 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle4D-Bench: A Benchmark Suite for 4D Stylization
Aug 26, 2025We introduce Style4D-Bench, the first benchmark suite specifically designed for 4D stylization, with the goal of standardizing evaluation and facilitating progress in this emerging area. Style4D-Bench comprises: 1) a comprehensive evaluation protocol measuring spatial fidelity, temporal coherence, and multi-view consistency through both perceptual and quantitative metrics, 2) a strong baseline that make an initial attempt for 4D stylization, and 3) a curated collection of high-resolution dynamic 4D scenes with diverse motions and complex backgrounds. To establish a strong baseline, we present Style4D, a novel framework built upon 4D Gaussian Splatting. It consists of three key components: a basic 4DGS scene representation to capture reliable geometry, a Style Gaussian Representation that leverages lightweight per-Gaussian MLPs for temporally and spatially aware appearance control, and a Holistic Geometry-Preserved Style Transfer module designed to enhance spatio-temporal consistency via contrastive coherence learning and structural content preservation. Extensive experiments on Style4D-Bench demonstrate that Style4D achieves state-of-the-art performance in 4D stylization, producing fine-grained stylistic details with stable temporal dynamics and consistent multi-view rendering. We expect Style4D-Bench to become a valuable resource for benchmarking and advancing research in stylized rendering of dynamic 3D scenes. Project page: https://becky-catherine.github.io/Style4D . Code: https://github.com/Becky-catherine/Style4D-Bench .
ObjFiller-3D: Consistent Multi-view 3D Inpainting via Video Diffusion Models
Aug 25, 20253D inpainting often relies on multi-view 2D image inpainting, where the inherent inconsistencies across different inpainted views can result in blurred textures, spatial discontinuities, and distracting visual artifacts. These inconsistencies pose significant challenges when striving for accurate and realistic 3D object completion, particularly in applications that demand high fidelity and structural coherence. To overcome these limitations, we propose ObjFiller-3D, a novel method designed for the completion and editing of high-quality and consistent 3D objects. Instead of employing a conventional 2D image inpainting model, our approach leverages a curated selection of state-of-the-art video editing model to fill in the masked regions of 3D objects. We analyze the representation gap between 3D and videos, and propose an adaptation of a video inpainting model for 3D scene inpainting. In addition, we introduce a reference-based 3D inpainting method to further enhance the quality of reconstruction. Experiments across diverse datasets show that compared to previous methods, ObjFiller-3D produces more faithful and fine-grained reconstructions (PSNR of 26.6 vs. NeRFiller (15.9) and LPIPS of 0.19 vs. Instant3dit (0.25)). Moreover, it demonstrates strong potential for practical deployment in real-world 3D editing applications. Project page: https://objfiller3d.github.io/ Code: https://github.com/objfiller3d/ObjFiller-3D .
Distilled-3DGS:Distilled 3D Gaussian Splatting
Aug 19, 20253D Gaussian Splatting (3DGS) has exhibited remarkable efficacy in novel view synthesis (NVS). However, it suffers from a significant drawback: achieving high-fidelity rendering typically necessitates a large number of 3D Gaussians, resulting in substantial memory consumption and storage requirements. To address this challenge, we propose the first knowledge distillation framework for 3DGS, featuring various teacher models, including vanilla 3DGS, noise-augmented variants, and dropout-regularized versions. The outputs of these teachers are aggregated to guide the optimization of a lightweight student model. To distill the hidden geometric structure, we propose a structural similarity loss to boost the consistency of spatial geometric distributions between the student and teacher model. Through comprehensive quantitative and qualitative evaluations across diverse datasets, the proposed Distilled-3DGS, a simple yet effective framework without bells and whistles, achieves promising rendering results in both rendering quality and storage efficiency compared to state-of-the-art methods. Project page: https://distilled3dgs.github.io . Code: https://github.com/lt-xiang/Distilled-3DGS .
Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency
Mar 26, 2025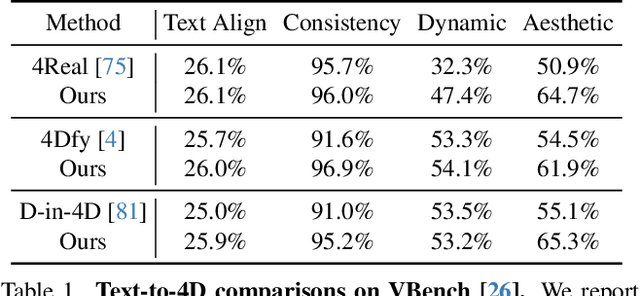
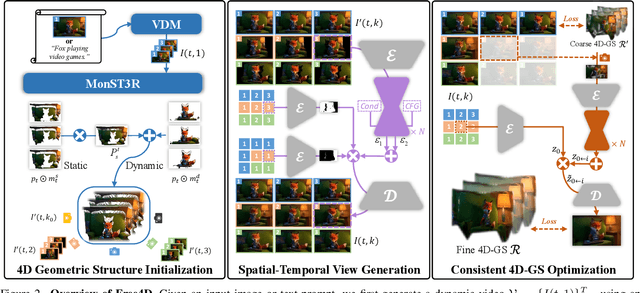
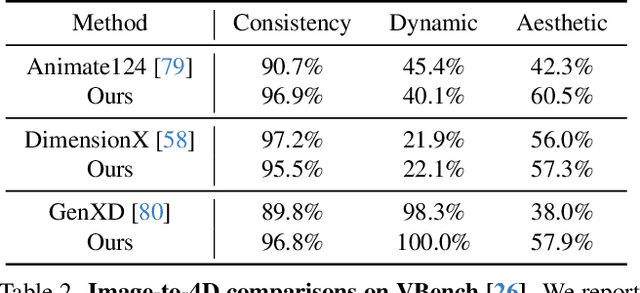

