 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKirchhoff-Inspired Neural Networks for Evolving High-Order Perception
Mar 25, 2026Deep learning architectures are fundamentally inspired by neuroscience, particularly the structure of the brain's sensory pathways, and have achieved remarkable success in learning informative data representations. Although these architectures mimic the communication mechanisms of biological neurons, their strategies for information encoding and transmission are fundamentally distinct. Biological systems depend on dynamic fluctuations in membrane potential; by contrast, conventional deep networks optimize weights and biases by adjusting the strengths of inter-neural connections, lacking a systematic mechanism to jointly characterize the interplay among signal intensity, coupling structure, and state evolution. To tackle this limitation, we propose the Kirchhoff-Inspired Neural Network (KINN), a state-variable-based network architecture constructed based on Kirchhoff's current law. KINN derives numerically stable state updates from fundamental ordinary differential equations, enabling the explicit decoupling and encoding of higher-order evolutionary components within a single layer while preserving physical consistency, interpretability, and end-to-end trainability. Extensive experiments on partial differential equation (PDE) solving and ImageNet image classification validate that KINN outperforms state-of-the-art existing methods.
Think Proprioceptively: Embodied Visual Reasoning for VLA Manipulation
Feb 06, 2026Vision-language-action (VLA) models typically inject proprioception only as a late conditioning signal, which prevents robot state from shaping instruction understanding and from influencing which visual tokens are attended throughout the policy. We introduce ThinkProprio, which converts proprioception into a sequence of text tokens in the VLM embedding space and fuses them with the task instruction at the input. This early fusion lets embodied state participate in subsequent visual reasoning and token selection, biasing computation toward action-critical evidence while suppressing redundant visual tokens. In a systematic ablation over proprioception encoding, state entry point, and action-head conditioning, we find that text tokenization is more effective than learned projectors, and that retaining roughly 15% of visual tokens can match the performance of using the full token set. Across CALVIN, LIBERO, and real-world manipulation, ThinkProprio matches or improves over strong baselines while reducing end-to-end inference latency over 50%.
HuBE: Cross-Embodiment Human-like Behavior Execution for Humanoid Robots
Aug 26, 2025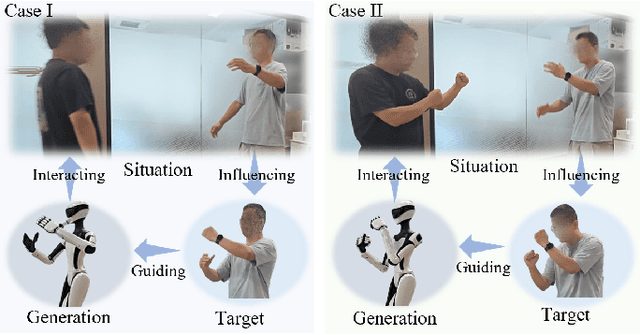
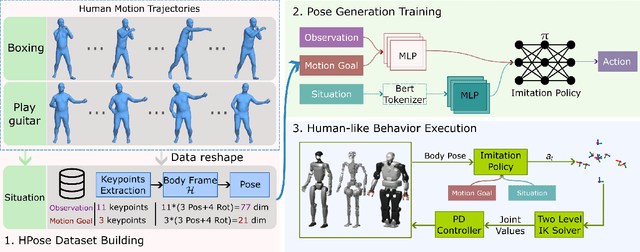

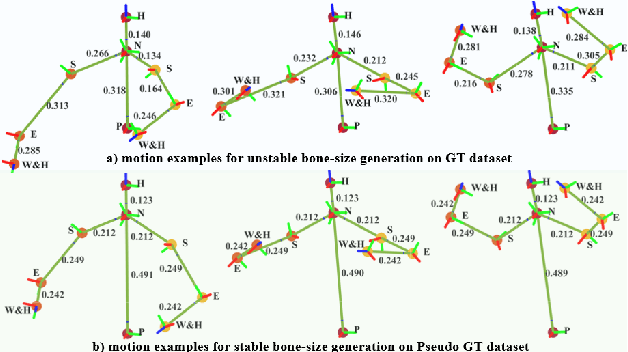
Achieving both behavioral similarity and appropriateness in human-like motion generation for humanoid robot remains an open challenge, further compounded by the lack of cross-embodiment adaptability. To address this problem, we propose HuBE, a bi-level closed-loop framework that integrates robot state, goal poses, and contextual situations to generate human-like behaviors, ensuring both behavioral similarity and appropriateness, and eliminating structural mismatches between motion generation and execution. To support this framework, we construct HPose, a context-enriched dataset featuring fine-grained situational annotations. Furthermore, we introduce a bone scaling-based data augmentation strategy that ensures millimeter-level compatibility across heterogeneous humanoid robots. Comprehensive evaluations on multiple commercial platforms demonstrate that HuBE significantly improves motion similarity, behavioral appropriateness, and computational efficiency over state-of-the-art baselines, establishing a solid foundation for transferable and human-like behavior execution across diverse humanoid robots.
