 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaterClear-GS: Optical-Aware Gaussian Splatting for Underwater Reconstruction and Restoration
Jan 27, 2026Underwater 3D reconstruction and appearance restoration are hindered by the complex optical properties of water, such as wavelength-dependent attenuation and scattering. Existing Neural Radiance Fields (NeRF)-based methods struggle with slow rendering speeds and suboptimal color restoration, while 3D Gaussian Splatting (3DGS) inherently lacks the capability to model complex volumetric scattering effects. To address these issues, we introduce WaterClear-GS, the first pure 3DGS-based framework that explicitly integrates underwater optical properties of local attenuation and scattering into Gaussian primitives, eliminating the need for an auxiliary medium network. Our method employs a dual-branch optimization strategy to ensure underwater photometric consistency while naturally recovering water-free appearances. This strategy is enhanced by depth-guided geometry regularization and perception-driven image loss, together with exposure constraints, spatially-adaptive regularization, and physically guided spectral regularization, which collectively enforce local 3D coherence and maintain natural visual perception. Experiments on standard benchmarks and our newly collected dataset demonstrate that WaterClear-GS achieves outstanding performance on both novel view synthesis (NVS) and underwater image restoration (UIR) tasks, while maintaining real-time rendering. The code will be available at https://buaaxrzhang.github.io/WaterClear-GS/.
Beyond Model Scaling: Test-Time Intervention for Efficient Deep Reasoning
Jan 16, 2026Large Reasoning Models (LRMs) excel at multi-step reasoning but often suffer from inefficient reasoning processes like overthinking and overshoot, where excessive or misdirected reasoning increases computational cost and degrades performance. Existing efficient reasoning methods operate in a closed-loop manner, lacking mechanisms for external intervention to guide the reasoning process. To address this, we propose Think-with-Me, a novel test-time interactive reasoning paradigm that introduces external feedback intervention into the reasoning process. Our key insights are that transitional conjunctions serve as natural points for intervention, signaling phases of self-validation or exploration and using transitional words appropriately to prolong the reasoning enhances performance, while excessive use affects performance. Building on these insights, Think-with-Me pauses reasoning at these points for external feedback, adaptively extending or terminating reasoning to reduce redundancy while preserving accuracy. The feedback is generated via a multi-criteria evaluation (rationality and completeness) and comes from either human or LLM proxies. We train the target model using Group Relative Policy Optimization (GRPO) to adapt to this interactive mode. Experiments show that Think-with-Me achieves a superior balance between accuracy and reasoning length under limited context windows. On AIME24, Think-with-Me outperforms QwQ-32B by 7.19% in accuracy while reducing average reasoning length by 81% under an 8K window. The paradigm also benefits security and creative tasks.
How well can off-the-shelf LLMs elucidate molecular structures from mass spectra using chain-of-thought reasoning?
Jan 09, 2026Mass spectrometry (MS) is a powerful analytical technique for identifying small molecules, yet determining complete molecular structures directly from tandem mass spectra (MS/MS) remains a long-standing challenge due to complex fragmentation patterns and the vast diversity of chemical space. Recent progress in large language models (LLMs) has shown promise for reasoning-intensive scientific tasks, but their capability for chemical interpretation is still unclear. In this work, we introduce a Chain-of-Thought (CoT) prompting framework and benchmark that evaluate how LLMs reason about mass spectral data to predict molecular structures. We formalize expert chemists' reasoning steps-such as double bond equivalent (DBE) analysis, neutral loss identification, and fragment assembly-into structured prompts and assess multiple state-of-the-art LLMs (Claude-3.5-Sonnet, GPT-4o-mini, and Llama-3 series) in a zero-shot setting using the MassSpecGym dataset. Our evaluation across metrics of SMILES validity, formula consistency, and structural similarity reveals that while LLMs can produce syntactically valid and partially plausible structures, they fail to achieve chemical accuracy or link reasoning to correct molecular predictions. These findings highlight both the interpretive potential and the current limitations of LLM-based reasoning for molecular elucidation, providing a foundation for future work that combines domain knowledge and reinforcement learning to achieve chemically grounded AI reasoning.
