 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenClawBench: Benchmarking Process-side Anomalies in Real-world Agent Execution Trajectories
May 28, 2026Task success can hide process anomalies in real-world agent executions. An agent may pass the final task oracle while still accumulating unresolved ambiguity, unsafe external writes, ignored errors, weakly grounded commitments, or capability-boundary overcommitment. We study this mismatch as the Outcome-Process Gap and introduce OpenClawBench, a large-scale dataset for measuring and supervising process-side anomalies in real agent execution processes. OpenClawBench is built from BFCL-driven OpenClaw sessions produced by 6 source models and contains 31,264 annotated trajectories. It aligns task-oracle outcomes with structured process evidence. FullTax converts the aligned trajectories into structured anomaly supervision: binary labels, supporting evidence, onset/span localization, severity, recoverability, and a 5-class anomaly taxonomy. Using OpenClawBench, we make the Outcome-Process Gap measurable. Among 31,135 oracle-passing executions, 2,904 are still labeled process-anomalous under FullTax. These results show that success-only evaluation misses a concrete class of process-side failures in real agent executions. A LoRA-fine-tuned Gemma 3 12B detector trained on the high-confidence FullTax supervised pool reaches binary F1=0.729 on the cleaner-labels held-out test split. Together, OpenClawBench turns real agent execution logs into auditable and reusable supervision for studying, diagnosing, and operationally monitoring runtime agent reliability.
Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
Feb 03, 2026Reinforcement learning has emerged as a principled post-training paradigm for Temporal Video Grounding (TVG) due to its on-policy optimization, yet existing GRPO-based methods remain fundamentally constrained by sparse reward signals and substantial computational overhead. We propose Video-OPD, an efficient post-training framework for TVG inspired by recent advances in on-policy distillation. Video-OPD optimizes trajectories sampled directly from the current policy, thereby preserving alignment between training and inference distributions, while a frontier teacher supplies dense, token-level supervision via a reverse KL divergence objective. This formulation preserves the on-policy property critical for mitigating distributional shift, while converting sparse, episode-level feedback into fine-grained, step-wise learning signals. Building on Video-OPD, we introduce Teacher-Validated Disagreement Focusing (TVDF), a lightweight training curriculum that iteratively prioritizes trajectories that are both teacher-reliable and maximally informative for the student, thereby improving training efficiency. Empirical results demonstrate that Video-OPD consistently outperforms GRPO while achieving substantially faster convergence and lower computational cost, establishing on-policy distillation as an effective alternative to conventional reinforcement learning for TVG.
REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding
Nov 17, 2025Self-reflection mechanisms that rely on purely text-based rethinking processes perform well in most multimodal tasks. However, when directly applied to long-form video understanding scenarios, they exhibit clear limitations. The fundamental reasons for this lie in two points: (1)long-form video understanding involves richer and more dynamic visual input, meaning rethinking only the text information is insufficient and necessitates a further rethinking process specifically targeting visual information; (2) purely text-based reflection mechanisms lack cross-modal interaction capabilities, preventing them from fully integrating visual information during reflection. Motivated by these insights, we propose REVISOR (REflective VIsual Segment Oriented Reasoning), a novel framework for tool-augmented multimodal reflection. REVISOR enables MLLMs to collaboratively construct introspective reflection processes across textual and visual modalities, significantly enhancing their reasoning capability for long-form video understanding. To ensure that REVISOR can learn to accurately review video segments highly relevant to the question during reinforcement learning, we designed the Dual Attribution Decoupled Reward (DADR) mechanism. Integrated into the GRPO training strategy, this mechanism enforces causal alignment between the model's reasoning and the selected video evidence. Notably, the REVISOR framework significantly enhances long-form video understanding capability of MLLMs without requiring supplementary supervised fine-tuning or external models, achieving impressive results on four benchmarks including VideoMME, LongVideoBench, MLVU, and LVBench.
CCL-LGS: Contrastive Codebook Learning for 3D Language Gaussian Splatting
May 26, 2025



Recent advances in 3D reconstruction techniques and vision-language models have fueled significant progress in 3D semantic understanding, a capability critical to robotics, autonomous driving, and virtual/augmented reality. However, methods that rely on 2D priors are prone to a critical challenge: cross-view semantic inconsistencies induced by occlusion, image blur, and view-dependent variations. These inconsistencies, when propagated via projection supervision, deteriorate the quality of 3D Gaussian semantic fields and introduce artifacts in the rendered outputs. To mitigate this limitation, we propose CCL-LGS, a novel framework that enforces view-consistent semantic supervision by integrating multi-view semantic cues. Specifically, our approach first employs a zero-shot tracker to align a set of SAM-generated 2D masks and reliably identify their corresponding categories. Next, we utilize CLIP to extract robust semantic encodings across views. Finally, our Contrastive Codebook Learning (CCL) module distills discriminative semantic features by enforcing intra-class compactness and inter-class distinctiveness. In contrast to previous methods that directly apply CLIP to imperfect masks, our framework explicitly resolves semantic conflicts while preserving category discriminability. Extensive experiments demonstrate that CCL-LGS outperforms previous state-of-the-art methods. Our project page is available at https://epsilontl.github.io/CCL-LGS/.
