 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLePREC: Reasoning as Classification over Structured Factors for Assessing Relevance of Legal Issues
Apr 21, 2026More than half of the global population struggles to meet their civil justice needs due to limited legal resources. While Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, significant challenges remain even at the foundational step of legal issue identification. To investigate LLMs' capabilities in this task, we constructed a dataset from 769 real-world Malaysian Contract Act court cases, using GPT-4o to extract facts and generate candidate legal issues, annotated by senior legal experts, which reveals a critical limitation: while LLMs generate diverse issue candidates, their precision remains inadequate (GPT-4o achieves only 62%). To address this gap, we propose LePREC (Legal Professional-inspired Reasoning Elicitation and Classification), a neuro-symbolic framework combining neural generation with structured statistical reasoning. LePREC consists of: (1) a neuro component leverages LLMs to transform legal descriptions into question-answer pairs representing diverse analytical factors, and (2) a symbolic component applies sparse linear models over these discrete features, learning explicit algebraic weights that identify the most informative reasoning factors. Unlike end-to-end neural approaches, LePREC achieves interpretability through transparent feature weighting while maintaining data efficiency through correlation-based statistical classification. Experiments show a 30-40% improvement over advanced LLM baselines, including GPT-4o and Claude, confirming that correlation-based factor-issue analysis offers a more data-efficient solution for relevance decisions.
ACCESS : A Benchmark for Abstract Causal Event Discovery and Reasoning
Feb 12, 2025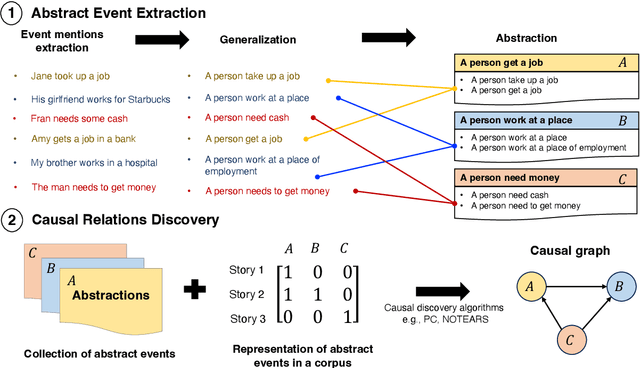

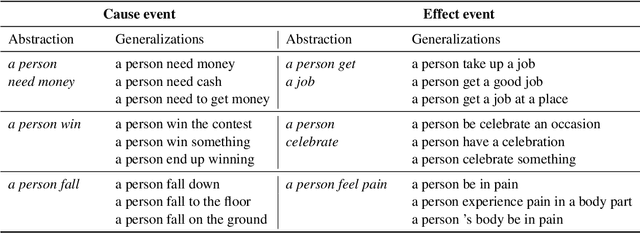
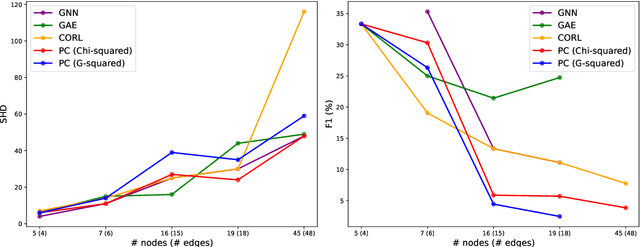
Identifying cause-and-effect relationships is critical to understanding real-world dynamics and ultimately causal reasoning. Existing methods for identifying event causality in NLP, including those based on Large Language Models (LLMs), exhibit difficulties in out-of-distribution settings due to the limited scale and heavy reliance on lexical cues within available benchmarks. Modern benchmarks, inspired by probabilistic causal inference, have attempted to construct causal graphs of events as a robust representation of causal knowledge, where \texttt{CRAB} \citep{romanou2023crab} is one such recent benchmark along this line. In this paper, we introduce \texttt{ACCESS}, a benchmark designed for discovery and reasoning over abstract causal events. Unlike existing resources, \texttt{ACCESS} focuses on causality of everyday life events on the abstraction level. We propose a pipeline for identifying abstractions for event generalizations from \texttt{GLUCOSE} \citep{mostafazadeh-etal-2020-glucose}, a large-scale dataset of implicit commonsense causal knowledge, from which we subsequently extract $1,4$K causal pairs. Our experiments highlight the ongoing challenges of using statistical methods and/or LLMs for automatic abstraction identification and causal discovery in NLP. Nonetheless, we demonstrate that the abstract causal knowledge provided in \texttt{ACCESS} can be leveraged for enhancing QA reasoning performance in LLMs.