Beyond Fast and Slow: Cognitive-Inspired Elastic Reasoning for Large Language Models
Dec 17, 2025Large language models (LLMs) have demonstrated impressive performance across various language tasks. However, existing LLM reasoning strategies mainly rely on the LLM itself with fast or slow mode (like o1 thinking) and thus struggle to balance reasoning efficiency and accuracy across queries of varying difficulties. In this paper, we propose Cognitive-Inspired Elastic Reasoning (CogER), a framework inspired by human hierarchical reasoning that dynamically selects the most suitable reasoning strategy for each query. Specifically, CogER first assesses the complexity of incoming queries and assigns them to one of several predefined levels, each corresponding to a tailored processing strategy, thereby addressing the challenge of unobservable query difficulty. To achieve automatic strategy selection, we model the process as a Markov Decision Process and train a CogER-Agent using reinforcement learning. The agent is guided by a reward function that balances solution quality and computational cost, ensuring resource-efficient reasoning. Moreover, for queries requiring external tools, we introduce Cognitive Tool-Assisted Reasoning, which enables the LLM to autonomously invoke external tools within its chain-of-thought. Extensive experiments demonstrate that CogER outperforms state-of-the-art Test-Time scaling methods, achieving at least a 13% relative improvement in average exact match on In-Domain tasks and an 8% relative gain on Out-of-Domain tasks.
TARG: Training-Free Adaptive Retrieval Gating for Efficient RAG
Nov 12, 2025Retrieval-Augmented Generation (RAG) improves factuality but retrieving for every query often hurts quality while inflating tokens and latency. We propose Training-free Adaptive Retrieval Gating (TARG), a single-shot policy that decides when to retrieve using only a short, no-context draft from the base model. From the draft's prefix logits, TARG computes lightweight uncertainty scores: mean token entropy, a margin signal derived from the top-1/top-2 logit gap via a monotone link, or small-N variance across a handful of stochastic prefixes, and triggers retrieval only when the score exceeds a threshold. The gate is model agnostic, adds only tens to hundreds of draft tokens, and requires no additional training or auxiliary heads. On NQ-Open, TriviaQA, and PopQA, TARG consistently shifts the accuracy-efficiency frontier: compared with Always-RAG, TARG matches or improves EM/F1 while reducing retrieval by 70-90% and cutting end-to-end latency, and it remains close to Never-RAG in overhead. A central empirical finding is that under modern instruction-tuned LLMs the margin signal is a robust default (entropy compresses as backbones sharpen), with small-N variance offering a conservative, budget-first alternative. We provide ablations over gate type and prefix length and use a delta-latency view to make budget trade-offs explicit.
ComoRAG: A Cognitive-Inspired Memory-Organized RAG for Stateful Long Narrative Reasoning
Aug 14, 2025



Narrative comprehension on long stories and novels has been a challenging domain attributed to their intricate plotlines and entangled, often evolving relations among characters and entities. Given the LLM's diminished reasoning over extended context and high computational cost, retrieval-based approaches remain a pivotal role in practice. However, traditional RAG methods can fall short due to their stateless, single-step retrieval process, which often overlooks the dynamic nature of capturing interconnected relations within long-range context. In this work, we propose ComoRAG, holding the principle that narrative reasoning is not a one-shot process, but a dynamic, evolving interplay between new evidence acquisition and past knowledge consolidation, analogous to human cognition when reasoning with memory-related signals in the brain. Specifically, when encountering a reasoning impasse, ComoRAG undergoes iterative reasoning cycles while interacting with a dynamic memory workspace. In each cycle, it generates probing queries to devise new exploratory paths, then integrates the retrieved evidence of new aspects into a global memory pool, thereby supporting the emergence of a coherent context for the query resolution. Across four challenging long-context narrative benchmarks (200K+ tokens), ComoRAG outperforms strong RAG baselines with consistent relative gains up to 11% compared to the strongest baseline. Further analysis reveals that ComoRAG is particularly advantageous for complex queries requiring global comprehension, offering a principled, cognitively motivated paradigm for retrieval-based long context comprehension towards stateful reasoning. Our code is publicly released at https://github.com/EternityJune25/ComoRAG
Spectra-to-Structure and Structure-to-Spectra Inference Across the Periodic Table
Jun 13, 2025X-ray Absorption Spectroscopy (XAS) is a powerful technique for probing local atomic environments, yet its interpretation remains limited by the need for expert-driven analysis, computationally expensive simulations, and element-specific heuristics. Recent advances in machine learning have shown promise for accelerating XAS interpretation, but many existing models are narrowly focused on specific elements, edge types, or spectral regimes. In this work, we present XAStruct, a learning framework capable of both predicting XAS spectra from crystal structures and inferring local structural descriptors from XAS input. XAStruct is trained on a large-scale dataset spanning over 70 elements across the periodic table, enabling generalization to a wide variety of chemistries and bonding environments. The model includes the first machine learning approach for predicting neighbor atom types directly from XAS spectra, as well as a unified regression model for mean nearest-neighbor distance that requires no element-specific tuning. While we explored integrating the two pipelines into a single end-to-end model, empirical results showed performance degradation. As a result, the two tasks were trained independently to ensure optimal accuracy and task-specific performance. By combining deep neural networks for complex structure-property mappings with efficient baseline models for simpler tasks, XAStruct offers a scalable and extensible solution for data-driven XAS analysis and local structure inference. The source code will be released upon paper acceptance.
