 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibraGen: Playing a Balance Game in Subject-Driven Video Generation
Mar 17, 2026With the advancement of video generation foundation models (VGFMs), customized generation, particularly subject-to-video (S2V), has attracted growing attention. However, a key challenge lies in balancing the intrinsic priors of a VGFM, such as motion coherence, visual aesthetics, and prompt alignment, with its newly derived S2V capability. Existing methods often neglect this balance by enhancing one aspect at the expense of others. To address this, we propose LibraGen, a novel framework that views extending foundation models for S2V generation as a balance game between intrinsic VGFM strengths and S2V capability. Specifically, guided by the core philosophy of "Raising the Fulcrum, Tuning to Balance," we identify data quality as the fulcrum and advocate a quality-over-quantity approach. We construct a hybrid pipeline that combines automated and manual data filtering to improve overall data quality. To further harmonize the VGFM's native capabilities with its S2V extension, we introduce a Tune-to-Balance post-training paradigm. During supervised fine-tuning, both cross-pair and in-pair data are incorporated, and model merging is employed to achieve an effective trade-off. Subsequently, two tailored direct preference optimization (DPO) pipelines, namely Consis-DPO and Real-Fake DPO, are designed and merged to consolidate this balance. During inference, we introduce a time-dependent dynamic classifier-free guidance scheme to enable flexible and fine-grained control. Experimental results demonstrate that LibraGen outperforms both open-source and commercial S2V models using only thousand-scale training data.
Rethinking Security of Diffusion-based Generative Steganography
Feb 10, 2026Generative image steganography is a technique that conceals secret messages within generated images, without relying on pre-existing cover images. Recently, a number of diffusion model-based generative image steganography (DM-GIS) methods have been introduced, which effectively combat traditional steganalysis techniques. In this paper, we identify the key factors that influence DM-GIS security and revisit the security of existing methods. Specifically, we first provide an overview of the general pipelines of current DM-GIS methods, finding that the noise space of diffusion models serves as the primary embedding domain. Further, we analyze the relationship between DM-GIS security and noise distribution of diffusion models, theoretically demonstrating that any steganographic operation that disrupts the noise distribution compromise DM-GIS security. Building on this insight, we propose a Noise Space-based Diffusion Steganalyzer (NS-DSer)-a simple yet effective steganalysis framework allowing for detecting DM-GIS generated images in the diffusion model noise space. We reevaluate the security of existing DM-GIS methods using NS-DSer across increasingly challenging detection scenarios. Experimental results validate our theoretical analysis of DM-GIS security and show the effectiveness of NS-DSer across diverse detection scenarios.
ObjEmbed: Towards Universal Multimodal Object Embeddings
Feb 03, 2026Aligning objects with corresponding textual descriptions is a fundamental challenge and a realistic requirement in vision-language understanding. While recent multimodal embedding models excel at global image-text alignment, they often struggle with fine-grained alignment between image regions and specific phrases. In this work, we present ObjEmbed, a novel MLLM embedding model that decomposes the input image into multiple regional embeddings, each corresponding to an individual object, along with global embeddings. It supports a wide range of visual understanding tasks like visual grounding, local image retrieval, and global image retrieval. ObjEmbed enjoys three key properties: (1) Object-Oriented Representation: It captures both semantic and spatial aspects of objects by generating two complementary embeddings for each region: an object embedding for semantic matching and an IoU embedding that predicts localization quality. The final object matching score combines semantic similarity with the predicted IoU, enabling more accurate retrieval. (2) Versatility: It seamlessly handles both region-level and image-level tasks. (3) Efficient Encoding: All objects in an image, along with the full image, are encoded in a single forward pass for high efficiency. Superior performance on 18 diverse benchmarks demonstrates its strong semantic discrimination.
WeDetect: Fast Open-Vocabulary Object Detection as Retrieval
Dec 13, 2025Open-vocabulary object detection aims to detect arbitrary classes via text prompts. Methods without cross-modal fusion layers (non-fusion) offer faster inference by treating recognition as a retrieval problem, \ie, matching regions to text queries in a shared embedding space. In this work, we fully explore this retrieval philosophy and demonstrate its unique advantages in efficiency and versatility through a model family named WeDetect: (1) State-of-the-art performance. WeDetect is a real-time detector with a dual-tower architecture. We show that, with well-curated data and full training, the non-fusion WeDetect surpasses other fusion models and establishes a strong open-vocabulary foundation. (2) Fast backtrack of historical data. WeDetect-Uni is a universal proposal generator based on WeDetect. We freeze the entire detector and only finetune an objectness prompt to retrieve generic object proposals across categories. Importantly, the proposal embeddings are class-specific and enable a new application, object retrieval, supporting retrieval objects in historical data. (3) Integration with LMMs for referring expression comprehension (REC). We further propose WeDetect-Ref, an LMM-based object classifier to handle complex referring expressions, which retrieves target objects from the proposal list extracted by WeDetect-Uni. It discards next-token prediction and classifies objects in a single forward pass. Together, the WeDetect family unifies detection, proposal generation, object retrieval, and REC under a coherent retrieval framework, achieving state-of-the-art performance across 15 benchmarks with high inference efficiency.