From Pre-training Corpora to Large Language Models: What Factors Influence LLM Performance in Causal Discovery Tasks?
Jul 29, 2024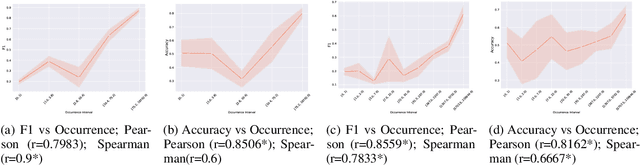
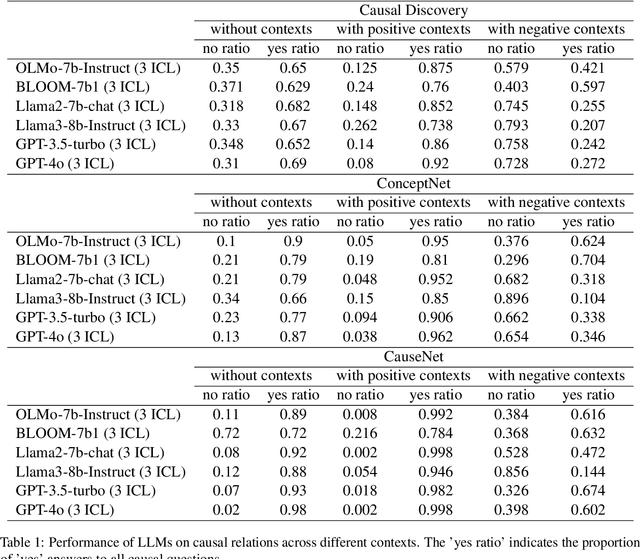
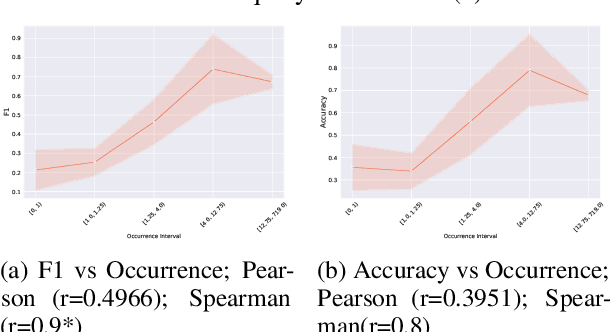
Recent advances in artificial intelligence have seen Large Language Models (LLMs) demonstrate notable proficiency in causal discovery tasks. This study explores the factors influencing the performance of LLMs in causal discovery tasks. Utilizing open-source LLMs, we examine how the frequency of causal relations within their pre-training corpora affects their ability to accurately respond to causal discovery queries. Our findings reveal that a higher frequency of causal mentions correlates with better model performance, suggesting that extensive exposure to causal information during training enhances the models' causal discovery capabilities. Additionally, we investigate the impact of context on the validity of causal relations. Our results indicate that LLMs might exhibit divergent predictions for identical causal relations when presented in different contexts. This paper provides the first comprehensive analysis of how different factors contribute to LLM performance in causal discovery tasks.