Recovering Fairness Directly from Modularity: a New Way for Fair Community Partitioning
May 27, 2025Community partitioning is crucial in network analysis, with modularity optimization being the prevailing technique. However, traditional modularity-based methods often overlook fairness, a critical aspect in real-world applications. To address this, we introduce protected group networks and propose a novel fairness-modularity metric. This metric extends traditional modularity by explicitly incorporating fairness, and we prove that minimizing it yields naturally fair partitions for protected groups while maintaining theoretical soundness. We develop a general optimization framework for fairness partitioning and design the efficient Fair Fast Newman (FairFN) algorithm, enhancing the Fast Newman (FN) method to optimize both modularity and fairness. Experiments show FairFN achieves significantly improved fairness and high-quality partitions compared to state-of-the-art methods, especially on unbalanced datasets.
Enhancing User-Oriented Proactivity in Open-Domain Dialogues with Critic Guidance
May 18, 2025
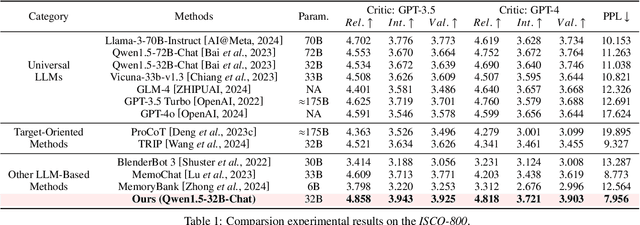
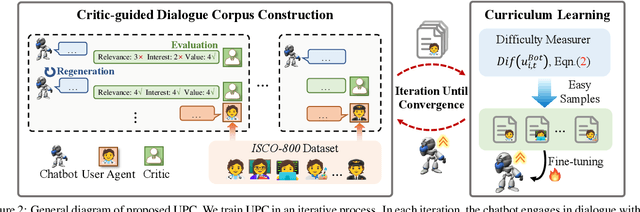

Open-domain dialogue systems aim to generate natural and engaging conversations, providing significant practical value in real applications such as social robotics and personal assistants. The advent of large language models (LLMs) has greatly advanced this field by improving context understanding and conversational fluency. However, existing LLM-based dialogue systems often fall short in proactively understanding the user's chatting preferences and guiding conversations toward user-centered topics. This lack of user-oriented proactivity can lead users to feel unappreciated, reducing their satisfaction and willingness to continue the conversation in human-computer interactions. To address this issue, we propose a User-oriented Proactive Chatbot (UPC) to enhance the user-oriented proactivity. Specifically, we first construct a critic to evaluate this proactivity inspired by the LLM-as-a-judge strategy. Given the scarcity of high-quality training data, we then employ the critic to guide dialogues between the chatbot and user agents, generating a corpus with enhanced user-oriented proactivity. To ensure the diversity of the user backgrounds, we introduce the ISCO-800, a diverse user background dataset for constructing user agents. Moreover, considering the communication difficulty varies among users, we propose an iterative curriculum learning method that trains the chatbot from easy-to-communicate users to more challenging ones, thereby gradually enhancing its performance. Experiments demonstrate that our proposed training method is applicable to different LLMs, improving user-oriented proactivity and attractiveness in open-domain dialogues.
Dynamic Compressing Prompts for Efficient Inference of Large Language Models
Apr 15, 2025Large Language Models (LLMs) have shown outstanding performance across a variety of tasks, partly due to advanced prompting techniques. However, these techniques often require lengthy prompts, which increase computational costs and can hinder performance because of the limited context windows of LLMs. While prompt compression is a straightforward solution, existing methods confront the challenges of retaining essential information, adapting to context changes, and remaining effective across different tasks. To tackle these issues, we propose a task-agnostic method called Dynamic Compressing Prompts (LLM-DCP). Our method reduces the number of prompt tokens while aiming to preserve the performance as much as possible. We model prompt compression as a Markov Decision Process (MDP), enabling the DCP-Agent to sequentially remove redundant tokens by adapting to dynamic contexts and retaining crucial content. We develop a reward function for training the DCP-Agent that balances the compression rate, the quality of the LLM output, and the retention of key information. This allows for prompt token reduction without needing an external black-box LLM. Inspired by the progressive difficulty adjustment in curriculum learning, we introduce a Hierarchical Prompt Compression (HPC) training strategy that gradually increases the compression difficulty, enabling the DCP-Agent to learn an effective compression method that maintains information integrity. Experiments demonstrate that our method outperforms state-of-the-art techniques, especially at higher compression rates. The code for our approach will be available at https://github.com/Fhujinwu/DCP.