problem.
Spherical Analysis of Learning Nonlinear Functionals
Oct 01, 2024In recent years, there has been growing interest in the field of functional neural networks. They have been proposed and studied with the aim of approximating continuous functionals defined on sets of functions on Euclidean domains. In this paper, we consider functionals defined on sets of functions on spheres. The approximation ability of deep ReLU neural networks is investigated by novel spherical analysis using an encoder-decoder framework. An encoder comes up first to accommodate the infinite-dimensional nature of the domain of functionals. It utilizes spherical harmonics to help us extract the latent finite-dimensional information of functions, which in turn facilitates in the next step of approximation analysis using fully connected neural networks. Moreover, real-world objects are frequently sampled discretely and are often corrupted by noise. Therefore, encoders with discrete input and those with discrete and random noise input are constructed, respectively. The approximation rates with different encoder structures are provided therein.
ssProp: Energy-Efficient Training for Convolutional Neural Networks with Scheduled Sparse Back Propagation
Aug 22, 2024Recently, deep learning has made remarkable strides, especially with generative modeling, such as large language models and probabilistic diffusion models. However, training these models often involves significant computational resources, requiring billions of petaFLOPs. This high resource consumption results in substantial energy usage and a large carbon footprint, raising critical environmental concerns. Back-propagation (BP) is a major source of computational expense during training deep learning models. To advance research on energy-efficient training and allow for sparse learning on any machine and device, we propose a general, energy-efficient convolution module that can be seamlessly integrated into any deep learning architecture. Specifically, we introduce channel-wise sparsity with additional gradient selection schedulers during backward based on the assumption that BP is often dense and inefficient, which can lead to over-fitting and high computational consumption. Our experiments demonstrate that our approach reduces 40\% computations while potentially improving model performance, validated on image classification and generation tasks. This reduction can lead to significant energy savings and a lower carbon footprint during the research and development phases of large-scale AI systems. Additionally, our method mitigates over-fitting in a manner distinct from Dropout, allowing it to be combined with Dropout to further enhance model performance and reduce computational resource usage. Extensive experiments validate that our method generalizes to a variety of datasets and tasks and is compatible with a wide range of deep learning architectures and modules. Code is publicly available at https://github.com/lujiazho/ssProp.
PlacidDreamer: Advancing Harmony in Text-to-3D Generation
Jul 19, 2024Recently, text-to-3D generation has attracted significant attention, resulting in notable performance enhancements. Previous methods utilize end-to-end 3D generation models to initialize 3D Gaussians, multi-view diffusion models to enforce multi-view consistency, and text-to-image diffusion models to refine details with score distillation algorithms. However, these methods exhibit two limitations. Firstly, they encounter conflicts in generation directions since different models aim to produce diverse 3D assets. Secondly, the issue of over-saturation in score distillation has not been thoroughly investigated and solved. To address these limitations, we propose PlacidDreamer, a text-to-3D framework that harmonizes initialization, multi-view generation, and text-conditioned generation with a single multi-view diffusion model, while simultaneously employing a novel score distillation algorithm to achieve balanced saturation. To unify the generation direction, we introduce the Latent-Plane module, a training-friendly plug-in extension that enables multi-view diffusion models to provide fast geometry reconstruction for initialization and enhanced multi-view images to personalize the text-to-image diffusion model. To address the over-saturation problem, we propose to view score distillation as a multi-objective optimization problem and introduce the Balanced Score Distillation algorithm, which offers a Pareto Optimal solution that achieves both rich details and balanced saturation. Extensive experiments validate the outstanding capabilities of our PlacidDreamer. The code is available at \url{https://github.com/HansenHuang0823/PlacidDreamer}.
