 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARD: Towards Conditional Design of Multi-agent Topological Structures
Mar 01, 2026Large language model (LLM)-based multi-agent systems have shown strong capabilities in tasks such as code generation and collaborative reasoning. However, the effectiveness and robustness of these systems critically depend on their communication topology, which is often fixed or statically learned, ignoring real-world dynamics such as model upgrades, API (or tool) changes, or knowledge source variability. To address this limitation, we propose CARD (Conditional Agentic Graph Designer), a conditional graph-generation framework that instantiates AMACP, a protocol for adaptive multi-agent communication. CARD explicitly incorporates dynamic environmental signals into graph construction, enabling topology adaptation at both training and runtime. Through a conditional variational graph encoder and environment-aware optimization, CARD produces communication structures that are both effective and resilient to shifts in model capability or resource availability. Empirical results on HumanEval, MATH, and MMLU demonstrate that CARD consistently outperforms static and prompt-based baselines, achieving higher accuracy and robustness across diverse conditions. The source code is available at: https://github.com/Warma10032/CARD.
Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
Aug 27, 2025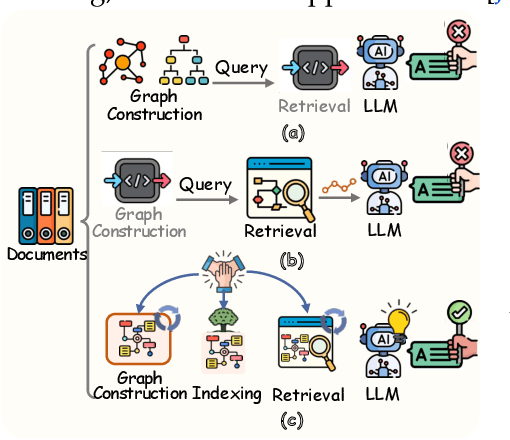
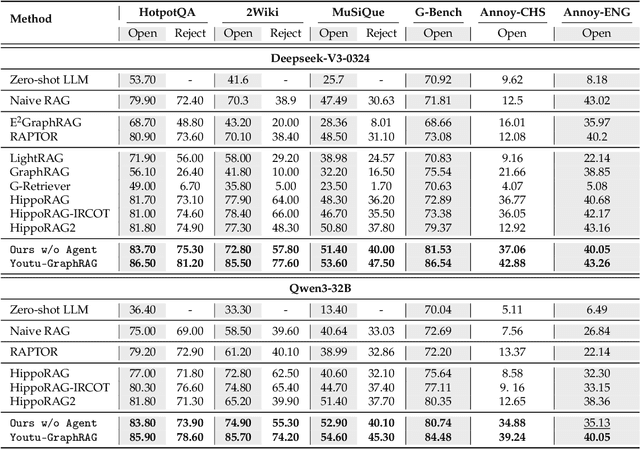

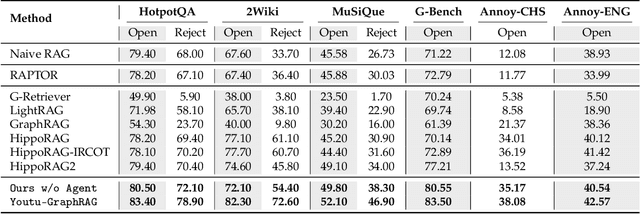
Graph retrieval-augmented generation (GraphRAG) has effectively enhanced large language models in complex reasoning by organizing fragmented knowledge into explicitly structured graphs. Prior efforts have been made to improve either graph construction or graph retrieval in isolation, yielding suboptimal performance, especially when domain shifts occur. In this paper, we propose a vertically unified agentic paradigm, Youtu-GraphRAG, to jointly connect the entire framework as an intricate integration. Specifically, (i) a seed graph schema is introduced to bound the automatic extraction agent with targeted entity types, relations and attribute types, also continuously expanded for scalability over unseen domains; (ii) To obtain higher-level knowledge upon the schema, we develop novel dually-perceived community detection, fusing structural topology with subgraph semantics for comprehensive knowledge organization. This naturally yields a hierarchical knowledge tree that supports both top-down filtering and bottom-up reasoning with community summaries; (iii) An agentic retriever is designed to interpret the same graph schema to transform complex queries into tractable and parallel sub-queries. It iteratively performs reflection for more advanced reasoning; (iv) To alleviate the knowledge leaking problem in pre-trained LLM, we propose a tailored anonymous dataset and a novel 'Anonymity Reversion' task that deeply measures the real performance of the GraphRAG frameworks. Extensive experiments across six challenging benchmarks demonstrate the robustness of Youtu-GraphRAG, remarkably moving the Pareto frontier with up to 90.71% saving of token costs and 16.62% higher accuracy over state-of-the-art baselines. The results indicate our adaptability, allowing seamless domain transfer with minimal intervention on schema.
