 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiLong-Shot: Interaction-Aware One-Shot Imitation Learning for Long-Horizon Manipulation
Dec 18, 2025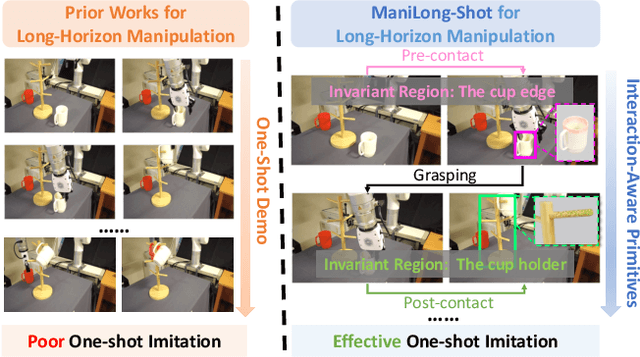

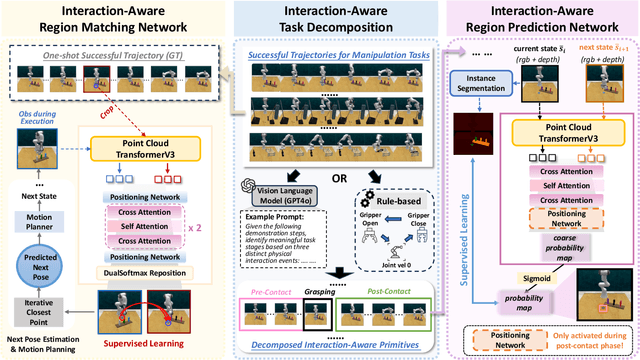
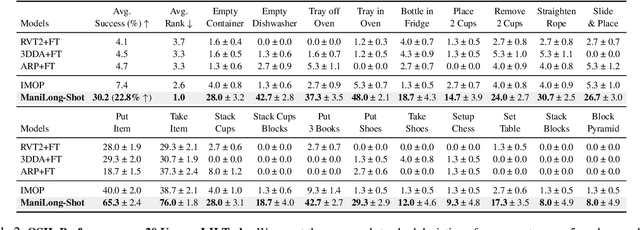
One-shot imitation learning (OSIL) offers a promising way to teach robots new skills without large-scale data collection. However, current OSIL methods are primarily limited to short-horizon tasks, thus limiting their applicability to complex, long-horizon manipulations. To address this limitation, we propose ManiLong-Shot, a novel framework that enables effective OSIL for long-horizon prehensile manipulation tasks. ManiLong-Shot structures long-horizon tasks around physical interaction events, reframing the problem as sequencing interaction-aware primitives instead of directly imitating continuous trajectories. This primitive decomposition can be driven by high-level reasoning from a vision-language model (VLM) or by rule-based heuristics derived from robot state changes. For each primitive, ManiLong-Shot predicts invariant regions critical to the interaction, establishes correspondences between the demonstration and the current observation, and computes the target end-effector pose, enabling effective task execution. Extensive simulation experiments show that ManiLong-Shot, trained on only 10 short-horizon tasks, generalizes to 20 unseen long-horizon tasks across three difficulty levels via one-shot imitation, achieving a 22.8% relative improvement over the SOTA. Additionally, real-robot experiments validate ManiLong-Shot's ability to robustly execute three long-horizon manipulation tasks via OSIL, confirming its practical applicability.