Instruction-Augmented Long-Horizon Planning: Embedding Grounding Mechanisms in Embodied Mobile Manipulation
Mar 11, 2025Enabling humanoid robots to perform long-horizon mobile manipulation planning in real-world environments based on embodied perception and comprehension abilities has been a longstanding challenge. With the recent rise of large language models (LLMs), there has been a notable increase in the development of LLM-based planners. These approaches either utilize human-provided textual representations of the real world or heavily depend on prompt engineering to extract such representations, lacking the capability to quantitatively understand the environment, such as determining the feasibility of manipulating objects. To address these limitations, we present the Instruction-Augmented Long-Horizon Planning (IALP) system, a novel framework that employs LLMs to generate feasible and optimal actions based on real-time sensor feedback, including grounded knowledge of the environment, in a closed-loop interaction. Distinct from prior works, our approach augments user instructions into PDDL problems by leveraging both the abstract reasoning capabilities of LLMs and grounding mechanisms. By conducting various real-world long-horizon tasks, each consisting of seven distinct manipulatory skills, our results demonstrate that the IALP system can efficiently solve these tasks with an average success rate exceeding 80%. Our proposed method can operate as a high-level planner, equipping robots with substantial autonomy in unstructured environments through the utilization of multi-modal sensor inputs.
* 17 pages, 11 figures
REF-VLM: Triplet-Based Referring Paradigm for Unified Visual Decoding
Mar 10, 2025
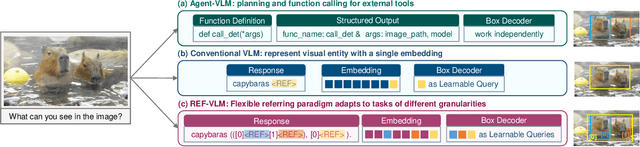

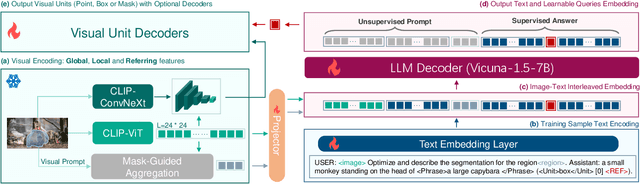
Multimodal Large Language Models (MLLMs) demonstrate robust zero-shot capabilities across diverse vision-language tasks after training on mega-scale datasets. However, dense prediction tasks, such as semantic segmentation and keypoint detection, pose significant challenges for MLLMs when represented solely as text outputs. Simultaneously, current MLLMs utilizing latent embeddings for visual task decoding generally demonstrate limited adaptability to both multi-task learning and multi-granularity scenarios. In this work, we present REF-VLM, an end-to-end framework for unified training of various visual decoding tasks. To address complex visual decoding scenarios, we introduce the Triplet-Based Referring Paradigm (TRP), which explicitly decouples three critical dimensions in visual decoding tasks through a triplet structure: concepts, decoding types, and targets. TRP employs symbolic delimiters to enforce structured representation learning, enhancing the parsability and interpretability of model outputs. Additionally, we construct Visual-Task Instruction Following Dataset (VTInstruct), a large-scale multi-task dataset containing over 100 million multimodal dialogue samples across 25 task types. Beyond text inputs and outputs, VT-Instruct incorporates various visual prompts such as point, box, scribble, and mask, and generates outputs composed of text and visual units like box, keypoint, depth and mask. The combination of different visual prompts and visual units generates a wide variety of task types, expanding the applicability of REF-VLM significantly. Both qualitative and quantitative experiments demonstrate that our REF-VLM outperforms other MLLMs across a variety of standard benchmarks. The code, dataset, and demo available at https://github.com/MacavityT/REF-VLM.
