 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumosX: Relate Any Identities with Their Attributes for Personalized Video Generation
Mar 20, 2026Recent advances in diffusion models have significantly improved text-to-video generation, enabling personalized content creation with fine-grained control over both foreground and background elements. However, precise face-attribute alignment across subjects remains challenging, as existing methods lack explicit mechanisms to ensure intra-group consistency. Addressing this gap requires both explicit modeling strategies and face-attribute-aware data resources. We therefore propose LumosX, a framework that advances both data and model design. On the data side, a tailored collection pipeline orchestrates captions and visual cues from independent videos, while multimodal large language models (MLLMs) infer and assign subject-specific dependencies. These extracted relational priors impose a finer-grained structure that amplifies the expressive control of personalized video generation and enables the construction of a comprehensive benchmark. On the modeling side, Relational Self-Attention and Relational Cross-Attention intertwine position-aware embeddings with refined attention dynamics to inscribe explicit subject-attribute dependencies, enforcing disciplined intra-group cohesion and amplifying the separation between distinct subject clusters. Comprehensive evaluations on our benchmark demonstrate that LumosX achieves state-of-the-art performance in fine-grained, identity-consistent, and semantically aligned personalized multi-subject video generation. Code and models are available at https://jiazheng-xing.github.io/lumosx-home/.
RealisID: Scale-Robust and Fine-Controllable Identity Customization via Local and Global Complementation
Dec 22, 2024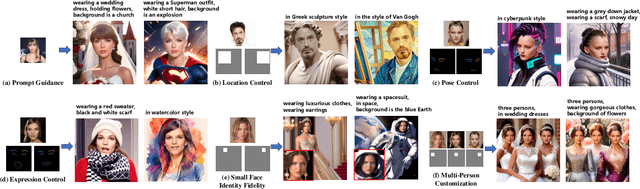
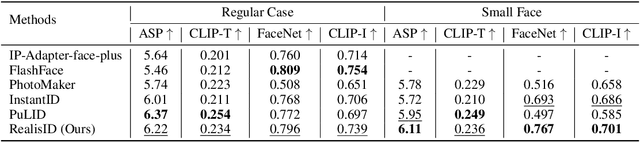
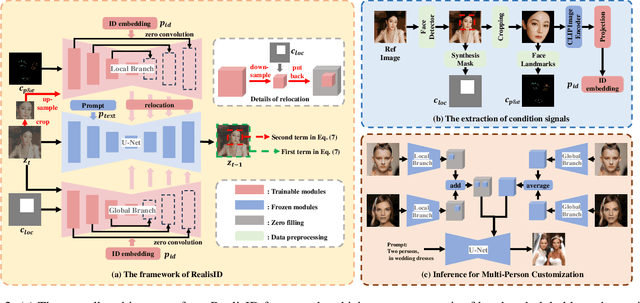
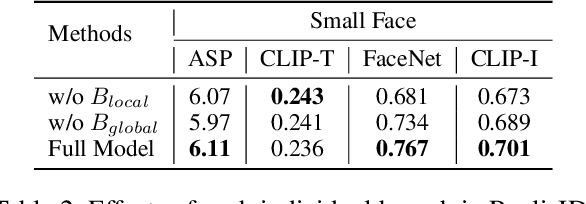
Recently, the success of text-to-image synthesis has greatly advanced the development of identity customization techniques, whose main goal is to produce realistic identity-specific photographs based on text prompts and reference face images. However, it is difficult for existing identity customization methods to simultaneously meet the various requirements of different real-world applications, including the identity fidelity of small face, the control of face location, pose and expression, as well as the customization of multiple persons. To this end, we propose a scale-robust and fine-controllable method, namely RealisID, which learns different control capabilities through the cooperation between a pair of local and global branches. Specifically, by using cropping and up-sampling operations to filter out face-irrelevant information, the local branch concentrates the fine control of facial details and the scale-robust identity fidelity within the face region. Meanwhile, the global branch manages the overall harmony of the entire image. It also controls the face location by taking the location guidance as input. As a result, RealisID can benefit from the complementarity of these two branches. Finally, by implementing our branches with two different variants of ControlNet, our method can be easily extended to handle multi-person customization, even only trained on single-person datasets. Extensive experiments and ablation studies indicate the effectiveness of RealisID and verify its ability in fulfilling all the requirements mentioned above.