SituatedThinker: Grounding LLM Reasoning with Real-World through Situated Thinking
May 25, 2025Recent advances in large language models (LLMs) demonstrate their impressive reasoning capabilities. However, the reasoning confined to internal parametric space limits LLMs' access to real-time information and understanding of the physical world. To overcome this constraint, we introduce SituatedThinker, a novel framework that enables LLMs to ground their reasoning in real-world contexts through situated thinking, which adaptively combines both internal knowledge and external information with predefined interfaces. By utilizing reinforcement learning, SituatedThinker incentivizes deliberate reasoning with the real world to acquire information and feedback, allowing LLMs to surpass their knowledge boundaries and enhance reasoning. Experimental results demonstrate significant performance improvements on multi-hop question-answering and mathematical reasoning benchmarks. Furthermore, SituatedThinker demonstrates strong performance on unseen tasks, such as KBQA, TableQA, and text-based games, showcasing the generalizable real-world grounded reasoning capability. Our codes are available at https://github.com/jnanliu/SituatedThinker.
Graph Retrieval-Augmented LLM for Conversational Recommendation Systems
Mar 09, 2025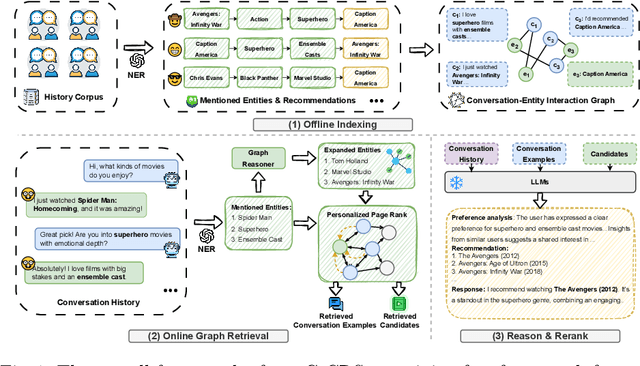
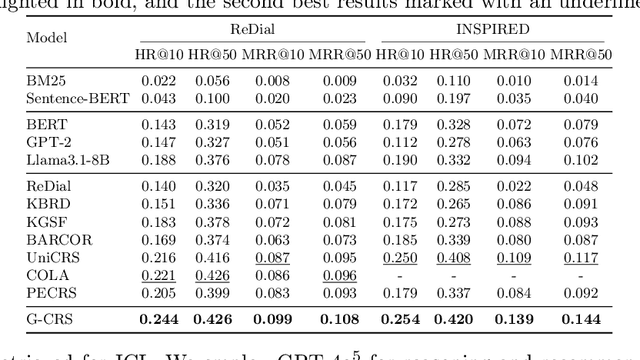
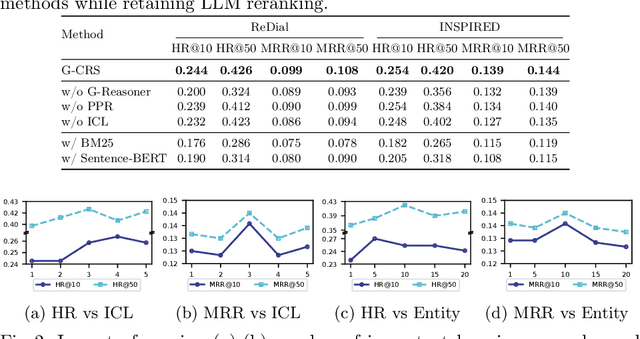
Conversational Recommender Systems (CRSs) have emerged as a transformative paradigm for offering personalized recommendations through natural language dialogue. However, they face challenges with knowledge sparsity, as users often provide brief, incomplete preference statements. While recent methods have integrated external knowledge sources to mitigate this, they still struggle with semantic understanding and complex preference reasoning. Recent Large Language Models (LLMs) demonstrate promising capabilities in natural language understanding and reasoning, showing significant potential for CRSs. Nevertheless, due to the lack of domain knowledge, existing LLM-based CRSs either produce hallucinated recommendations or demand expensive domain-specific training, which largely limits their applicability. In this work, we present G-CRS (Graph Retrieval-Augmented Large Language Model for Conversational Recommender Systems), a novel training-free framework that combines graph retrieval-augmented generation and in-context learning to enhance LLMs' recommendation capabilities. Specifically, G-CRS employs a two-stage retrieve-and-recommend architecture, where a GNN-based graph reasoner first identifies candidate items, followed by Personalized PageRank exploration to jointly discover potential items and similar user interactions. These retrieved contexts are then transformed into structured prompts for LLM reasoning, enabling contextually grounded recommendations without task-specific training. Extensive experiments on two public datasets show that G-CRS achieves superior recommendation performance compared to existing methods without requiring task-specific training.