CausalScore: An Automatic Reference-Free Metric for Assessing Response Relevance in Open-Domain Dialogue Systems
Jun 25, 2024
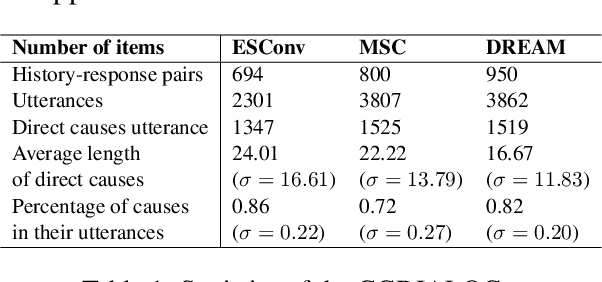
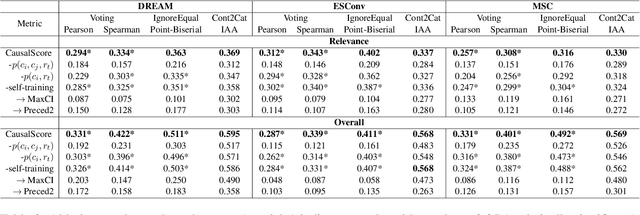
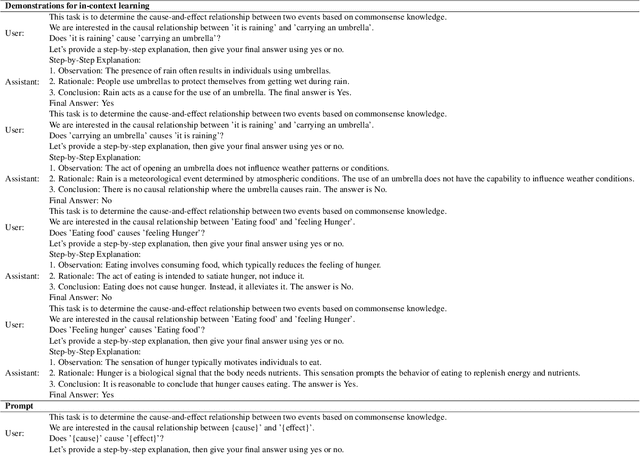
Automatically evaluating the quality of responses in open-domain dialogue systems is a challenging but crucial task. Current evaluation metrics often fail to align with human judgments, especially when assessing responses that are grammatically correct. To address this issue, we propose a novel metric, called CausalScore, which assesses the relevance of responses by measuring the causal strength between dialogue histories and responses. The causal strength is estimated by utilizing both unconditional dependence and conditional dependencies from the dialogue history to responses. We compare our metric with the existing competitive metrics in terms of their alignment with human judgements. Our experimental results demonstrate that CausalScore significantly surpasses existing state-of-the-art metrics by aligning better with human judgements. Additionally, we collect a new dialogue dataset CGDIALOG+ with human-annotated causal relations and a set of pairwise human judgements to facilitate the development of future automatic metrics.
Bridging Law and Data: Augmenting Reasoning via a Semi-Structured Dataset with IRAC methodology
Jun 19, 2024The effectiveness of Large Language Models (LLMs) in legal reasoning is often limited due to the unique legal terminologies and the necessity for highly specialized knowledge. These limitations highlight the need for high-quality data tailored for complex legal reasoning tasks. This paper introduces LEGALSEMI, a benchmark specifically curated for legal scenario analysis. LEGALSEMI comprises 54 legal scenarios, each rigorously annotated by legal experts, based on the comprehensive IRAC (Issue, Rule, Application, Conclusion) framework. In addition, LEGALSEMI is accompanied by a structured knowledge graph (SKG). A series of experiments were conducted to assess the usefulness of LEGALSEMI for IRAC analysis. The experimental results demonstrate the effectiveness of incorporating the SKG for issue identification, rule retrieval, application and conclusion generation using four different LLMs. LEGALSEMI will be publicly available upon acceptance of this paper.