SHMT: Self-supervised Hierarchical Makeup Transfer via Latent Diffusion Models
Dec 15, 2024



This paper studies the challenging task of makeup transfer, which aims to apply diverse makeup styles precisely and naturally to a given facial image. Due to the absence of paired data, current methods typically synthesize sub-optimal pseudo ground truths to guide the model training, resulting in low makeup fidelity. Additionally, different makeup styles generally have varying effects on the person face, but existing methods struggle to deal with this diversity. To address these issues, we propose a novel Self-supervised Hierarchical Makeup Transfer (SHMT) method via latent diffusion models. Following a "decoupling-and-reconstruction" paradigm, SHMT works in a self-supervised manner, freeing itself from the misguidance of imprecise pseudo-paired data. Furthermore, to accommodate a variety of makeup styles, hierarchical texture details are decomposed via a Laplacian pyramid and selectively introduced to the content representation. Finally, we design a novel Iterative Dual Alignment (IDA) module that dynamically adjusts the injection condition of the diffusion model, allowing the alignment errors caused by the domain gap between content and makeup representations to be corrected. Extensive quantitative and qualitative analyses demonstrate the effectiveness of our method. Our code is available at \url{https://github.com/Snowfallingplum/SHMT}.
LLM-Powered Explanations: Unraveling Recommendations Through Subgraph Reasoning
Jun 22, 2024



Recommender systems are pivotal in enhancing user experiences across various web applications by analyzing the complicated relationships between users and items. Knowledge graphs(KGs) have been widely used to enhance the performance of recommender systems. However, KGs are known to be noisy and incomplete, which are hard to provide reliable explanations for recommendation results. An explainable recommender system is crucial for the product development and subsequent decision-making. To address these challenges, we introduce a novel recommender that synergies Large Language Models (LLMs) and KGs to enhance the recommendation and provide interpretable results. Specifically, we first harness the power of LLMs to augment KG reconstruction. LLMs comprehend and decompose user reviews into new triples that are added into KG. In this way, we can enrich KGs with explainable paths that express user preferences. To enhance the recommendation on augmented KGs, we introduce a novel subgraph reasoning module that effectively measures the importance of nodes and discovers reasoning for recommendation. Finally, these reasoning paths are fed into the LLMs to generate interpretable explanations of the recommendation results. Our approach significantly enhances both the effectiveness and interpretability of recommender systems, especially in cross-selling scenarios where traditional methods falter. The effectiveness of our approach has been rigorously tested on four open real-world datasets, with our methods demonstrating a superior performance over contemporary state-of-the-art techniques by an average improvement of 12%. The application of our model in a multinational engineering and technology company cross-selling recommendation system further underscores its practical utility and potential to redefine recommendation practices through improved accuracy and user trust.
Data Pruning via Moving-one-Sample-out
Oct 25, 2023In this paper, we propose a novel data-pruning approach called moving-one-sample-out (MoSo), which aims to identify and remove the least informative samples from the training set. The core insight behind MoSo is to determine the importance of each sample by assessing its impact on the optimal empirical risk. This is achieved by measuring the extent to which the empirical risk changes when a particular sample is excluded from the training set. Instead of using the computationally expensive leaving-one-out-retraining procedure, we propose an efficient first-order approximator that only requires gradient information from different training stages. The key idea behind our approximation is that samples with gradients that are consistently aligned with the average gradient of the training set are more informative and should receive higher scores, which could be intuitively understood as follows: if the gradient from a specific sample is consistent with the average gradient vector, it implies that optimizing the network using the sample will yield a similar effect on all remaining samples. Experimental results demonstrate that MoSo effectively mitigates severe performance degradation at high pruning ratios and achieves satisfactory performance across various settings.