Decoupled Geometric Parameterization and its Application in Deep Homography Estimation
May 22, 2025



Planar homography, with eight degrees of freedom (DOFs), is fundamental in numerous computer vision tasks. While the positional offsets of four corners are widely adopted (especially in neural network predictions), this parameterization lacks geometric interpretability and typically requires solving a linear system to compute the homography matrix. This paper presents a novel geometric parameterization of homographies, leveraging the similarity-kernel-similarity (SKS) decomposition for projective transformations. Two independent sets of four geometric parameters are decoupled: one for a similarity transformation and the other for the kernel transformation. Additionally, the geometric interpretation linearly relating the four kernel transformation parameters to angular offsets is derived. Our proposed parameterization allows for direct homography estimation through matrix multiplication, eliminating the need for solving a linear system, and achieves performance comparable to the four-corner positional offsets in deep homography estimation.
The Mirage of Performance Gains: Why Contrastive Decoding Fails to Address Multimodal Hallucination
Apr 14, 2025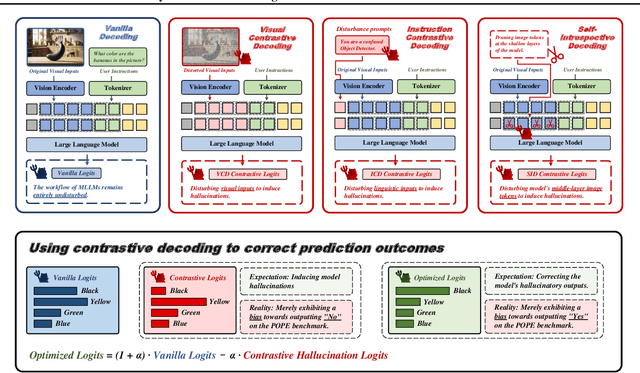
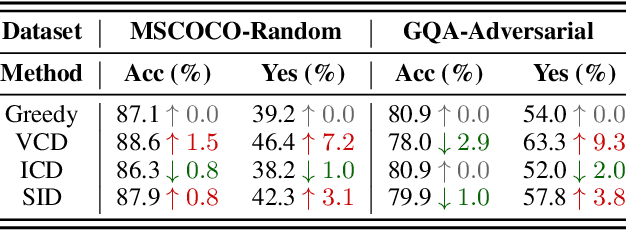
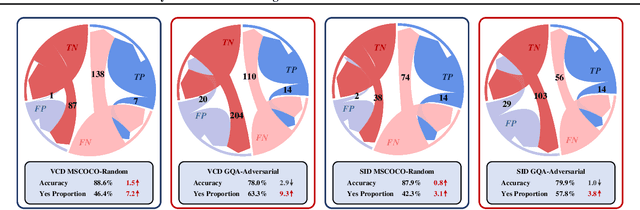
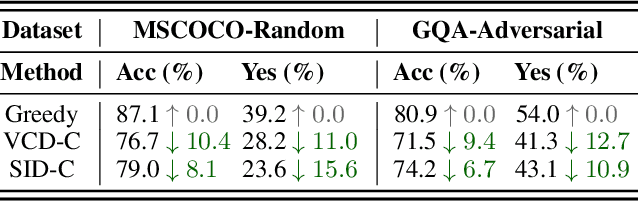
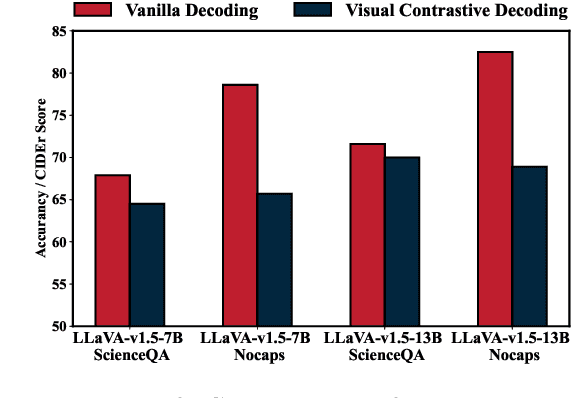
Contrastive decoding strategies are widely used to reduce hallucinations in multimodal large language models (MLLMs). These methods work by constructing contrastive samples to induce hallucinations and then suppressing them in the output distribution. However, this paper demonstrates that such approaches fail to effectively mitigate the hallucination problem. The performance improvements observed on POPE Benchmark are largely driven by two misleading factors: (1) crude, unidirectional adjustments to the model's output distribution and (2) the adaptive plausibility constraint, which reduces the sampling strategy to greedy search. To further illustrate these issues, we introduce a series of spurious improvement methods and evaluate their performance against contrastive decoding techniques. Experimental results reveal that the observed performance gains in contrastive decoding are entirely unrelated to its intended goal of mitigating hallucinations. Our findings challenge common assumptions about the effectiveness of contrastive decoding strategies and pave the way for developing genuinely effective solutions to hallucinations in MLLMs.