Diffusion Model-based FOD Restoration from High Distortion in dMRI
Jun 19, 2024



Fiber orientation distributions (FODs) is a popular model to represent the diffusion MRI (dMRI) data. However, imaging artifacts such as susceptibility-induced distortion in dMRI can cause signal loss and lead to the corrupted reconstruction of FODs, which prohibits successful fiber tracking and connectivity analysis in affected brain regions such as the brain stem. Generative models, such as the diffusion models, have been successfully applied in various image restoration tasks. However, their application on FOD images poses unique challenges since FODs are 4-dimensional data represented by spherical harmonics (SPHARM) with the 4-th dimension exhibiting order-related dependency. In this paper, we propose a novel diffusion model for FOD restoration that can recover the signal loss caused by distortion artifacts. We use volume-order encoding to enhance the ability of the diffusion model to generate individual FOD volumes at all SPHARM orders. Moreover, we add cross-attention features extracted across all SPHARM orders in generating every individual FOD volume to capture the order-related dependency across FOD volumes. We also condition the diffusion model with low-distortion FODs surrounding high-distortion areas to maintain the geometric coherence of the generated FODs. We trained and tested our model using data from the UK Biobank (n = 1315). On a test set with ground truth (n = 43), we demonstrate the high accuracy of the generated FODs in terms of root mean square errors of FOD volumes and angular errors of FOD peaks. We also apply our method to a test set with large distortion in the brain stem area (n = 1172) and demonstrate the efficacy of our method in restoring the FOD integrity and, hence, greatly improving tractography performance in affected brain regions.
Causal Discovery Inspired Unsupervised Domain Adaptation for Emotion-Cause Pair Extraction
Jun 18, 2024
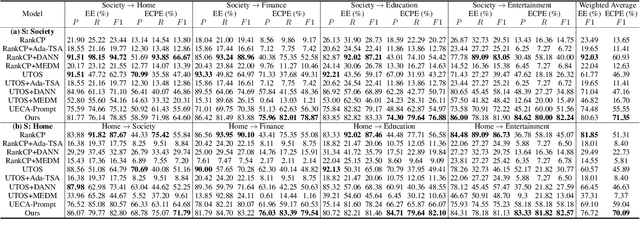
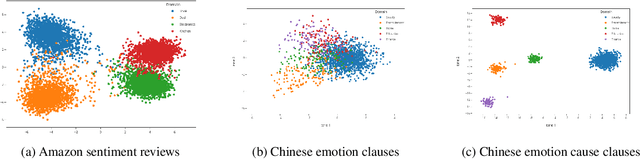
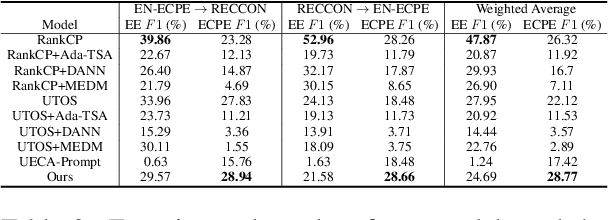
This paper tackles the task of emotion-cause pair extraction in the unsupervised domain adaptation setting. The problem is challenging as the distributions of the events causing emotions in target domains are dramatically different than those in source domains, despite the distributions of emotional expressions between domains are overlapped. Inspired by causal discovery, we propose a novel deep latent model in the variational autoencoder (VAE) framework, which not only captures the underlying latent structures of data but also utilizes the easily transferable knowledge of emotions as the bridge to link the distributions of events in different domains. To facilitate knowledge transfer across domains, we also propose a novel variational posterior regularization technique to disentangle the latent representations of emotions from those of events in order to mitigate the damage caused by the spurious correlations related to the events in source domains. Through extensive experiments, we demonstrate that our model outperforms the strongest baseline by approximately 11.05% on a Chinese benchmark and 2.45% on a English benchmark in terms of weighted-average F1 score. The source code will be publicly available upon acceptance.