SwinRDM: Integrate SwinRNN with Diffusion Model towards High-Resolution and High-Quality Weather Forecasting
Jun 05, 2023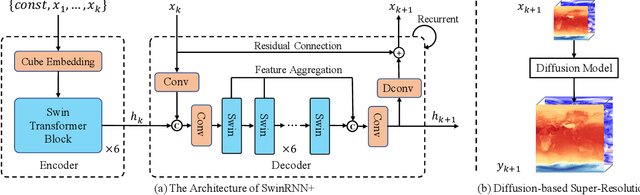

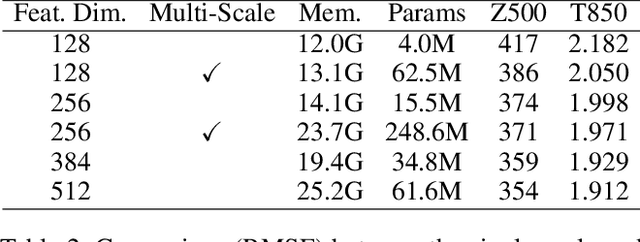
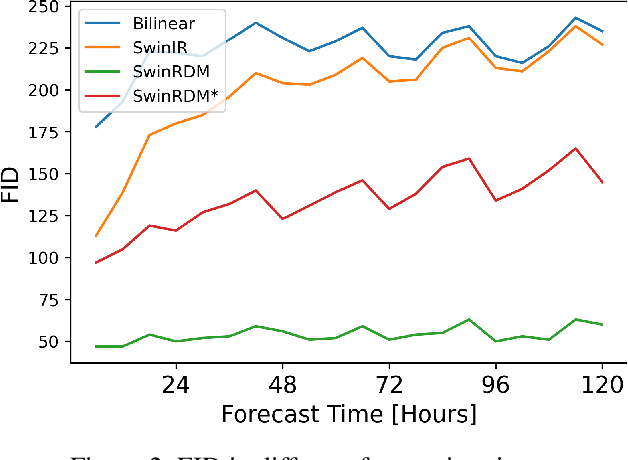
Data-driven medium-range weather forecasting has attracted much attention in recent years. However, the forecasting accuracy at high resolution is unsatisfactory currently. Pursuing high-resolution and high-quality weather forecasting, we develop a data-driven model SwinRDM which integrates an improved version of SwinRNN with a diffusion model. SwinRDM performs predictions at 0.25-degree resolution and achieves superior forecasting accuracy to IFS (Integrated Forecast System), the state-of-the-art operational NWP model, on representative atmospheric variables including 500 hPa geopotential (Z500), 850 hPa temperature (T850), 2-m temperature (T2M), and total precipitation (TP), at lead times of up to 5 days. We propose to leverage a two-step strategy to achieve high-resolution predictions at 0.25-degree considering the trade-off between computation memory and forecasting accuracy. Recurrent predictions for future atmospheric fields are firstly performed at 1.40625-degree resolution, and then a diffusion-based super-resolution model is leveraged to recover the high spatial resolution and finer-scale atmospheric details. SwinRDM pushes forward the performance and potential of data-driven models for a large margin towards operational applications.
Global and Local Mixture Consistency Cumulative Learning for Long-tailed Visual Recognitions
May 15, 2023



In this paper, our goal is to design a simple learning paradigm for long-tail visual recognition, which not only improves the robustness of the feature extractor but also alleviates the bias of the classifier towards head classes while reducing the training skills and overhead. We propose an efficient one-stage training strategy for long-tailed visual recognition called Global and Local Mixture Consistency cumulative learning (GLMC). Our core ideas are twofold: (1) a global and local mixture consistency loss improves the robustness of the feature extractor. Specifically, we generate two augmented batches by the global MixUp and local CutMix from the same batch data, respectively, and then use cosine similarity to minimize the difference. (2) A cumulative head tail soft label reweighted loss mitigates the head class bias problem. We use empirical class frequencies to reweight the mixed label of the head-tail class for long-tailed data and then balance the conventional loss and the rebalanced loss with a coefficient accumulated by epochs. Our approach achieves state-of-the-art accuracy on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT datasets. Additional experiments on balanced ImageNet and CIFAR demonstrate that GLMC can significantly improve the generalization of backbones. Code is made publicly available at https://github.com/ynu-yangpeng/GLMC.
