 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-RS: A Spatially Faithful Unified Understanding and Generation Model for Remote Sensing
Jan 25, 2026Unified remote sensing multimodal models exhibit a pronounced spatial reversal curse: Although they can accurately recognize and describe object locations in images, they often fail to faithfully execute the same spatial relations during text-to-image generation, where such relations constitute core semantic information in remote sensing. Motivated by this observation, we propose Uni-RS, the first unified multimodal model tailored for remote sensing, to explicitly address the spatial asymmetry between understanding and generation. Specifically, we first introduce explicit Spatial-Layout Planning to transform textual instructions into spatial layout plans, decoupling geometric planning from visual synthesis. We then impose Spatial-Aware Query Supervision to bias learnable queries toward spatial relations explicitly specified in the instruction. Finally, we develop Image-Caption Spatial Layout Variation to expose the model to systematic geometry-consistent spatial transformations. Extensive experiments across multiple benchmarks show that our approach substantially improves spatial faithfulness in text-to-image generation, while maintaining strong performance on multimodal understanding tasks like image captioning, visual grounding, and VQA tasks.
GeoPix: Multi-Modal Large Language Model for Pixel-level Image Understanding in Remote Sensing
Jan 12, 2025



Multi-modal large language models (MLLMs) have achieved remarkable success in image- and region-level remote sensing (RS) image understanding tasks, such as image captioning, visual question answering, and visual grounding. However, existing RS MLLMs lack the pixel-level dialogue capability, which involves responding to user instructions with segmentation masks for specific instances. In this paper, we propose GeoPix, a RS MLLM that extends image understanding capabilities to the pixel level. This is achieved by equipping the MLLM with a mask predictor, which transforms visual features from the vision encoder into masks conditioned on the LLM's segmentation token embeddings. To facilitate the segmentation of multi-scale objects in RS imagery, a class-wise learnable memory module is integrated into the mask predictor to capture and store class-wise geo-context at the instance level across the entire dataset. In addition, to address the absence of large-scale datasets for training pixel-level RS MLLMs, we construct the GeoPixInstruct dataset, comprising 65,463 images and 140,412 instances, with each instance annotated with text descriptions, bounding boxes, and masks. Furthermore, we develop a two-stage training strategy to balance the distinct requirements of text generation and masks prediction in multi-modal multi-task optimization. Extensive experiments verify the effectiveness and superiority of GeoPix in pixel-level segmentation tasks, while also maintaining competitive performance in image- and region-level benchmarks.
Viewpoint Integration and Registration with Vision Language Foundation Model for Image Change Understanding
Sep 15, 2023



Recently, the development of pre-trained vision language foundation models (VLFMs) has led to remarkable performance in many tasks. However, these models tend to have strong single-image understanding capability but lack the ability to understand multiple images. Therefore, they cannot be directly applied to cope with image change understanding (ICU), which requires models to capture actual changes between multiple images and describe them in language. In this paper, we discover that existing VLFMs perform poorly when applied directly to ICU because of the following problems: (1) VLFMs generally learn the global representation of a single image, while ICU requires capturing nuances between multiple images. (2) The ICU performance of VLFMs is significantly affected by viewpoint variations, which is caused by the altered relationships between objects when viewpoint changes. To address these problems, we propose a Viewpoint Integration and Registration method. Concretely, we introduce a fused adapter image encoder that fine-tunes pre-trained encoders by inserting designed trainable adapters and fused adapters, to effectively capture nuances between image pairs. Additionally, a viewpoint registration flow and a semantic emphasizing module are designed to reduce the performance degradation caused by viewpoint variations in the visual and semantic space, respectively. Experimental results on CLEVR-Change and Spot-the-Diff demonstrate that our method achieves state-of-the-art performance in all metrics.
RSGPT: A Remote Sensing Vision Language Model and Benchmark
Jul 28, 2023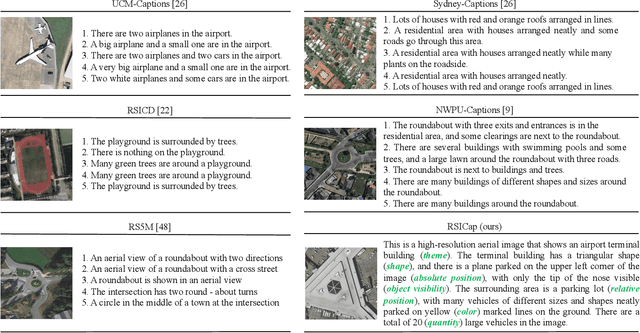