Adversarial Distribution Matching for Diffusion Distillation Towards Efficient Image and Video Synthesis
Jul 24, 2025
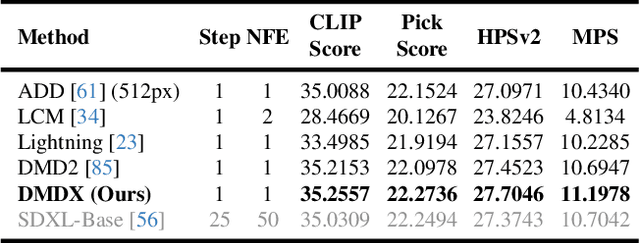
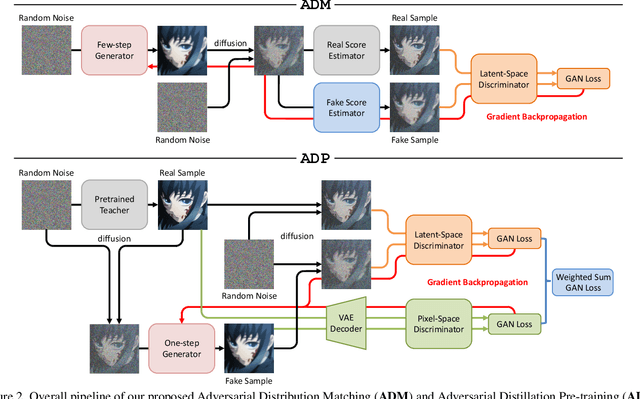
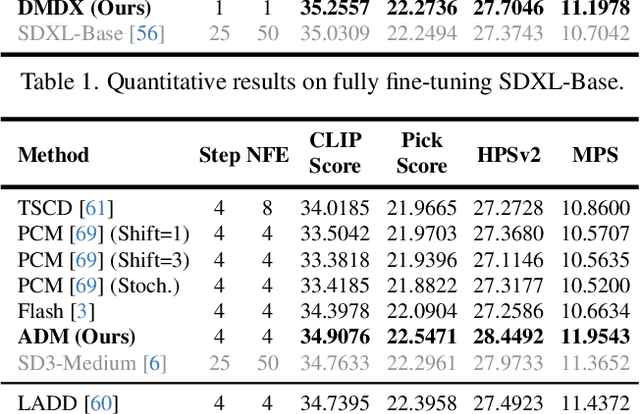
Distribution Matching Distillation (DMD) is a promising score distillation technique that compresses pre-trained teacher diffusion models into efficient one-step or multi-step student generators. Nevertheless, its reliance on the reverse Kullback-Leibler (KL) divergence minimization potentially induces mode collapse (or mode-seeking) in certain applications. To circumvent this inherent drawback, we propose Adversarial Distribution Matching (ADM), a novel framework that leverages diffusion-based discriminators to align the latent predictions between real and fake score estimators for score distillation in an adversarial manner. In the context of extremely challenging one-step distillation, we further improve the pre-trained generator by adversarial distillation with hybrid discriminators in both latent and pixel spaces. Different from the mean squared error used in DMD2 pre-training, our method incorporates the distributional loss on ODE pairs collected from the teacher model, and thus providing a better initialization for score distillation fine-tuning in the next stage. By combining the adversarial distillation pre-training with ADM fine-tuning into a unified pipeline termed DMDX, our proposed method achieves superior one-step performance on SDXL compared to DMD2 while consuming less GPU time. Additional experiments that apply multi-step ADM distillation on SD3-Medium, SD3.5-Large, and CogVideoX set a new benchmark towards efficient image and video synthesis.
