 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashVSR: Towards Real-Time Diffusion-Based Streaming Video Super-Resolution
Oct 14, 2025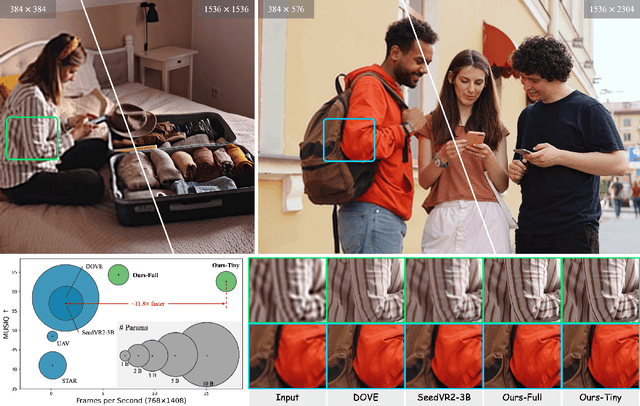
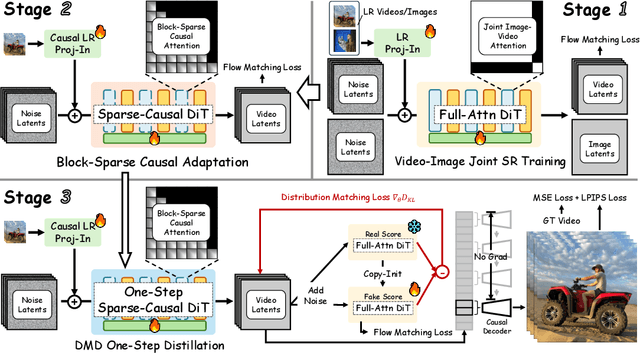
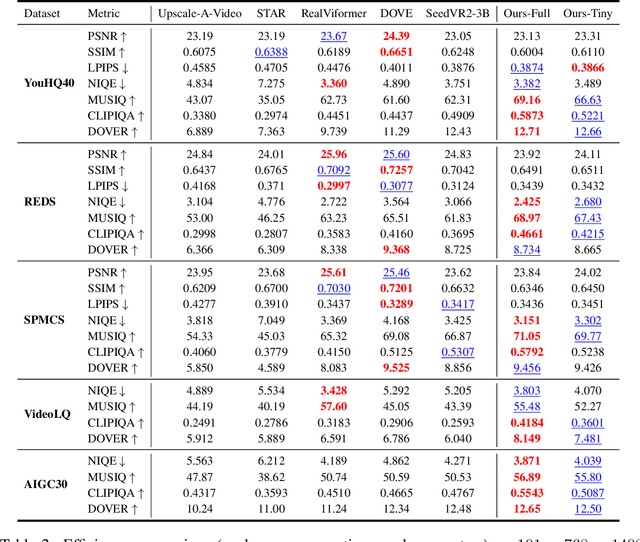
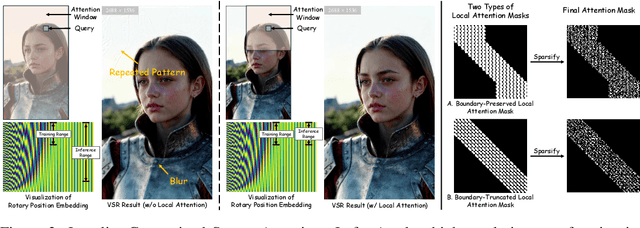
Diffusion models have recently advanced video restoration, but applying them to real-world video super-resolution (VSR) remains challenging due to high latency, prohibitive computation, and poor generalization to ultra-high resolutions. Our goal in this work is to make diffusion-based VSR practical by achieving efficiency, scalability, and real-time performance. To this end, we propose FlashVSR, the first diffusion-based one-step streaming framework towards real-time VSR. FlashVSR runs at approximately 17 FPS for 768x1408 videos on a single A100 GPU by combining three complementary innovations: (i) a train-friendly three-stage distillation pipeline that enables streaming super-resolution, (ii) locality-constrained sparse attention that cuts redundant computation while bridging the train-test resolution gap, and (iii) a tiny conditional decoder that accelerates reconstruction without sacrificing quality. To support large-scale training, we also construct VSR-120K, a new dataset with 120k videos and 180k images. Extensive experiments show that FlashVSR scales reliably to ultra-high resolutions and achieves state-of-the-art performance with up to 12x speedup over prior one-step diffusion VSR models. We will release the code, pretrained models, and dataset to foster future research in efficient diffusion-based VSR.
EvMic: Event-based Non-contact sound recovery from effective spatial-temporal modeling
Apr 03, 2025When sound waves hit an object, they induce vibrations that produce high-frequency and subtle visual changes, which can be used for recovering the sound. Early studies always encounter trade-offs related to sampling rate, bandwidth, field of view, and the simplicity of the optical path. Recent advances in event camera hardware show good potential for its application in visual sound recovery, because of its superior ability in capturing high-frequency signals. However, existing event-based vibration recovery methods are still sub-optimal for sound recovery. In this work, we propose a novel pipeline for non-contact sound recovery, fully utilizing spatial-temporal information from the event stream. We first generate a large training set using a novel simulation pipeline. Then we designed a network that leverages the sparsity of events to capture spatial information and uses Mamba to model long-term temporal information. Lastly, we train a spatial aggregation block to aggregate information from different locations to further improve signal quality. To capture event signals caused by sound waves, we also designed an imaging system using a laser matrix to enhance the gradient and collected multiple data sequences for testing. Experimental results on synthetic and real-world data demonstrate the effectiveness of our method.