Towards Fine-Grained Recognition with Large Visual Language Models: Benchmark and Optimization Strategies
Dec 11, 2025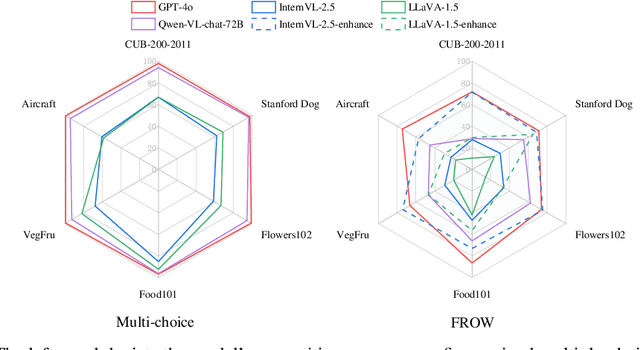



Large Vision Language Models (LVLMs) have made remarkable progress, enabling sophisticated vision-language interaction and dialogue applications. However, existing benchmarks primarily focus on reasoning tasks, often neglecting fine-grained recognition, which is crucial for practical application scenarios. To address this gap, we introduce the Fine-grained Recognition Open World (FROW) benchmark, designed for detailed evaluation of LVLMs with GPT-4o. On the basis of that, we propose a novel optimization strategy from two perspectives: \textit{data construction} and \textit{training process}, to improve the performance of LVLMs. Our dataset includes mosaic data, which combines multiple short-answer responses, and open-world data, generated from real-world questions and answers using GPT-4o, creating a comprehensive framework for evaluating fine-grained recognition in LVLMs. Experiments show that mosaic data improves category recognition accuracy by 1\% and open-world data boosts FROW benchmark accuracy by 10\%-20\% and content accuracy by 6\%-12\%. Meanwhile, incorporating fine-grained data into the pre-training phase can improve the model's category recognition accuracy by up to 10\%. The benchmark will be available at https://github.com/pc-inno/FROW.
LISN: Language-Instructed Social Navigation with VLM-based Controller Modulating
Dec 10, 2025Towards human-robot coexistence, socially aware navigation is significant for mobile robots. Yet existing studies on this area focus mainly on path efficiency and pedestrian collision avoidance, which are essential but represent only a fraction of social navigation. Beyond these basics, robots must also comply with user instructions, aligning their actions to task goals and social norms expressed by humans. In this work, we present LISN-Bench, the first simulation-based benchmark for language-instructed social navigation. Built on Rosnav-Arena 3.0, it is the first standardized social navigation benchmark to incorporate instruction following and scene understanding across diverse contexts. To address this task, we further propose Social-Nav-Modulator, a fast-slow hierarchical system where a VLM agent modulates costmaps and controller parameters. Decoupling low-level action generation from the slower VLM loop reduces reliance on high-frequency VLM inference while improving dynamic avoidance and perception adaptability. Our method achieves an average success rate of 91.3%, which is greater than 63% than the most competitive baseline, with most of the improvements observed in challenging tasks such as following a person in a crowd and navigating while strictly avoiding instruction-forbidden regions. The project website is at: https://social-nav.github.io/LISN-project/
AdaptPNP: Integrating Prehensile and Non-Prehensile Skills for Adaptive Robotic Manipulation
Nov 14, 2025Non-prehensile (NP) manipulation, in which robots alter object states without forming stable grasps (for example, pushing, poking, or sliding), significantly broadens robotic manipulation capabilities when grasping is infeasible or insufficient. However, enabling a unified framework that generalizes across different tasks, objects, and environments while seamlessly integrating non-prehensile and prehensile (P) actions remains challenging: robots must determine when to invoke NP skills, select the appropriate primitive for each context, and compose P and NP strategies into robust, multi-step plans. We introduce ApaptPNP, a vision-language model (VLM)-empowered task and motion planning framework that systematically selects and combines P and NP skills to accomplish diverse manipulation objectives. Our approach leverages a VLM to interpret visual scene observations and textual task descriptions, generating a high-level plan skeleton that prescribes the sequence and coordination of P and NP actions. A digital-twin based object-centric intermediate layer predicts desired object poses, enabling proactive mental rehearsal of manipulation sequences. Finally, a control module synthesizes low-level robot commands, with continuous execution feedback enabling online task plan refinement and adaptive replanning through the VLM. We evaluate ApaptPNP across representative P&NP hybrid manipulation tasks in both simulation and real-world environments. These results underscore the potential of hybrid P&NP manipulation as a crucial step toward general-purpose, human-level robotic manipulation capabilities. Project Website: https://sites.google.com/view/adaptpnp/home