The emergence of large-scale large language models, with GPT-4 as a prominent example, has significantly propelled the rapid advancement of artificial general intelligence and sparked the revolution of Artificial Intelligence 2.0. In the realm of remote sensing (RS), there is a growing interest in developing large vision language models (VLMs) specifically tailored for data analysis in this domain. However, current research predominantly revolves around visual recognition tasks, lacking comprehensive, large-scale image-text datasets that are aligned and suitable for training large VLMs, which poses significant challenges to effectively training such models for RS applications. In computer vision, recent research has demonstrated that fine-tuning large vision language models on small-scale, high-quality datasets can yield impressive performance in visual and language understanding. These results are comparable to state-of-the-art VLMs trained from scratch on massive amounts of data, such as GPT-4. Inspired by this captivating idea, in this work, we build a high-quality Remote Sensing Image Captioning dataset (RSICap) that facilitates the development of large VLMs in the RS field. Unlike previous RS datasets that either employ model-generated captions or short descriptions, RSICap comprises 2,585 human-annotated captions with rich and high-quality information. This dataset offers detailed descriptions for each image, encompassing scene descriptions (e.g., residential area, airport, or farmland) as well as object information (e.g., color, shape, quantity, absolute position, etc). To facilitate the evaluation of VLMs in the field of RS, we also provide a benchmark evaluation dataset called RSIEval. This dataset consists of human-annotated captions and visual question-answer pairs, allowing for a comprehensive assessment of VLMs in the context of RS.
SwinRDM: Integrate SwinRNN with Diffusion Model towards High-Resolution and High-Quality Weather Forecasting
Jun 05, 2023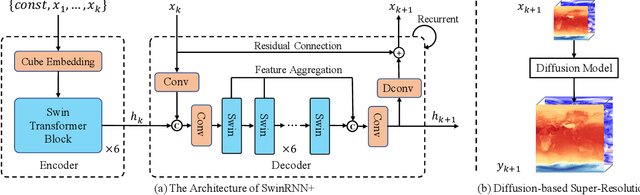

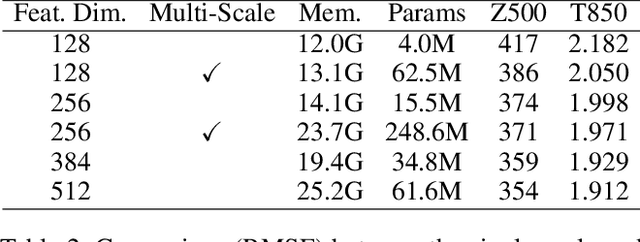
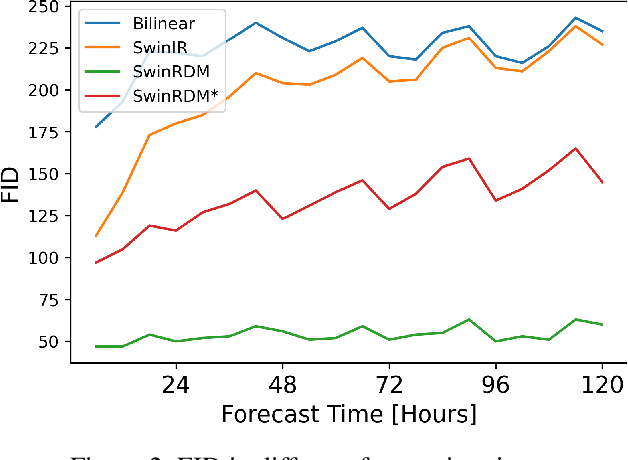
Data-driven medium-range weather forecasting has attracted much attention in recent years. However, the forecasting accuracy at high resolution is unsatisfactory currently. Pursuing high-resolution and high-quality weather forecasting, we develop a data-driven model SwinRDM which integrates an improved version of SwinRNN with a diffusion model. SwinRDM performs predictions at 0.25-degree resolution and achieves superior forecasting accuracy to IFS (Integrated Forecast System), the state-of-the-art operational NWP model, on representative atmospheric variables including 500 hPa geopotential (Z500), 850 hPa temperature (T850), 2-m temperature (T2M), and total precipitation (TP), at lead times of up to 5 days. We propose to leverage a two-step strategy to achieve high-resolution predictions at 0.25-degree considering the trade-off between computation memory and forecasting accuracy. Recurrent predictions for future atmospheric fields are firstly performed at 1.40625-degree resolution, and then a diffusion-based super-resolution model is leveraged to recover the high spatial resolution and finer-scale atmospheric details. SwinRDM pushes forward the performance and potential of data-driven models for a large margin towards operational applications.
Vision-Language Models in Remote Sensing: Current Progress and Future Trends
May 09, 2023