EGVD: Event-Guided Video Diffusion Model for Physically Realistic Large-Motion Frame Interpolation
Mar 26, 2025Video frame interpolation (VFI) in scenarios with large motion remains challenging due to motion ambiguity between frames. While event cameras can capture high temporal resolution motion information, existing event-based VFI methods struggle with limited training data and complex motion patterns. In this paper, we introduce Event-Guided Video Diffusion Model (EGVD), a novel framework that leverages the powerful priors of pre-trained stable video diffusion models alongside the precise temporal information from event cameras. Our approach features a Multi-modal Motion Condition Generator (MMCG) that effectively integrates RGB frames and event signals to guide the diffusion process, producing physically realistic intermediate frames. We employ a selective fine-tuning strategy that preserves spatial modeling capabilities while efficiently incorporating event-guided temporal information. We incorporate input-output normalization techniques inspired by recent advances in diffusion modeling to enhance training stability across varying noise levels. To improve generalization, we construct a comprehensive dataset combining both real and simulated event data across diverse scenarios. Extensive experiments on both real and simulated datasets demonstrate that EGVD significantly outperforms existing methods in handling large motion and challenging lighting conditions, achieving substantial improvements in perceptual quality metrics (27.4% better LPIPS on Prophesee and 24.1% on BSRGB) while maintaining competitive fidelity measures. Code and datasets available at: https://github.com/OpenImagingLab/EGVD.
UltraFusion: Ultra High Dynamic Imaging using Exposure Fusion
Jan 20, 2025



Capturing high dynamic range (HDR) scenes is one of the most important issues in camera design. Majority of cameras use exposure fusion technique, which fuses images captured by different exposure levels, to increase dynamic range. However, this approach can only handle images with limited exposure difference, normally 3-4 stops. When applying to very high dynamic scenes where a large exposure difference is required, this approach often fails due to incorrect alignment or inconsistent lighting between inputs, or tone mapping artifacts. In this work, we propose UltraFusion, the first exposure fusion technique that can merge input with 9 stops differences. The key idea is that we model the exposure fusion as a guided inpainting problem, where the under-exposed image is used as a guidance to fill the missing information of over-exposed highlight in the over-exposed region. Using under-exposed image as a soft guidance, instead of a hard constrain, our model is robust to potential alignment issue or lighting variations. Moreover, utilizing the image prior of the generative model, our model also generates natural tone mapping, even for very high-dynamic range scene. Our approach outperforms HDR-Transformer on latest HDR benchmarks. Moreover, to test its performance in ultra high dynamic range scene, we capture a new real-world exposure fusion benchmark, UltraFusion Dataset, with exposure difference up to 9 stops, and experiments show that \model~can generate beautiful and high-quality fusion results under various scenarios. An online demo is provided at https://openimaginglab.github.io/UltraFusion/.
Event-assisted 12-stop HDR Imaging of Dynamic Scene
Dec 19, 2024



High dynamic range (HDR) imaging is a crucial task in computational photography, which captures details across diverse lighting conditions. Traditional HDR fusion methods face limitations in dynamic scenes with extreme exposure differences, as aligning low dynamic range (LDR) frames becomes challenging due to motion and brightness variation. In this work, we propose a novel 12-stop HDR imaging approach for dynamic scenes, leveraging a dual-camera system with an event camera and an RGB camera. The event camera provides temporally dense, high dynamic range signals that improve alignment between LDR frames with large exposure differences, reducing ghosting artifacts caused by motion. Also, a real-world finetuning strategy is proposed to increase the generalization of alignment module on real-world events. Additionally, we introduce a diffusion-based fusion module that incorporates image priors from pre-trained diffusion models to address artifacts in high-contrast regions and minimize errors from the alignment process. To support this work, we developed the ESHDR dataset, the first dataset for 12-stop HDR imaging with synchronized event signals, and validated our approach on both simulated and real-world data. Extensive experiments demonstrate that our method achieves state-of-the-art performance, successfully extending HDR imaging to 12 stops in dynamic scenes.
From Sim-to-Real: Toward General Event-based Low-light Frame Interpolation with Per-scene Optimization
Jun 12, 2024Video Frame Interpolation (VFI) is important for video enhancement, frame rate up-conversion, and slow-motion generation. The introduction of event cameras, which capture per-pixel brightness changes asynchronously, has significantly enhanced VFI capabilities, particularly for high-speed, nonlinear motions. However, these event-based methods encounter challenges in low-light conditions, notably trailing artifacts and signal latency, which hinder their direct applicability and generalization. Addressing these issues, we propose a novel per-scene optimization strategy tailored for low-light conditions. This approach utilizes the internal statistics of a sequence to handle degraded event data under low-light conditions, improving the generalizability to different lighting and camera settings. To evaluate its robustness in low-light condition, we further introduce EVFI-LL, a unique RGB+Event dataset captured under low-light conditions. Our results demonstrate state-of-the-art performance in low-light environments. Both the dataset and the source code will be made publicly available upon publication. Project page: https://naturezhanghn.github.io/sim2real.