Mind the Trojan Horse: Image Prompt Adapter Enabling Scalable and Deceptive Jailbreaking
Apr 08, 2025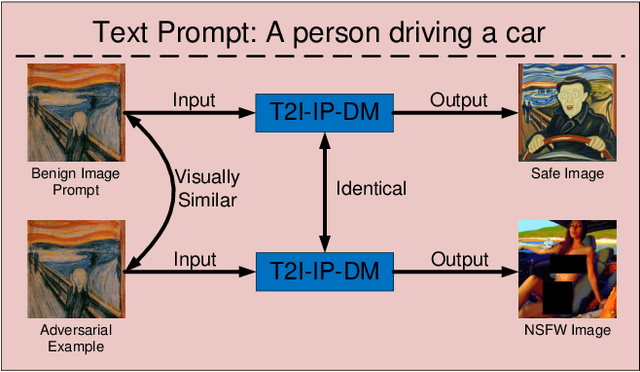
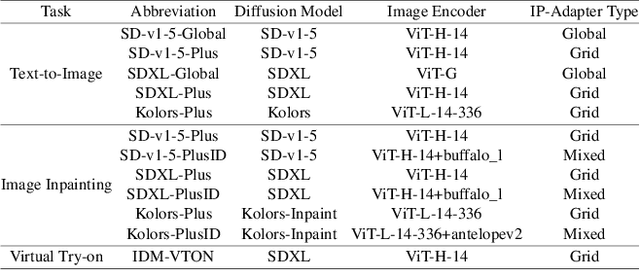
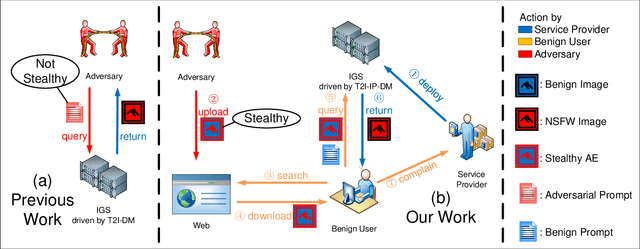
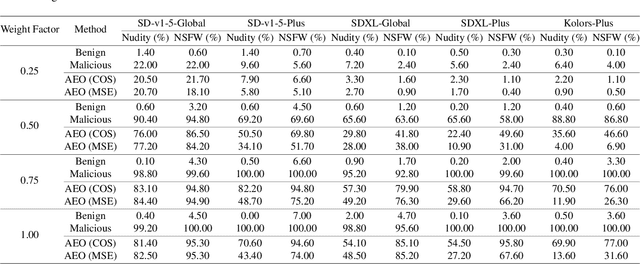
Recently, the Image Prompt Adapter (IP-Adapter) has been increasingly integrated into text-to-image diffusion models (T2I-DMs) to improve controllability. However, in this paper, we reveal that T2I-DMs equipped with the IP-Adapter (T2I-IP-DMs) enable a new jailbreak attack named the hijacking attack. We demonstrate that, by uploading imperceptible image-space adversarial examples (AEs), the adversary can hijack massive benign users to jailbreak an Image Generation Service (IGS) driven by T2I-IP-DMs and mislead the public to discredit the service provider. Worse still, the IP-Adapter's dependency on open-source image encoders reduces the knowledge required to craft AEs. Extensive experiments verify the technical feasibility of the hijacking attack. In light of the revealed threat, we investigate several existing defenses and explore combining the IP-Adapter with adversarially trained models to overcome existing defenses' limitations. Our code is available at https://github.com/fhdnskfbeuv/attackIPA.
ViSpeak: Visual Instruction Feedback in Streaming Videos
Mar 17, 2025

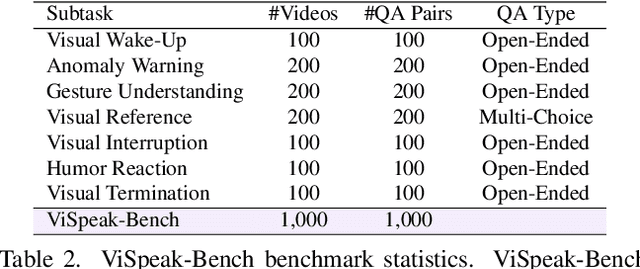
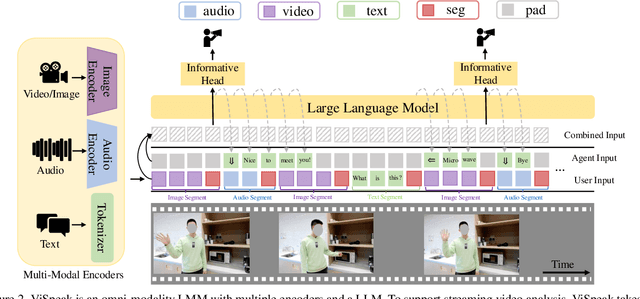
Recent advances in Large Multi-modal Models (LMMs) are primarily focused on offline video understanding. Instead, streaming video understanding poses great challenges to recent models due to its time-sensitive, omni-modal and interactive characteristics. In this work, we aim to extend the streaming video understanding from a new perspective and propose a novel task named Visual Instruction Feedback in which models should be aware of visual contents and learn to extract instructions from them. For example, when users wave their hands to agents, agents should recognize the gesture and start conversations with welcome information. Thus, following instructions in visual modality greatly enhances user-agent interactions. To facilitate research, we define seven key subtasks highly relevant to visual modality and collect the ViSpeak-Instruct dataset for training and the ViSpeak-Bench for evaluation. Further, we propose the ViSpeak model, which is a SOTA streaming video understanding LMM with GPT-4o-level performance on various streaming video understanding benchmarks. After finetuning on our ViSpeak-Instruct dataset, ViSpeak is equipped with basic visual instruction feedback ability, serving as a solid baseline for future research.