The remarkable achievements of ChatGPT and GPT-4 have sparked a wave of interest and research in the field of large language models for Artificial General Intelligence (AGI). These models provide us with intelligent solutions that are more similar to human thinking, enabling us to use general artificial intelligence to solve problems in various applications. However, in the field of remote sensing, the scientific literature on the implementation of AGI remains relatively scant. Existing AI-related research primarily focuses on visual understanding tasks while neglecting the semantic understanding of the objects and their relationships. This is where vision-language models excel, as they enable reasoning about images and their associated textual descriptions, allowing for a deeper understanding of the underlying semantics. Vision-language models can go beyond recognizing the objects in an image and can infer the relationships between them, as well as generate natural language descriptions of the image. This makes them better suited for tasks that require both visual and textual understanding, such as image captioning, text-based image retrieval, and visual question answering. This paper provides a comprehensive review of the research on vision-language models in remote sensing, summarizing the latest progress, highlighting the current challenges, and identifying potential research opportunities. Specifically, we review the application of vision-language models in several mainstream remote sensing tasks, including image captioning, text-based image generation, text-based image retrieval, visual question answering, scene classification, semantic segmentation, and object detection. For each task, we briefly describe the task background and review some representative works. Finally, we summarize the limitations of existing work and provide some possible directions for future development.
PolyBuilding: Polygon Transformer for End-to-End Building Extraction
Nov 03, 2022We present PolyBuilding, a fully end-to-end polygon Transformer for building extraction. PolyBuilding direct predicts vector representation of buildings from remote sensing images. It builds upon an encoder-decoder transformer architecture and simultaneously outputs building bounding boxes and polygons. Given a set of polygon queries, the model learns the relations among them and encodes context information from the image to predict the final set of building polygons with fixed vertex numbers. Corner classification is performed to distinguish the building corners from the sampled points, which can be used to remove redundant vertices along the building walls during inference. A 1-d non-maximum suppression (NMS) is further applied to reduce vertex redundancy near the building corners. With the refinement operations, polygons with regular shapes and low complexity can be effectively obtained. Comprehensive experiments are conducted on the CrowdAI dataset. Quantitative and qualitative results show that our approach outperforms prior polygonal building extraction methods by a large margin. It also achieves a new state-of-the-art in terms of pixel-level coverage, instance-level precision and recall, and geometry-level properties (including contour regularity and polygon complexity).
SwinVRNN: A Data-Driven Ensemble Forecasting Model via Learned Distribution Perturbation
May 26, 2022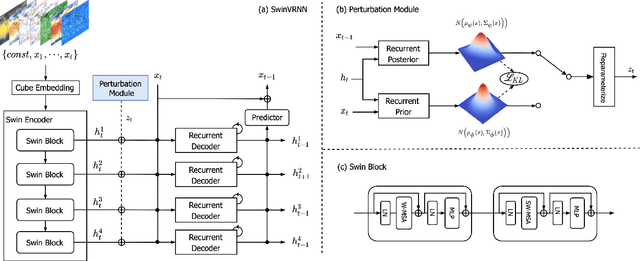


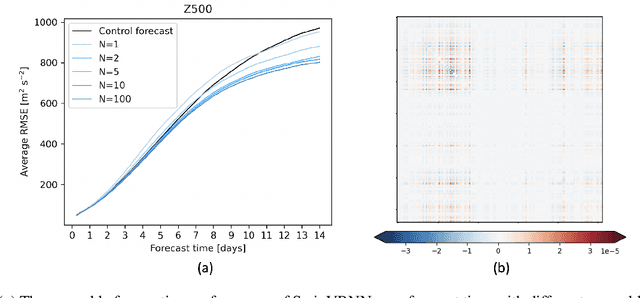
Data-driven approaches for medium-range weather forecasting are recently shown extraordinarily promising for ensemble forecasting for their fast inference speed compared to traditional numerical weather prediction (NWP) models, but their forecast accuracy can hardly match the state-of-the-art operational ECMWF Integrated Forecasting System (IFS) model. Previous data-driven attempts achieve ensemble forecast using some simple perturbation methods, like initial condition perturbation and Monte Carlo dropout. However, they mostly suffer unsatisfactory ensemble performance, which is arguably attributed to the sub-optimal ways of applying perturbation. We propose a Swin Transformer-based Variational Recurrent Neural Network (SwinVRNN), which is a stochastic weather forecasting model combining a SwinRNN predictor with a perturbation module. SwinRNN is designed as a Swin Transformer-based recurrent neural network, which predicts future states deterministically. Furthermore, to model the stochasticity in prediction, we design a perturbation module following the Variational Auto-Encoder paradigm to learn multivariate Gaussian distributions of a time-variant stochastic latent variable from data. Ensemble forecasting can be easily achieved by perturbing the model features leveraging noise sampled from the learned distribution. We also compare four categories of perturbation methods for ensemble forecasting, i.e. fixed distribution perturbation, learned distribution perturbation, MC dropout, and multi model ensemble. Comparisons on WeatherBench dataset show the learned distribution perturbation method using our SwinVRNN model achieves superior forecast accuracy and reasonable ensemble spread due to joint optimization of the two targets. More notably, SwinVRNN surpasses operational IFS on surface variables of 2-m temperature and 6-hourly total precipitation at all lead times up to five days.
TextFlint: Unified Multilingual Robustness Evaluation Toolkit for Natural Language Processing
Apr 06, 2021