Event-Based Motion Magnification
Feb 19, 2024



Detecting and magnifying imperceptible high-frequency motions in real-world scenarios has substantial implications for industrial and medical applications. These motions are characterized by small amplitudes and high frequencies. Traditional motion magnification methods rely on costly high-speed cameras or active light sources, which limit the scope of their applications. In this work, we propose a dual-camera system consisting of an event camera and a conventional RGB camera for video motion magnification, containing temporally-dense information from the event stream and spatially-dense data from the RGB images. This innovative combination enables a broad and cost-effective amplification of high-frequency motions. By revisiting the physical camera model, we observe that estimating motion direction and magnitude necessitates the integration of event streams with additional image features. On this basis, we propose a novel deep network for event-based video motion magnification that addresses two primary challenges: firstly, the high frequency of motion induces a large number of interpolated frames (up to 80), which our network mitigates with a Second-order Recurrent Propagation module for better handling of long-term frame interpolations; and secondly, magnifying subtle motions is sensitive to noise, which we address by utilizing a temporal filter to amplify motion at specific frequencies and reduce noise impact. We demonstrate the effectiveness and accuracy of our dual-camera system and network through extensive experiments in magnifying small-amplitude, high-frequency motions, offering a cost-effective and flexible solution for motion detection and magnification.
Toward Accurate and Temporally Consistent Video Restoration from Raw Data
Dec 25, 2023Denoising and demosaicking are two fundamental steps in reconstructing a clean full-color video from raw data, while performing video denoising and demosaicking jointly, namely VJDD, could lead to better video restoration performance than performing them separately. In addition to restoration accuracy, another key challenge to VJDD lies in the temporal consistency of consecutive frames. This issue exacerbates when perceptual regularization terms are introduced to enhance video perceptual quality. To address these challenges, we present a new VJDD framework by consistent and accurate latent space propagation, which leverages the estimation of previous frames as prior knowledge to ensure consistent recovery of the current frame. A data temporal consistency (DTC) loss and a relational perception consistency (RPC) loss are accordingly designed. Compared with the commonly used flow-based losses, the proposed losses can circumvent the error accumulation problem caused by inaccurate flow estimation and effectively handle intensity changes in videos, improving much the temporal consistency of output videos while preserving texture details. Extensive experiments demonstrate the leading VJDD performance of our method in term of restoration accuracy, perceptual quality and temporal consistency. Codes and dataset are available at \url{https://github.com/GuoShi28/VJDD}.
TMP: Temporal Motion Propagation for Online Video Super-Resolution
Dec 18, 2023



Online video super-resolution (online-VSR) highly relies on an effective alignment module to aggregate temporal information, while the strict latency requirement makes accurate and efficient alignment very challenging. Though much progress has been achieved, most of the existing online-VSR methods estimate the motion fields of each frame separately to perform alignment, which is computationally redundant and ignores the fact that the motion fields of adjacent frames are correlated. In this work, we propose an efficient Temporal Motion Propagation (TMP) method, which leverages the continuity of motion field to achieve fast pixel-level alignment among consecutive frames. Specifically, we first propagate the offsets from previous frames to the current frame, and then refine them in the neighborhood, which significantly reduces the matching space and speeds up the offset estimation process. Furthermore, to enhance the robustness of alignment, we perform spatial-wise weighting on the warped features, where the positions with more precise offsets are assigned higher importance. Experiments on benchmark datasets demonstrate that the proposed TMP method achieves leading online-VSR accuracy as well as inference speed. The source code of TMP can be found at https://github.com/xtudbxk/TMP.
Spatial-Frequency Attention for Image Denoising
Feb 27, 2023The recently developed transformer networks have achieved impressive performance in image denoising by exploiting the self-attention (SA) in images. However, the existing methods mostly use a relatively small window to compute SA due to the quadratic complexity of it, which limits the model's ability to model long-term image information. In this paper, we propose the spatial-frequency attention network (SFANet) to enhance the network's ability in exploiting long-range dependency. For spatial attention module (SAM), we adopt dilated SA to model long-range dependency. In the frequency attention module (FAM), we exploit more global information by using Fast Fourier Transform (FFT) by designing a window-based frequency channel attention (WFCA) block to effectively model deep frequency features and their dependencies. To make our module applicable to images of different sizes and keep the model consistency between training and inference, we apply window-based FFT with a set of fixed window sizes. In addition, channel attention is computed on both real and imaginary parts of the Fourier spectrum, which further improves restoration performance. The proposed WFCA block can effectively model image long-range dependency with acceptable complexity. Experiments on multiple denoising benchmarks demonstrate the leading performance of SFANet network.