FAKD: Feature Augmented Knowledge Distillation for Semantic Segmentation
Aug 30, 2022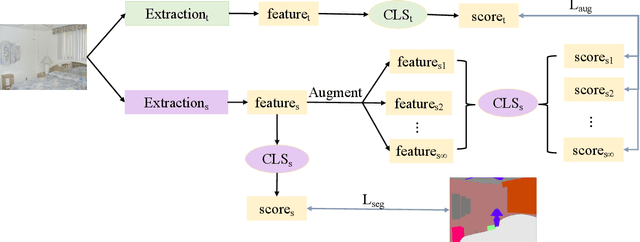
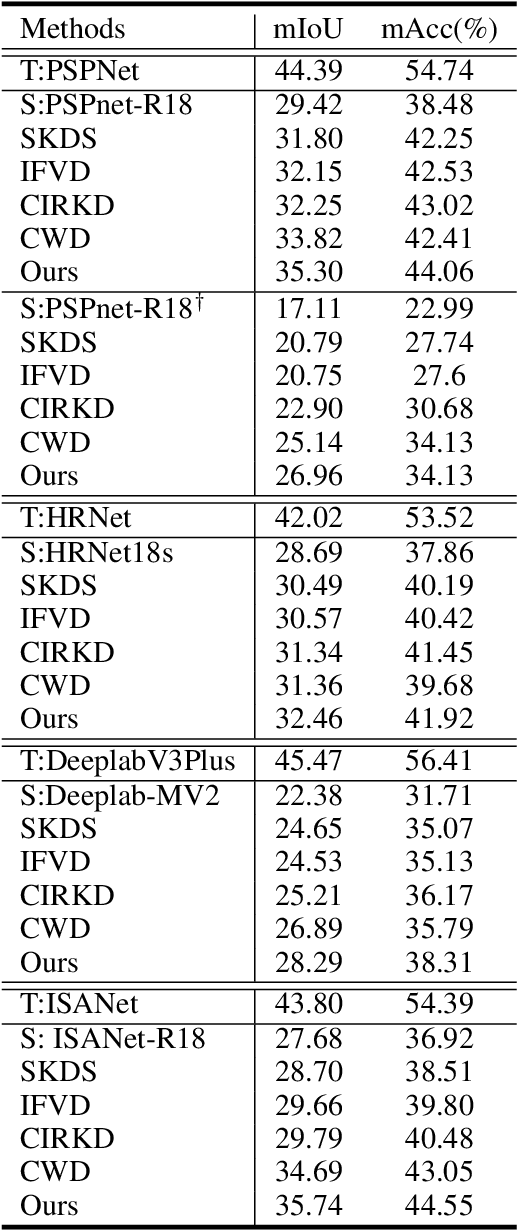
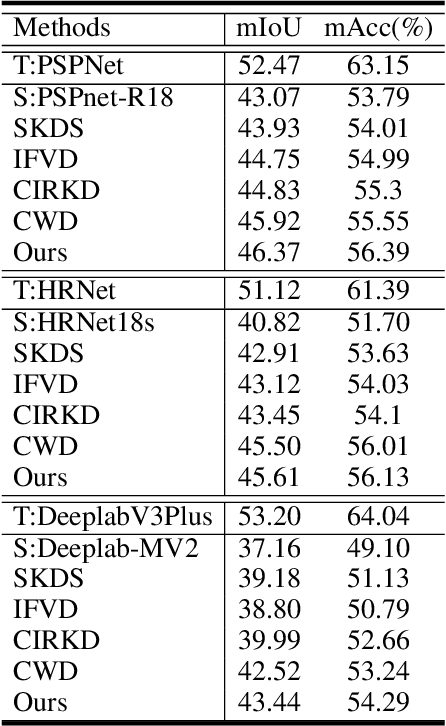
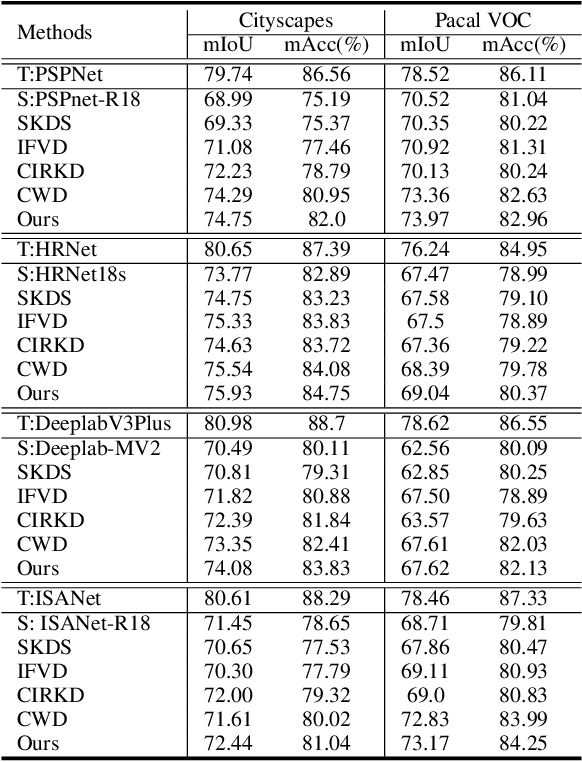
In this work, we explore data augmentations for knowledge distillation on semantic segmentation. To avoid over-fitting to the noise in the teacher network, a large number of training examples is essential for knowledge distillation. Imagelevel argumentation techniques like flipping, translation or rotation are widely used in previous knowledge distillation framework. Inspired by the recent progress on semantic directions on feature-space, we propose to include augmentations in feature space for efficient distillation. Specifically, given a semantic direction, an infinite number of augmentations can be obtained for the student in the feature space. Furthermore, the analysis shows that those augmentations can be optimized simultaneously by minimizing an upper bound for the losses defined by augmentations. Based on the observation, a new algorithm is developed for knowledge distillation in semantic segmentation. Extensive experiments on four semantic