Various robustness evaluation methodologies from different perspectives have been proposed for different natural language processing (NLP) tasks. These methods have often focused on either universal or task-specific generalization capabilities. In this work, we propose a multilingual robustness evaluation platform for NLP tasks (TextFlint) that incorporates universal text transformation, task-specific transformation, adversarial attack, subpopulation, and their combinations to provide comprehensive robustness analysis. TextFlint enables practitioners to automatically evaluate their models from all aspects or to customize their evaluations as desired with just a few lines of code. To guarantee user acceptability, all the text transformations are linguistically based, and we provide a human evaluation for each one. TextFlint generates complete analytical reports as well as targeted augmented data to address the shortcomings of the model's robustness. To validate TextFlint's utility, we performed large-scale empirical evaluations (over 67,000 evaluations) on state-of-the-art deep learning models, classic supervised methods, and real-world systems. Almost all models showed significant performance degradation, including a decline of more than 50% of BERT's prediction accuracy on tasks such as aspect-level sentiment classification, named entity recognition, and natural language inference. Therefore, we call for the robustness to be included in the model evaluation, so as to promote the healthy development of NLP technology.
GBCNs: Genetic Binary Convolutional Networks for Enhancing the Performance of 1-bit DCNNs
Nov 25, 2019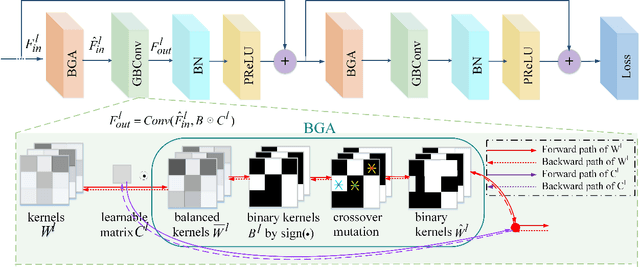

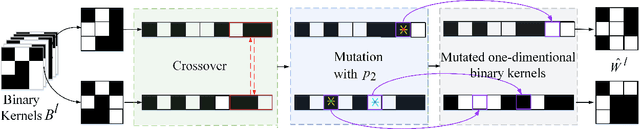
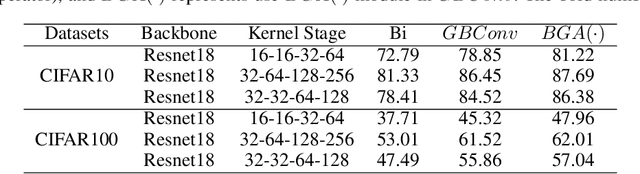
Training 1-bit deep convolutional neural networks (DCNNs) is one of the most challenging problems in computer vision, because it is much easier to get trapped into local minima than conventional DCNNs. The reason lies in that the binarized kernels and activations of 1-bit DCNNs cause a significant accuracy loss and training inefficiency. To address this problem, we propose Genetic Binary Convolutional Networks (GBCNs) to optimize 1-bit DCNNs, by introducing a new balanced Genetic Algorithm (BGA) to improve the representational ability in an end-to-end framework. The BGA method is proposed to modify the binary process of GBCNs to alleviate the local minima problem, which can significantly improve the performance of 1-bit DCNNs. We develop a new BGA module that is generic and flexible, and can be easily incorporated into existing DCNNs, such asWideResNets and ResNets. Extensive experiments on the object classification tasks (CIFAR, ImageNet) validate the effectiveness of the proposed method. To highlight, our method shows strong generalization on the object recognition task, i.e., face recognition, facial and person re-identification.