We present Free4D, a novel tuning-free framework for 4D scene generation from a single image. Existing methods either focus on object-level generation, making scene-level generation infeasible, or rely on large-scale multi-view video datasets for expensive training, with limited generalization ability due to the scarcity of 4D scene data. In contrast, our key insight is to distill pre-trained foundation models for consistent 4D scene representation, which offers promising advantages such as efficiency and generalizability. 1) To achieve this, we first animate the input image using image-to-video diffusion models followed by 4D geometric structure initialization. 2) To turn this coarse structure into spatial-temporal consistent multiview videos, we design an adaptive guidance mechanism with a point-guided denoising strategy for spatial consistency and a novel latent replacement strategy for temporal coherence. 3) To lift these generated observations into consistent 4D representation, we propose a modulation-based refinement to mitigate inconsistencies while fully leveraging the generated information. The resulting 4D representation enables real-time, controllable rendering, marking a significant advancement in single-image-based 4D scene generation.
DiffV2IR: Visible-to-Infrared Diffusion Model via Vision-Language Understanding
Mar 24, 2025

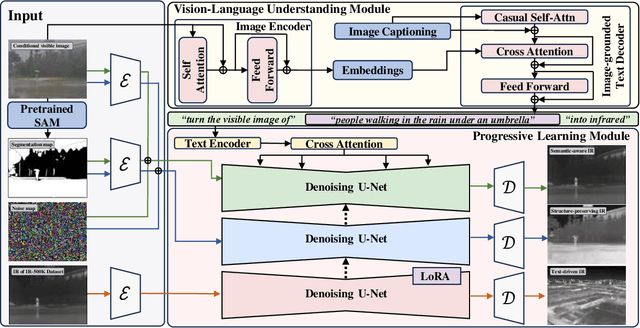
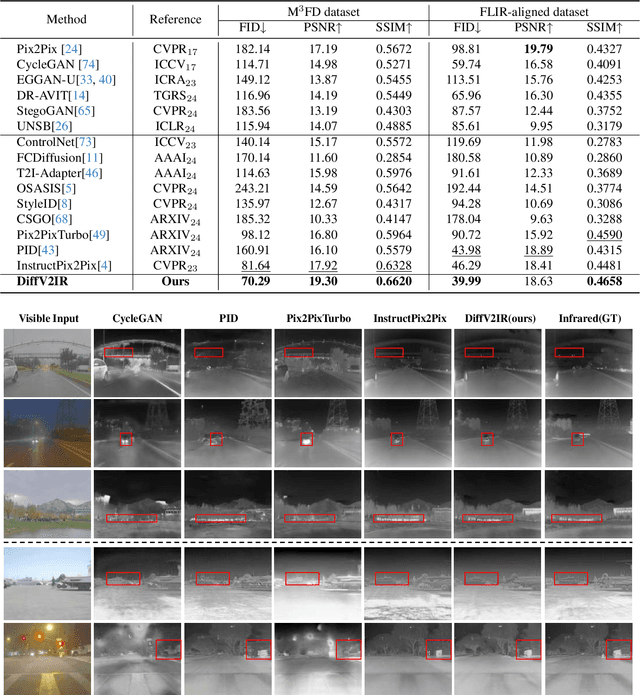
The task of translating visible-to-infrared images (V2IR) is inherently challenging due to three main obstacles: 1) achieving semantic-aware translation, 2) managing the diverse wavelength spectrum in infrared imagery, and 3) the scarcity of comprehensive infrared datasets. Current leading methods tend to treat V2IR as a conventional image-to-image synthesis challenge, often overlooking these specific issues. To address this, we introduce DiffV2IR, a novel framework for image translation comprising two key elements: a Progressive Learning Module (PLM) and a Vision-Language Understanding Module (VLUM). PLM features an adaptive diffusion model architecture that leverages multi-stage knowledge learning to infrared transition from full-range to target wavelength. To improve V2IR translation, VLUM incorporates unified Vision-Language Understanding. We also collected a large infrared dataset, IR-500K, which includes 500,000 infrared images compiled by various scenes and objects under various environmental conditions. Through the combination of PLM, VLUM, and the extensive IR-500K dataset, DiffV2IR markedly improves the performance of V2IR. Experiments validate DiffV2IR's excellence in producing high-quality translations, establishing its efficacy and broad applicability. The code, dataset, and DiffV2IR model will be available at https://github.com/LidongWang-26/DiffV2IR.
HLV-1K: A Large-scale Hour-Long Video Benchmark for Time-Specific Long Video Understanding
Jan 03, 2025