NAP^2: A Benchmark for Naturalness and Privacy-Preserving Text Rewriting by Learning from Human
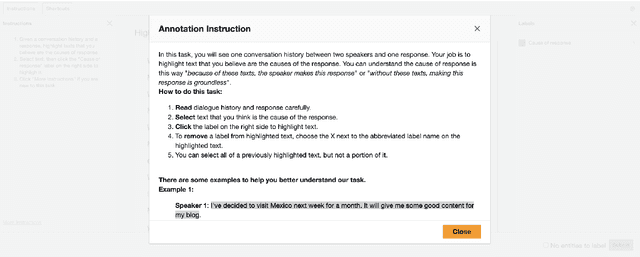
Jun 06, 2024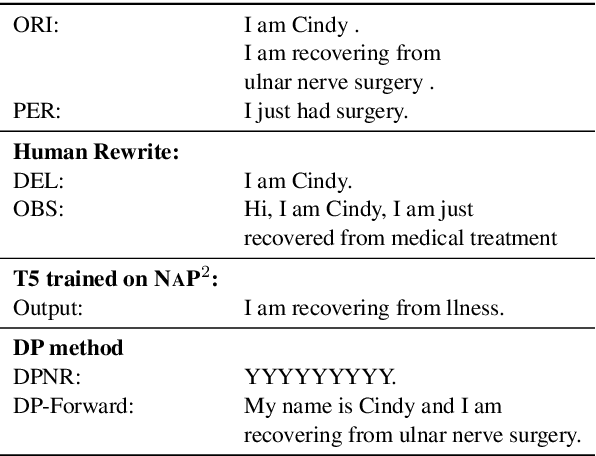
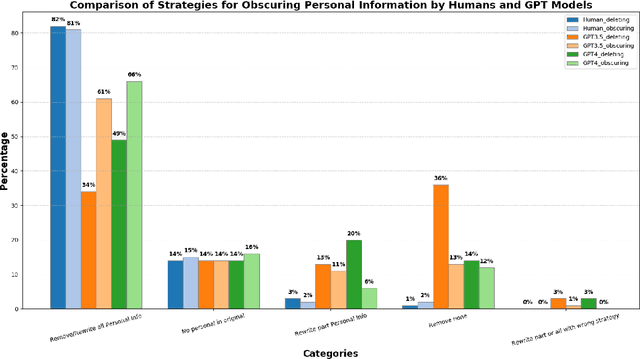
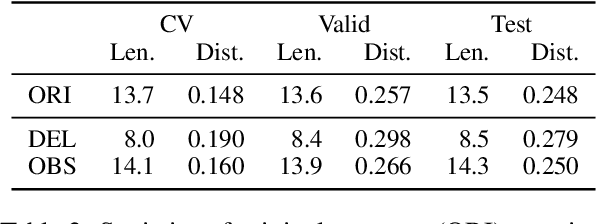
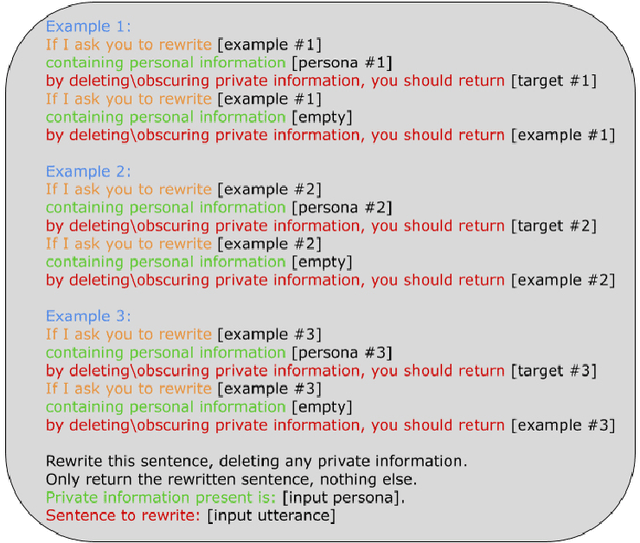
Increasing concerns about privacy leakage issues in academia and industry arise when employing NLP models from third-party providers to process sensitive texts. To protect privacy before sending sensitive data to those models, we suggest sanitizing sensitive text using two common strategies used by humans: i) deleting sensitive expressions, and ii) obscuring sensitive details by abstracting them. To explore the issues and develop a tool for text rewriting, we curate the first corpus, coined NAP^2, through both crowdsourcing and the use of large language models (LLMs). Compared to the prior works based on differential privacy, which lead to a sharp drop in information utility and unnatural texts, the human-inspired approaches result in more natural rewrites and offer an improved balance between privacy protection and data utility, as demonstrated by our extensive experiments.