G-Refer: Graph Retrieval-Augmented Large Language Model for Explainable Recommendation
Feb 18, 2025Explainable recommendation has demonstrated significant advantages in informing users about the logic behind recommendations, thereby increasing system transparency, effectiveness, and trustworthiness. To provide personalized and interpretable explanations, existing works often combine the generation capabilities of large language models (LLMs) with collaborative filtering (CF) information. CF information extracted from the user-item interaction graph captures the user behaviors and preferences, which is crucial for providing informative explanations. However, due to the complexity of graph structure, effectively extracting the CF information from graphs still remains a challenge. Moreover, existing methods often struggle with the integration of extracted CF information with LLMs due to its implicit representation and the modality gap between graph structures and natural language explanations. To address these challenges, we propose G-Refer, a framework using graph retrieval-augmented large language models (LLMs) for explainable recommendation. Specifically, we first employ a hybrid graph retrieval mechanism to retrieve explicit CF signals from both structural and semantic perspectives. The retrieved CF information is explicitly formulated as human-understandable text by the proposed graph translation and accounts for the explanations generated by LLMs. To bridge the modality gap, we introduce knowledge pruning and retrieval-augmented fine-tuning to enhance the ability of LLMs to process and utilize the retrieved CF information to generate explanations. Extensive experiments show that G-Refer achieves superior performance compared with existing methods in both explainability and stability. Codes and data are available at https://github.com/Yuhan1i/G-Refer.
GFM-RAG: Graph Foundation Model for Retrieval Augmented Generation
Feb 03, 2025



Retrieval-augmented generation (RAG) has proven effective in integrating knowledge into large language models (LLMs). However, conventional RAGs struggle to capture complex relationships between pieces of knowledge, limiting their performance in intricate reasoning that requires integrating knowledge from multiple sources. Recently, graph-enhanced retrieval augmented generation (GraphRAG) builds graph structure to explicitly model these relationships, enabling more effective and efficient retrievers. Nevertheless, its performance is still hindered by the noise and incompleteness within the graph structure. To address this, we introduce GFM-RAG, a novel graph foundation model (GFM) for retrieval augmented generation. GFM-RAG is powered by an innovative graph neural network that reasons over graph structure to capture complex query-knowledge relationships. The GFM with 8M parameters undergoes a two-stage training process on large-scale datasets, comprising 60 knowledge graphs with over 14M triples and 700k documents. This results in impressive performance and generalizability for GFM-RAG, making it the first graph foundation model applicable to unseen datasets for retrieval without any fine-tuning required. Extensive experiments on three multi-hop QA datasets and seven domain-specific RAG datasets demonstrate that GFM-RAG achieves state-of-the-art performance while maintaining efficiency and alignment with neural scaling laws, highlighting its potential for further improvement.