Multimodal large language models have become a popular topic in deep visual understanding due to many promising real-world applications. However, hour-long video understanding, spanning over one hour and containing tens of thousands of visual frames, remains under-explored because of 1) challenging long-term video analyses, 2) inefficient large-model approaches, and 3) lack of large-scale benchmark datasets. Among them, in this paper, we focus on building a large-scale hour-long long video benchmark, HLV-1K, designed to evaluate long video understanding models. HLV-1K comprises 1009 hour-long videos with 14,847 high-quality question answering (QA) and multi-choice question asnwering (MCQA) pairs with time-aware query and diverse annotations, covering frame-level, within-event-level, cross-event-level, and long-term reasoning tasks. We evaluate our benchmark using existing state-of-the-art methods and demonstrate its value for testing deep long video understanding capabilities at different levels and for various tasks. This includes promoting future long video understanding tasks at a granular level, such as deep understanding of long live videos, meeting recordings, and movies.
GuardSplat: Efficient and Robust Watermarking for 3D Gaussian Splatting
Dec 02, 2024



3D Gaussian Splatting (3DGS) has recently created impressive assets for various applications. However, the copyright of these assets is not well protected as existing watermarking methods are not suited for 3DGS considering security, capacity, and invisibility. Besides, these methods often require hours or even days for optimization, limiting the application scenarios. In this paper, we propose GuardSplat, an innovative and efficient framework that effectively protects the copyright of 3DGS assets. Specifically, 1) We first propose a CLIP-guided Message Decoupling Optimization module for training the message decoder, leveraging CLIP's aligning capability and rich representations to achieve a high extraction accuracy with minimal optimization costs, presenting exceptional capability and efficiency. 2) Then, we propose a Spherical-harmonic-aware (SH-aware) Message Embedding module tailored for 3DGS, which employs a set of SH offsets to seamlessly embed the message into the SH features of each 3D Gaussian while maintaining the original 3D structure. It enables the 3DGS assets to be watermarked with minimal fidelity trade-offs and prevents malicious users from removing the messages from the model files, meeting the demands for invisibility and security. 3) We further propose an Anti-distortion Message Extraction module to improve robustness against various visual distortions. Extensive experiments demonstrate that GuardSplat outperforms the state-of-the-art methods and achieves fast optimization speed.
From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding
Sep 27, 2024