segmentation benchmarks demonstrate that the proposed method can boost the performance of current knowledge distillation methods without any significant overhead. Code is available at: https://github.com/jianlong-yuan/FAKD.
1st Place Solution to ECCV-TAO-2020: Detect and Represent Any Object for Tracking
Feb 01, 2021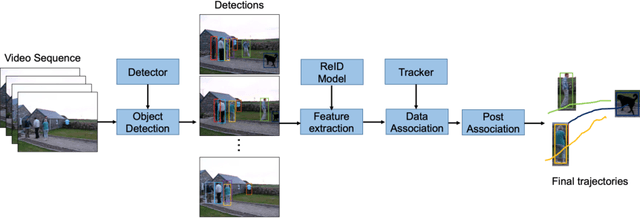
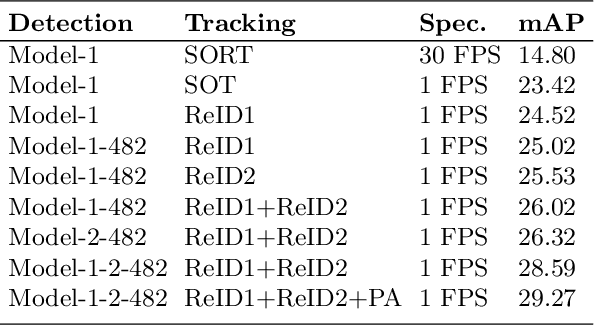

We extend the classical tracking-by-detection paradigm to this tracking-any-object task. Solid detection results are first extracted from TAO dataset. Some state-of-the-art techniques like \textbf{BA}lanced-\textbf{G}roup \textbf{S}oftmax (\textbf{BAGS}\cite{li2020overcoming}) and DetectoRS\cite{qiao2020detectors} are integrated during detection. Then we learned appearance features to represent any object by training feature learning networks. We ensemble several models for improving detection and feature representation. Simple linking strategies with most similar appearance features and tracklet-level post association module are finally applied to generate final tracking results. Our method is submitted as \textbf{AOA} on the challenge website. Code is available at https://github.com/feiaxyt/Winner_ECCV20_TAO.