Unveiling User Preferences: A Knowledge Graph and LLM-Driven Approach for Conversational Recommendation
Nov 16, 2024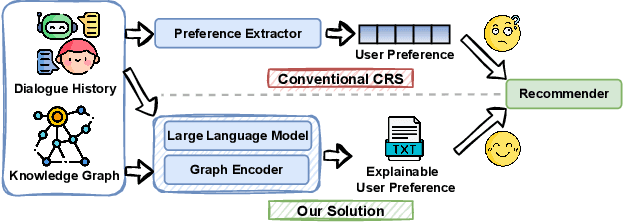
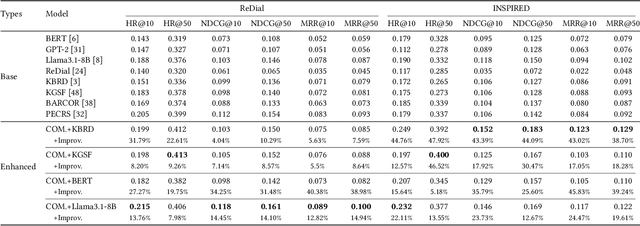
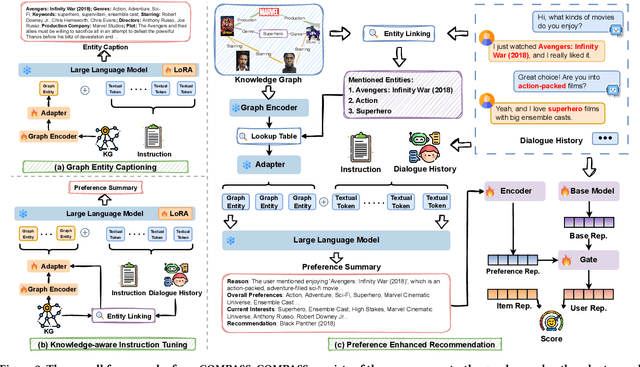
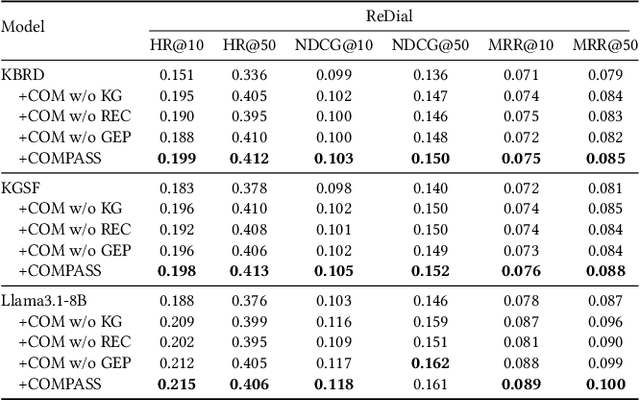
Conversational Recommender Systems (CRSs) aim to provide personalized recommendations through dynamically capturing user preferences in interactive conversations. Conventional CRSs often extract user preferences as hidden representations, which are criticized for their lack of interpretability. This diminishes the transparency and trustworthiness of the recommendation process. Recent works have explored combining the impressive capabilities of Large Language Models (LLMs) with the domain-specific knowledge of Knowledge Graphs (KGs) to generate human-understandable recommendation explanations. Despite these efforts, the integration of LLMs and KGs for CRSs remains challenging due to the modality gap between unstructured dialogues and structured KGs. Moreover, LLMs pre-trained on large-scale corpora may not be well-suited for analyzing user preferences, which require domain-specific knowledge. In this paper, we propose COMPASS, a plug-and-play framework that synergizes LLMs and KGs to unveil user preferences, enhancing the performance and explainability of existing CRSs. To address integration challenges, COMPASS employs a two-stage training approach: first, it bridges the gap between the structured KG and natural language through an innovative graph entity captioning pre-training mechanism. This enables the LLM to transform KG entities into concise natural language descriptions, allowing them to comprehend domain-specific knowledge. Following, COMPASS optimizes user preference modeling via knowledge-aware instruction fine-tuning, where the LLM learns to reason and summarize user preferences from both dialogue histories and KG-augmented context. This enables COMPASS to perform knowledge-aware reasoning and generate comprehensive and interpretable user preferences that can seamlessly integrate with existing CRS models for improving recommendation performance and explainability.