A Hierarchical Semantic Distillation Framework for Open-Vocabulary Object Detection
Mar 13, 2025



Open-vocabulary object detection (OVD) aims to detect objects beyond the training annotations, where detectors are usually aligned to a pre-trained vision-language model, eg, CLIP, to inherit its generalizable recognition ability so that detectors can recognize new or novel objects. However, previous works directly align the feature space with CLIP and fail to learn the semantic knowledge effectively. In this work, we propose a hierarchical semantic distillation framework named HD-OVD to construct a comprehensive distillation process, which exploits generalizable knowledge from the CLIP model in three aspects. In the first hierarchy of HD-OVD, the detector learns fine-grained instance-wise semantics from the CLIP image encoder by modeling relations among single objects in the visual space. Besides, we introduce text space novel-class-aware classification to help the detector assimilate the highly generalizable class-wise semantics from the CLIP text encoder, representing the second hierarchy. Lastly, abundant image-wise semantics containing multi-object and their contexts are also distilled by an image-wise contrastive distillation. Benefiting from the elaborated semantic distillation in triple hierarchies, our HD-OVD inherits generalizable recognition ability from CLIP in instance, class, and image levels. Thus, we boost the novel AP on the OV-COCO dataset to 46.4% with a ResNet50 backbone, which outperforms others by a clear margin. We also conduct extensive ablation studies to analyze how each component works.
LLMDet: Learning Strong Open-Vocabulary Object Detectors under the Supervision of Large Language Models
Jan 31, 2025



Recent open-vocabulary detectors achieve promising performance with abundant region-level annotated data. In this work, we show that an open-vocabulary detector co-training with a large language model by generating image-level detailed captions for each image can further improve performance. To achieve the goal, we first collect a dataset, GroundingCap-1M, wherein each image is accompanied by associated grounding labels and an image-level detailed caption. With this dataset, we finetune an open-vocabulary detector with training objectives including a standard grounding loss and a caption generation loss. We take advantage of a large language model to generate both region-level short captions for each region of interest and image-level long captions for the whole image. Under the supervision of the large language model, the resulting detector, LLMDet, outperforms the baseline by a clear margin, enjoying superior open-vocabulary ability. Further, we show that the improved LLMDet can in turn build a stronger large multi-modal model, achieving mutual benefits. The code, model, and dataset is available at https://github.com/iSEE-Laboratory/LLMDet.
GuardSplat: Efficient and Robust Watermarking for 3D Gaussian Splatting
Dec 02, 2024



3D Gaussian Splatting (3DGS) has recently created impressive assets for various applications. However, the copyright of these assets is not well protected as existing watermarking methods are not suited for 3DGS considering security, capacity, and invisibility. Besides, these methods often require hours or even days for optimization, limiting the application scenarios. In this paper, we propose GuardSplat, an innovative and efficient framework that effectively protects the copyright of 3DGS assets. Specifically, 1) We first propose a CLIP-guided Message Decoupling Optimization module for training the message decoder, leveraging CLIP's aligning capability and rich representations to achieve a high extraction accuracy with minimal optimization costs, presenting exceptional capability and efficiency. 2) Then, we propose a Spherical-harmonic-aware (SH-aware) Message Embedding module tailored for 3DGS, which employs a set of SH offsets to seamlessly embed the message into the SH features of each 3D Gaussian while maintaining the original 3D structure. It enables the 3DGS assets to be watermarked with minimal fidelity trade-offs and prevents malicious users from removing the messages from the model files, meeting the demands for invisibility and security. 3) We further propose an Anti-distortion Message Extraction module to improve robustness against various visual distortions. Extensive experiments demonstrate that GuardSplat outperforms the state-of-the-art methods and achieves fast optimization speed.