The integration of Large Language Models (LLMs) with visual encoders has recently shown promising performance in visual understanding tasks, leveraging their inherent capability to comprehend and generate human-like text for visual reasoning. Given the diverse nature of visual data, MultiModal Large Language Models (MM-LLMs) exhibit variations in model designing and training for understanding images, short videos, and long videos. Our paper focuses on the substantial differences and unique challenges posed by long video understanding compared to static image and short video understanding. Unlike static images, short videos encompass sequential frames with both spatial and within-event temporal information, while long videos consist of multiple events with between-event and long-term temporal information. In this survey, we aim to trace and summarize the advancements of MM-LLMs from image understanding to long video understanding. We review the differences among various visual understanding tasks and highlight the challenges in long video understanding, including more fine-grained spatiotemporal details, dynamic events, and long-term dependencies. We then provide a detailed summary of the advancements in MM-LLMs in terms of model design and training methodologies for understanding long videos. Finally, we compare the performance of existing MM-LLMs on video understanding benchmarks of various lengths and discuss potential future directions for MM-LLMs in long video understanding.
Text-based Talking Video Editing with Cascaded Conditional Diffusion
Jul 20, 2024
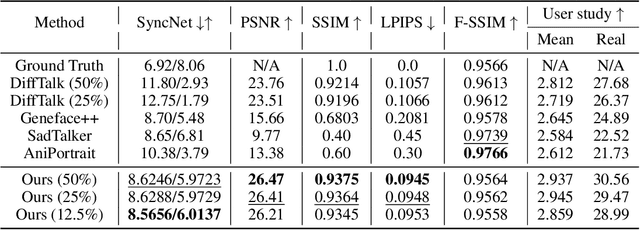


Text-based talking-head video editing aims to efficiently insert, delete, and substitute segments of talking videos through a user-friendly text editing approach. It is challenging because of \textbf{1)} generalizable talking-face representation, \textbf{2)} seamless audio-visual transitions, and \textbf{3)} identity-preserved talking faces. Previous works either require minutes of talking-face video training data and expensive test-time optimization for customized talking video editing or directly generate a video sequence without considering in-context information, leading to a poor generalizable representation, or incoherent transitions, or even inconsistent identity. In this paper, we propose an efficient cascaded conditional diffusion-based framework, which consists of two stages: audio to dense-landmark motion and motion to video. \textit{\textbf{In the first stage}}, we first propose a dynamic weighted in-context diffusion module to synthesize dense-landmark motions given an edited audio. \textit{\textbf{In the second stage}}, we introduce a warping-guided conditional diffusion module. The module first interpolates between the start and end frames of the editing interval to generate smooth intermediate frames. Then, with the help of the audio-to-dense motion images, these intermediate frames are warped to obtain coarse intermediate frames. Conditioned on the warped intermedia frames, a diffusion model is adopted to generate detailed and high-resolution target frames, which guarantees coherent and identity-preserved transitions. The cascaded conditional diffusion model decomposes the complex talking editing task into two flexible generation tasks, which provides a generalizable talking-face representation, seamless audio-visual transitions, and identity-preserved faces on a small dataset. Experiments show the effectiveness and superiority of the proposed method.
WildAvatar: Web-scale In-the-wild Video Dataset for 3D Avatar Creation
Jul 02, 2024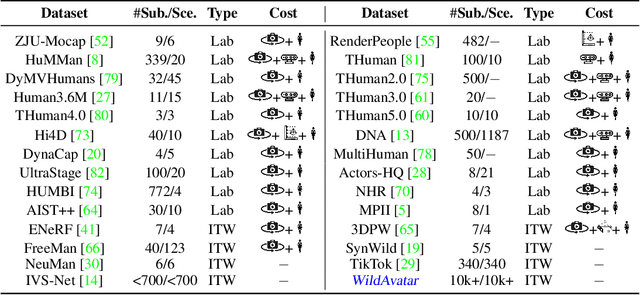
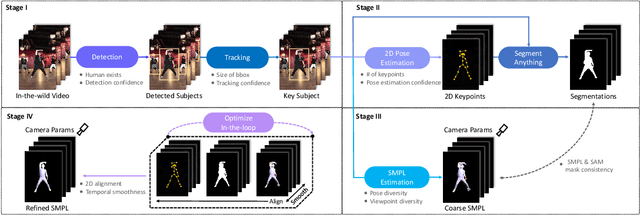


Existing human datasets for avatar creation are typically limited to laboratory environments, wherein high-quality annotations (e.g., SMPL estimation from 3D scans or multi-view images) can be ideally provided. However, their annotating requirements are impractical for real-world images or videos, posing challenges toward real-world applications on current avatar creation methods. To this end, we propose the WildAvatar dataset, a web-scale in-the-wild human avatar creation dataset extracted from YouTube, with $10,000+$ different human subjects and scenes. WildAvatar is at least $10\times$ richer than previous datasets for 3D human avatar creation. We evaluate several state-of-the-art avatar creation methods on our dataset, highlighting the unexplored challenges in real-world applications on avatar creation. We also demonstrate the potential for generalizability of avatar creation methods, when provided with data at scale. We will publicly release our data source links and annotations, to push forward 3D human avatar creation and other related fields for real-world applications.