Graph-constrained Reasoning: Faithful Reasoning on Knowledge Graphs with Large Language Models
Oct 16, 2024



Large language models (LLMs) have demonstrated impressive reasoning abilities, but they still struggle with faithful reasoning due to knowledge gaps and hallucinations. To address these issues, knowledge graphs (KGs) have been utilized to enhance LLM reasoning through their structured knowledge. However, existing KG-enhanced methods, either retrieval-based or agent-based, encounter difficulties in accurately retrieving knowledge and efficiently traversing KGs at scale. In this work, we introduce graph-constrained reasoning (GCR), a novel framework that bridges structured knowledge in KGs with unstructured reasoning in LLMs. To eliminate hallucinations, GCR ensures faithful KG-grounded reasoning by integrating KG structure into the LLM decoding process through KG-Trie, a trie-based index that encodes KG reasoning paths. KG-Trie constrains the decoding process, allowing LLMs to directly reason on graphs and generate faithful reasoning paths grounded in KGs. Additionally, GCR leverages a lightweight KG-specialized LLM for graph-constrained reasoning alongside a powerful general LLM for inductive reasoning over multiple reasoning paths, resulting in accurate reasoning with zero reasoning hallucination. Extensive experiments on several KGQA benchmarks demonstrate that GCR achieves state-of-the-art performance and exhibits strong zero-shot generalizability to unseen KGs without additional training.
Scalable Frame-based Construction of Sociocultural NormBases for Socially-Aware Dialogues
Oct 04, 2024


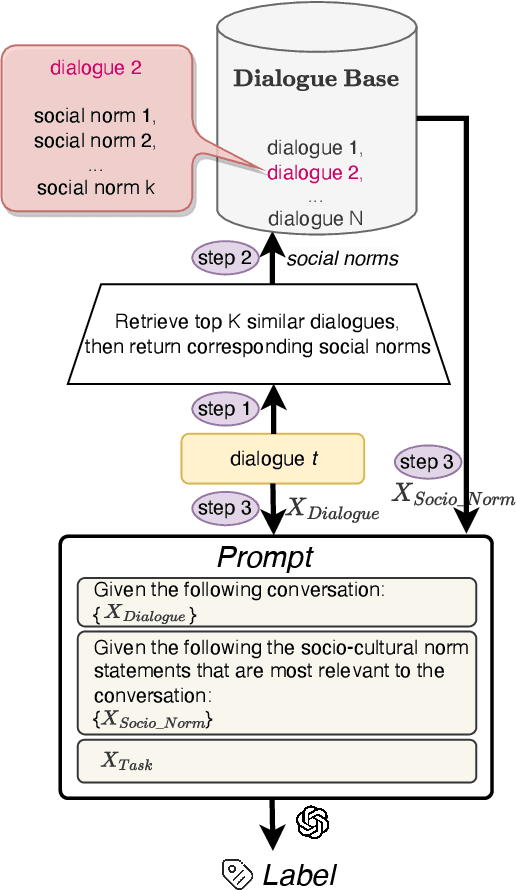
Sociocultural norms serve as guiding principles for personal conduct in social interactions, emphasizing respect, cooperation, and appropriate behavior, which is able to benefit tasks including conversational information retrieval, contextual information retrieval and retrieval-enhanced machine learning. We propose a scalable approach for constructing a Sociocultural Norm (SCN) Base using Large Language Models (LLMs) for socially aware dialogues. We construct a comprehensive and publicly accessible Chinese Sociocultural NormBase. Our approach utilizes socially aware dialogues, enriched with contextual frames, as the primary data source to constrain the generating process and reduce the hallucinations. This enables extracting of high-quality and nuanced natural-language norm statements, leveraging the pragmatic implications of utterances with respect to the situation. As real dialogue annotated with gold frames are not readily available, we propose using synthetic data. Our empirical results show: (i) the quality of the SCNs derived from synthetic data is comparable to that from real dialogues annotated with gold frames, and (ii) the quality of the SCNs extracted from real data, annotated with either silver (predicted) or gold frames, surpasses that without the frame annotations. We further show the effectiveness of the extracted SCNs in a RAG-based (Retrieval-Augmented Generation) model to reason about multiple downstream dialogue tasks.