Graph Structure Refinement with Energy-based Contrastive Learning
Dec 20, 2024



Graph Neural Networks (GNNs) have recently gained widespread attention as a successful tool for analyzing graph-structured data. However, imperfect graph structure with noisy links lacks enough robustness and may damage graph representations, therefore limiting the GNNs' performance in practical tasks. Moreover, existing generative architectures fail to fit discriminative graph-related tasks. To tackle these issues, we introduce an unsupervised method based on a joint of generative training and discriminative training to learn graph structure and representation, aiming to improve the discriminative performance of generative models. We propose an Energy-based Contrastive Learning (ECL) guided Graph Structure Refinement (GSR) framework, denoted as ECL-GSR. To our knowledge, this is the first work to combine energy-based models with contrastive learning for GSR. Specifically, we leverage ECL to approximate the joint distribution of sample pairs, which increases the similarity between representations of positive pairs while reducing the similarity between negative ones. Refined structure is produced by augmenting and removing edges according to the similarity metrics among node representations. Extensive experiments demonstrate that ECL-GSR outperforms \textit{the state-of-the-art on eight benchmark datasets} in node classification. ECL-GSR achieves \textit{faster training with fewer samples and memories} against the leading baseline, highlighting its simplicity and efficiency in downstream tasks.
Achieving Stable High-Speed Locomotion for Humanoid Robots with Deep Reinforcement Learning
Sep 25, 2024Humanoid robots offer significant versatility for performing a wide range of tasks, yet their basic ability to walk and run, especially at high velocities, remains a challenge. This letter presents a novel method that combines deep reinforcement learning with kinodynamic priors to achieve stable locomotion control (KSLC). KSLC promotes coordinated arm movements to counteract destabilizing forces, enhancing overall stability. Compared to the baseline method, KSLC provides more accurate tracking of commanded velocities and better generalization in velocity control. In simulation tests, the KSLC-enabled humanoid robot successfully tracked a target velocity of 3.5 m/s with reduced fluctuations. Sim-to-sim validation in a high-fidelity environment further confirmed its robust performance, highlighting its potential for real-world applications.
Fusion-Mamba for Cross-modality Object Detection
Apr 14, 2024
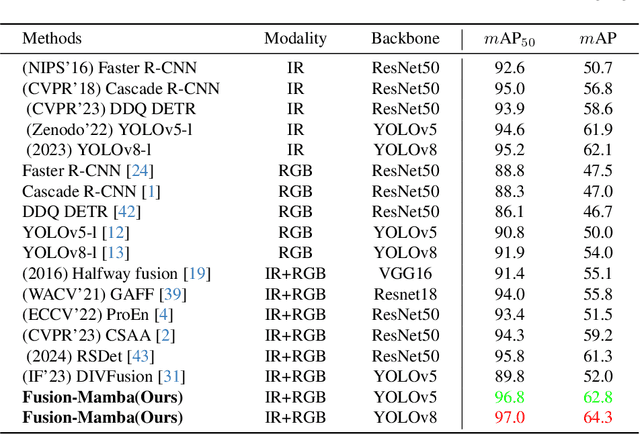
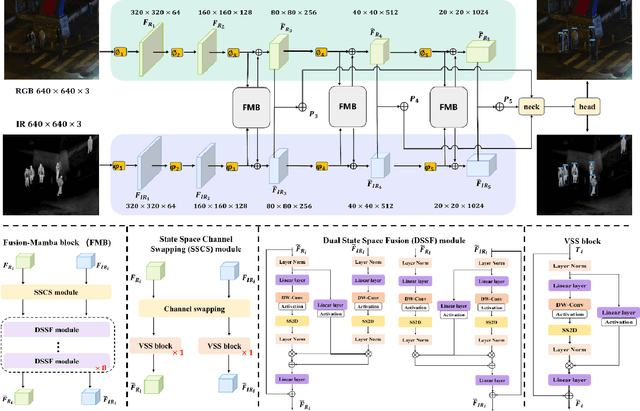
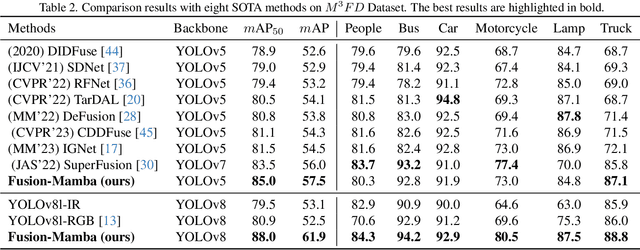
Cross-modality fusing complementary information from different modalities effectively improves object detection performance, making it more useful and robust for a wider range of applications. Existing fusion strategies combine different types of images or merge different backbone features through elaborated neural network modules. However, these methods neglect that modality disparities affect cross-modality fusion performance, as different modalities with different camera focal lengths, placements, and angles are hardly fused. In this paper, we investigate cross-modality fusion by associating cross-modal features in a hidden state space based on an improved Mamba with a gating mechanism. We design a Fusion-Mamba block (FMB) to map cross-modal features into a hidden state space for interaction, thereby reducing disparities between cross-modal features and enhancing the representation consistency of fused features. FMB contains two modules: the State Space Channel Swapping (SSCS) module facilitates shallow feature fusion, and the Dual State Space Fusion (DSSF) enables deep fusion in a hidden state space. Through extensive experiments on public datasets, our proposed approach outperforms the state-of-the-art methods on $m$AP with 5.9% on $M^3FD$ and 4.9% on FLIR-Aligned datasets, demonstrating superior object detection performance. To the best of our knowledge, this is the first work to explore the potential of Mamba for cross-modal fusion and establish a new baseline for cross-modality object detection.