RENOVI: A Benchmark Towards Remediating Norm Violations in Socio-Cultural Conversations
Feb 17, 2024



Norm violations occur when individuals fail to conform to culturally accepted behaviors, which may lead to potential conflicts. Remediating norm violations requires social awareness and cultural sensitivity of the nuances at play. To equip interactive AI systems with a remediation ability, we offer ReNoVi - a large-scale corpus of 9,258 multi-turn dialogues annotated with social norms, as well as define a sequence of tasks to help understand and remediate norm violations step by step. ReNoVi consists of two parts: 512 human-authored dialogues (real data), and 8,746 synthetic conversations generated by ChatGPT through prompt learning. While collecting sufficient human-authored data is costly, synthetic conversations provide suitable amounts of data to help mitigate the scarcity of training data, as well as the chance to assess the alignment between LLMs and humans in the awareness of social norms. We thus harness the power of ChatGPT to generate synthetic training data for our task. To ensure the quality of both human-authored and synthetic data, we follow a quality control protocol during data collection. Our experimental results demonstrate the importance of remediating norm violations in socio-cultural conversations, as well as the improvement in performance obtained from synthetic data.
Can ChatGPT Perform Reasoning Using the IRAC Method in Analyzing Legal Scenarios Like a Lawyer?
Nov 03, 2023



Large Language Models (LLMs), such as ChatGPT, have drawn a lot of attentions recently in the legal domain due to its emergent ability to tackle a variety of legal tasks. However, it is still unknown if LLMs are able to analyze a legal case and perform reasoning in the same manner as lawyers. Therefore, we constructed a novel corpus consisting of scenarios pertain to Contract Acts Malaysia and Australian Social Act for Dependent Child. ChatGPT is applied to perform analysis on the corpus using the IRAC method, which is a framework widely used by legal professionals for organizing legal analysis. Each scenario in the corpus is annotated with a complete IRAC analysis in a semi-structured format so that both machines and legal professionals are able to interpret and understand the annotations. In addition, we conducted the first empirical assessment of ChatGPT for IRAC analysis in order to understand how well it aligns with the analysis of legal professionals. Our experimental results shed lights on possible future research directions to improve alignments between LLMs and legal experts in terms of legal reasoning.
SocialDial: A Benchmark for Socially-Aware Dialogue Systems
Apr 24, 2023



Dialogue systems have been widely applied in many scenarios and are now more powerful and ubiquitous than ever before. With large neural models and massive available data, current dialogue systems have access to more knowledge than any people in their life. However, current dialogue systems still do not perform at a human level. One major gap between conversational agents and humans lies in their abilities to be aware of social norms. The development of socially-aware dialogue systems is impeded due to the lack of resources. In this paper, we present the first socially-aware dialogue corpus - SocialDial, based on Chinese social culture. SocialDial consists of two parts: 1,563 multi-turn dialogues between two human speakers with fine-grained labels, and 4,870 synthetic conversations generated by ChatGPT. The human corpus covers five categories of social norms, which have 14 sub-categories in total. Specifically, it contains social factor annotations including social relation, context, social distance, and social norms. However, collecting sufficient socially-aware dialogues is costly. Thus, we harness the power of ChatGPT and devise an ontology-based synthetic data generation framework. This framework is able to generate synthetic data at scale. To ensure the quality of synthetic dialogues, we design several mechanisms for quality control during data collection. Finally, we evaluate our dataset using several pre-trained models, such as BERT and RoBERTa. Comprehensive empirical results based on state-of-the-art neural models demonstrate that modeling of social norms for dialogue systems is a promising research direction. To the best of our knowledge, SocialDial is the first socially-aware dialogue dataset that covers multiple social factors and has fine-grained labels.