* 17 pages
Graph Stochastic Neural Process for Inductive Few-shot Knowledge Graph Completion
Aug 03, 2024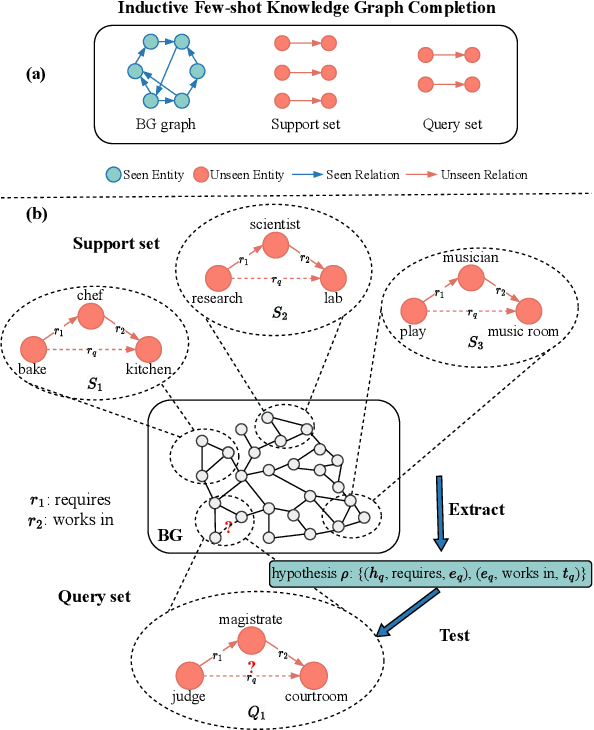
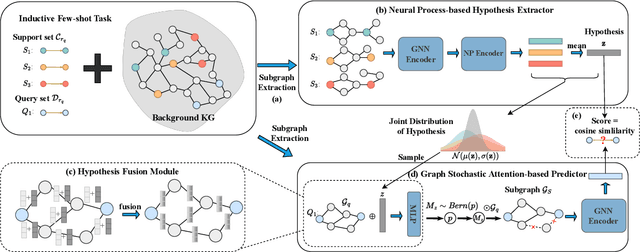
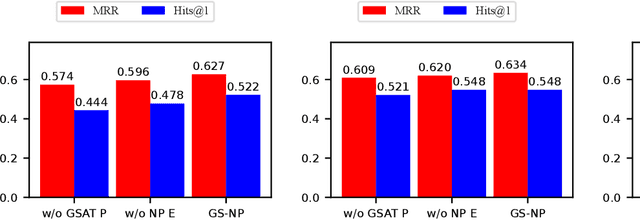
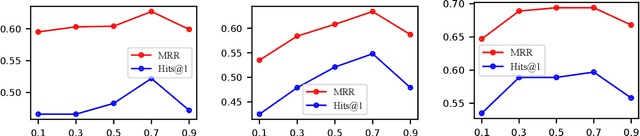
Knowledge graphs (KGs) store enormous facts as relationships between entities. Due to the long-tailed distribution of relations and the incompleteness of KGs, there is growing interest in few-shot knowledge graph completion (FKGC). Existing FKGC methods often assume the existence of all entities in KGs, which may not be practical since new relations and entities can emerge over time. Therefore, we focus on a more challenging task called inductive few-shot knowledge graph completion (I-FKGC), where both relations and entities during the test phase are unknown before. Inspired by the idea of inductive reasoning, we cast I-FKGC as an inductive reasoning problem. Specifically, we propose a novel Graph Stochastic Neural Process approach (GS-NP), which consists of two major modules. In the first module, to obtain a generalized hypothesis (e.g., shared subgraph), we present a neural process-based hypothesis extractor that models the joint distribution of hypothesis, from which we can sample a hypothesis for predictions. In the second module, based on the hypothesis, we propose a graph stochastic attention-based predictor to test if the triple in the query set aligns with the extracted hypothesis. Meanwhile, the predictor can generate an explanatory subgraph identified by the hypothesis. Finally, the training of these two modules is seamlessly combined into a unified objective function, of which the effectiveness is verified by theoretical analyses as well as empirical studies. Extensive experiments on three public datasets demonstrate that our method outperforms existing methods and derives new state-of-the-art performance.