ConCM: Consistency-Driven Calibration and Matching for Few-Shot Class-Incremental Learning
Jun 24, 2025Few-Shot Class-Incremental Learning (FSCIL) requires models to adapt to novel classes with limited supervision while preserving learned knowledge. Existing prospective learning-based space construction methods reserve space to accommodate novel classes. However, prototype deviation and structure fixity limit the expressiveness of the embedding space. In contrast to fixed space reservation, we explore the optimization of feature-structure dual consistency and propose a Consistency-driven Calibration and Matching Framework (ConCM) that systematically mitigate the knowledge conflict inherent in FSCIL. Specifically, inspired by hippocampal associative memory, we design a memory-aware prototype calibration that extracts generalized semantic attributes from base classes and reintegrates them into novel classes to enhance the conceptual center consistency of features. Further, we propose dynamic structure matching, which adaptively aligns the calibrated features to a session-specific optimal manifold space, ensuring cross-session structure consistency. Theoretical analysis shows that our method satisfies both geometric optimality and maximum matching, thereby overcoming the need for class-number priors. On large-scale FSCIL benchmarks including mini-ImageNet and CUB200, ConCM achieves state-of-the-art performance, surpassing current optimal method by 3.20% and 3.68% in harmonic accuracy of incremental sessions.
GMT: General Motion Tracking for Humanoid Whole-Body Control
Jun 17, 2025The ability to track general whole-body motions in the real world is a useful way to build general-purpose humanoid robots. However, achieving this can be challenging due to the temporal and kinematic diversity of the motions, the policy's capability, and the difficulty of coordination of the upper and lower bodies. To address these issues, we propose GMT, a general and scalable motion-tracking framework that trains a single unified policy to enable humanoid robots to track diverse motions in the real world. GMT is built upon two core components: an Adaptive Sampling strategy and a Motion Mixture-of-Experts (MoE) architecture. The Adaptive Sampling automatically balances easy and difficult motions during training. The MoE ensures better specialization of different regions of the motion manifold. We show through extensive experiments in both simulation and the real world the effectiveness of GMT, achieving state-of-the-art performance across a broad spectrum of motions using a unified general policy. Videos and additional information can be found at https://gmt-humanoid.github.io.
GhostPrompt: Jailbreaking Text-to-image Generative Models based on Dynamic Optimization
May 25, 2025Text-to-image (T2I) generation models can inadvertently produce not-safe-for-work (NSFW) content, prompting the integration of text and image safety filters. Recent advances employ large language models (LLMs) for semantic-level detection, rendering traditional token-level perturbation attacks largely ineffective. However, our evaluation shows that existing jailbreak methods are ineffective against these modern filters. We introduce GhostPrompt, the first automated jailbreak framework that combines dynamic prompt optimization with multimodal feedback. It consists of two key components: (i) Dynamic Optimization, an iterative process that guides a large language model (LLM) using feedback from text safety filters and CLIP similarity scores to generate semantically aligned adversarial prompts; and (ii) Adaptive Safety Indicator Injection, which formulates the injection of benign visual cues as a reinforcement learning problem to bypass image-level filters. GhostPrompt achieves state-of-the-art performance, increasing the ShieldLM-7B bypass rate from 12.5\% (Sneakyprompt) to 99.0\%, improving CLIP score from 0.2637 to 0.2762, and reducing the time cost by $4.2 \times$. Moreover, it generalizes to unseen filters including GPT-4.1 and successfully jailbreaks DALLE 3 to generate NSFW images in our evaluation, revealing systemic vulnerabilities in current multimodal defenses. To support further research on AI safety and red-teaming, we will release code and adversarial prompts under a controlled-access protocol.