NAP^2: A Benchmark for Naturalness and Privacy-Preserving Text Rewriting by Learning from Human
Jun 06, 2024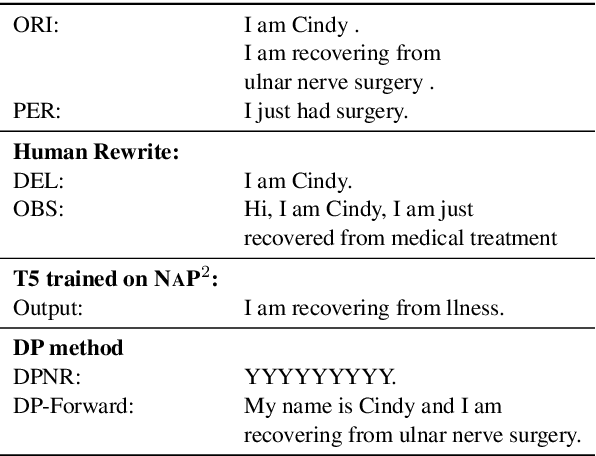
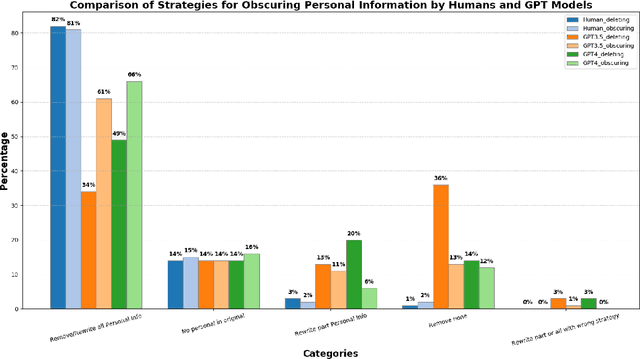
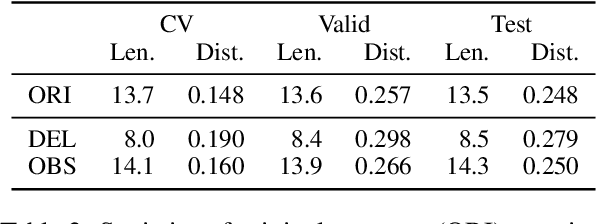
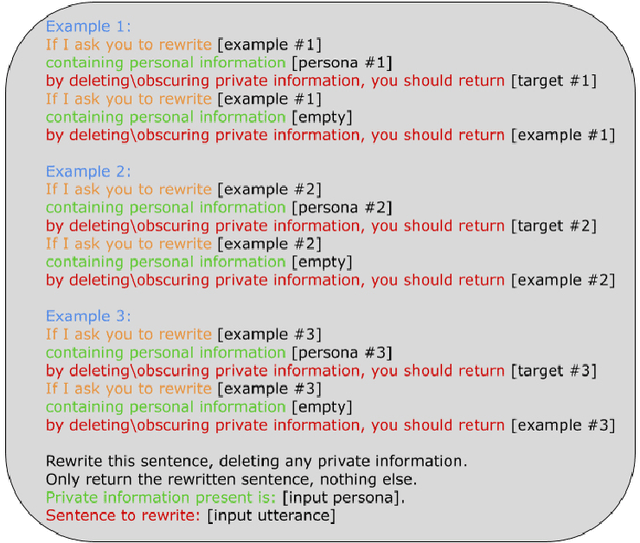
Increasing concerns about privacy leakage issues in academia and industry arise when employing NLP models from third-party providers to process sensitive texts. To protect privacy before sending sensitive data to those models, we suggest sanitizing sensitive text using two common strategies used by humans: i) deleting sensitive expressions, and ii) obscuring sensitive details by abstracting them. To explore the issues and develop a tool for text rewriting, we curate the first corpus, coined NAP^2, through both crowdsourcing and the use of large language models (LLMs). Compared to the prior works based on differential privacy, which lead to a sharp drop in information utility and unnatural texts, the human-inspired approaches result in more natural rewrites and offer an improved balance between privacy protection and data utility, as demonstrated by our extensive experiments.
TauAD: MRI-free Tau Anomaly Detection in PET Imaging via Conditioned Diffusion Models
May 21, 2024



The emergence of tau PET imaging over the last decade has enabled Alzheimer's disease (AD) researchers to examine tau pathology in vivo and more effectively characterize the disease trajectories of AD. Current tau PET analysis methods, however, typically perform inferences on large cortical ROIs and are limited in the detection of localized tau pathology that varies across subjects. Furthermore, a high-resolution MRI is required to carry out conventional tau PET analysis, which is not commonly acquired in clinical practices and may not be acquired for many elderly patients with dementia due to strong motion artifacts, claustrophobia, or certain metal implants. In this work, we propose a novel conditional diffusion model to perform MRI-free anomaly detection from tau PET imaging data. By including individualized conditions and two complementary loss maps from pseudo-healthy and pseudo-unhealthy reconstructions, our model computes an anomaly map across the entire brain area that allows simply training a support vector machine (SVM) for classifying disease severity. We train our model on ADNI subjects (n=534) and evaluate its performance on a separate dataset from the preclinical subjects of the A4 clinical trial (n=447). We demonstrate that our method outperforms baseline generative models and the conventional Z-score-based method in anomaly localization without mis-detecting off-target bindings in sub-cortical and out-of-brain areas. By classifying the A4 subjects according to their anomaly map using the SVM trained on ADNI data, we show that our method can successfully group preclinical subjects with significantly different cognitive functions, which further demonstrates the effectiveness of our method in capturing biologically relevant anomaly in tau PET imaging.