Implicit Subgoal Planning with Variational Autoencoders for Long-Horizon Sparse Reward Robotic Tasks
Dec 25, 2023



The challenges inherent to long-horizon tasks in robotics persist due to the typical inefficient exploration and sparse rewards in traditional reinforcement learning approaches. To alleviate these challenges, we introduce a novel algorithm, Variational Autoencoder-based Subgoal Inference (VAESI), to accomplish long-horizon tasks through a divide-and-conquer manner. VAESI consists of three components: a Variational Autoencoder (VAE)-based Subgoal Generator, a Hindsight Sampler, and a Value Selector. The VAE-based Subgoal Generator draws inspiration from the human capacity to infer subgoals and reason about the final goal in the context of these subgoals. It is composed of an explicit encoder model, engineered to generate subgoals, and an implicit decoder model, designed to enhance the quality of the generated subgoals by predicting the final goal. Additionally, the Hindsight Sampler selects valid subgoals from an offline dataset to enhance the feasibility of the generated subgoals. The Value Selector utilizes the value function in reinforcement learning to filter the optimal subgoals from subgoal candidates. To validate our method, we conduct several long-horizon tasks in both simulation and the real world, including one locomotion task and three manipulation tasks. The obtained quantitative and qualitative data indicate that our approach achieves promising performance compared to other baseline methods. These experimental results can be seen in the website \url{https://sites.google.com/view/vaesi/home}.
NCL++: Nested Collaborative Learning for Long-Tailed Visual Recognition
Jun 29, 2023Long-tailed visual recognition has received increasing attention in recent years. Due to the extremely imbalanced data distribution in long-tailed learning, the learning process shows great uncertainties. For example, the predictions of different experts on the same image vary remarkably despite the same training settings. To alleviate the uncertainty, we propose a Nested Collaborative Learning (NCL++) which tackles the long-tailed learning problem by a collaborative learning. To be specific, the collaborative learning consists of two folds, namely inter-expert collaborative learning (InterCL) and intra-expert collaborative learning (IntraCL). In-terCL learns multiple experts collaboratively and concurrently, aiming to transfer the knowledge among different experts. IntraCL is similar to InterCL, but it aims to conduct the collaborative learning on multiple augmented copies of the same image within the single expert. To achieve the collaborative learning in long-tailed learning, the balanced online distillation is proposed to force the consistent predictions among different experts and augmented copies, which reduces the learning uncertainties. Moreover, in order to improve the meticulous distinguishing ability on the confusing categories, we further propose a Hard Category Mining (HCM), which selects the negative categories with high predicted scores as the hard categories. Then, the collaborative learning is formulated in a nested way, in which the learning is conducted on not just all categories from a full perspective but some hard categories from a partial perspective. Extensive experiments manifest the superiority of our method with outperforming the state-of-the-art whether with using a single model or an ensemble. The code will be publicly released.