TWIST: Teleoperated Whole-Body Imitation System
May 05, 2025Teleoperating humanoid robots in a whole-body manner marks a fundamental step toward developing general-purpose robotic intelligence, with human motion providing an ideal interface for controlling all degrees of freedom. Yet, most current humanoid teleoperation systems fall short of enabling coordinated whole-body behavior, typically limiting themselves to isolated locomotion or manipulation tasks. We present the Teleoperated Whole-Body Imitation System (TWIST), a system for humanoid teleoperation through whole-body motion imitation. We first generate reference motion clips by retargeting human motion capture data to the humanoid robot. We then develop a robust, adaptive, and responsive whole-body controller using a combination of reinforcement learning and behavior cloning (RL+BC). Through systematic analysis, we demonstrate how incorporating privileged future motion frames and real-world motion capture (MoCap) data improves tracking accuracy. TWIST enables real-world humanoid robots to achieve unprecedented, versatile, and coordinated whole-body motor skills--spanning whole-body manipulation, legged manipulation, locomotion, and expressive movement--using a single unified neural network controller. Our project website: https://humanoid-teleop.github.io
DeCo: Task Decomposition and Skill Composition for Zero-Shot Generalization in Long-Horizon 3D Manipulation
May 01, 2025Generalizing language-conditioned multi-task imitation learning (IL) models to novel long-horizon 3D manipulation tasks remains a significant challenge. To address this, we propose DeCo (Task Decomposition and Skill Composition), a model-agnostic framework compatible with various multi-task IL models, designed to enhance their zero-shot generalization to novel, compositional, long-horizon 3D manipulation tasks. DeCo first decomposes IL demonstrations into a set of modular atomic tasks based on the physical interaction between the gripper and objects, and constructs an atomic training dataset that enables models to learn a diverse set of reusable atomic skills during imitation learning. At inference time, DeCo leverages a vision-language model (VLM) to parse high-level instructions for novel long-horizon tasks, retrieve the relevant atomic skills, and dynamically schedule their execution; a spatially-aware skill-chaining module then ensures smooth, collision-free transitions between sequential skills. We evaluate DeCo in simulation using DeCoBench, a benchmark specifically designed to assess zero-shot generalization of multi-task IL models in compositional long-horizon 3D manipulation. Across three representative multi-task IL models (RVT-2, 3DDA, and ARP), DeCo achieves success rate improvements of 66.67%, 21.53%, and 57.92%, respectively, on 12 novel compositional tasks. Moreover, in real-world experiments, a DeCo-enhanced model trained on only 6 atomic tasks successfully completes 9 novel long-horizon tasks, yielding an average success rate improvement of 53.33% over the base multi-task IL model. Video demonstrations are available at: https://deco226.github.io.
G-DexGrasp: Generalizable Dexterous Grasping Synthesis Via Part-Aware Prior Retrieval and Prior-Assisted Generation
Mar 25, 2025



Recent advances in dexterous grasping synthesis have demonstrated significant progress in producing reasonable and plausible grasps for many task purposes. But it remains challenging to generalize to unseen object categories and diverse task instructions. In this paper, we propose G-DexGrasp, a retrieval-augmented generation approach that can produce high-quality dexterous hand configurations for unseen object categories and language-based task instructions. The key is to retrieve generalizable grasping priors, including the fine-grained contact part and the affordance-related distribution of relevant grasping instances, for the following synthesis pipeline. Specifically, the fine-grained contact part and affordance act as generalizable guidance to infer reasonable grasping configurations for unseen objects with a generative model, while the relevant grasping distribution plays as regularization to guarantee the plausibility of synthesized grasps during the subsequent refinement optimization. Our comparison experiments validate the effectiveness of our key designs for generalization and demonstrate the remarkable performance against the existing approaches. Project page: https://g-dexgrasp.github.io/