EvMic: Event-based Non-contact sound recovery from effective spatial-temporal modeling
Apr 03, 2025When sound waves hit an object, they induce vibrations that produce high-frequency and subtle visual changes, which can be used for recovering the sound. Early studies always encounter trade-offs related to sampling rate, bandwidth, field of view, and the simplicity of the optical path. Recent advances in event camera hardware show good potential for its application in visual sound recovery, because of its superior ability in capturing high-frequency signals. However, existing event-based vibration recovery methods are still sub-optimal for sound recovery. In this work, we propose a novel pipeline for non-contact sound recovery, fully utilizing spatial-temporal information from the event stream. We first generate a large training set using a novel simulation pipeline. Then we designed a network that leverages the sparsity of events to capture spatial information and uses Mamba to model long-term temporal information. Lastly, we train a spatial aggregation block to aggregate information from different locations to further improve signal quality. To capture event signals caused by sound waves, we also designed an imaging system using a laser matrix to enhance the gradient and collected multiple data sequences for testing. Experimental results on synthetic and real-world data demonstrate the effectiveness of our method.
Lifting the Veil on Visual Information Flow in MLLMs: Unlocking Pathways to Faster Inference
Mar 17, 2025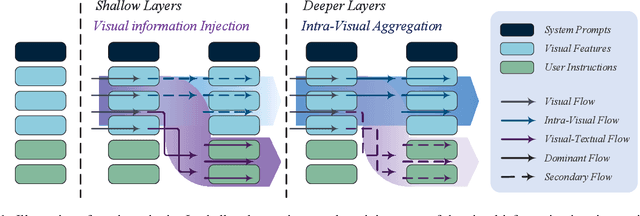
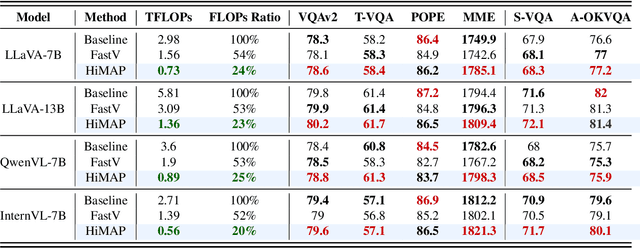
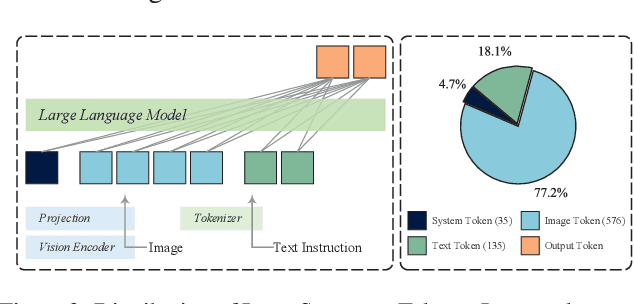
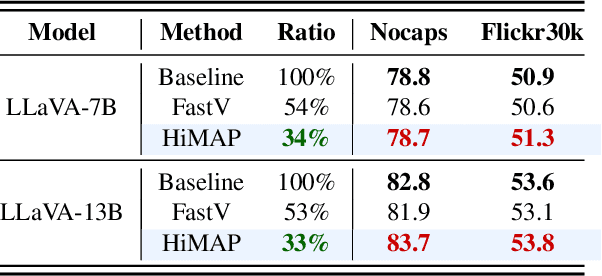
Multimodal large language models (MLLMs) improve performance on vision-language tasks by integrating visual features from pre-trained vision encoders into large language models (LLMs). However, how MLLMs process and utilize visual information remains unclear. In this paper, a shift in the dominant flow of visual information is uncovered: (1) in shallow layers, strong interactions are observed between image tokens and instruction tokens, where most visual information is injected into instruction tokens to form cross-modal semantic representations; (2) in deeper layers, image tokens primarily interact with each other, aggregating the remaining visual information to optimize semantic representations within visual modality. Based on these insights, we propose Hierarchical Modality-Aware Pruning (HiMAP), a plug-and-play inference acceleration method that dynamically prunes image tokens at specific layers, reducing computational costs by approximately 65% without sacrificing performance. Our findings offer a new understanding of visual information processing in MLLMs and provide a state-of-the-art solution for efficient inference.
ClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large language Models
Mar 17, 2025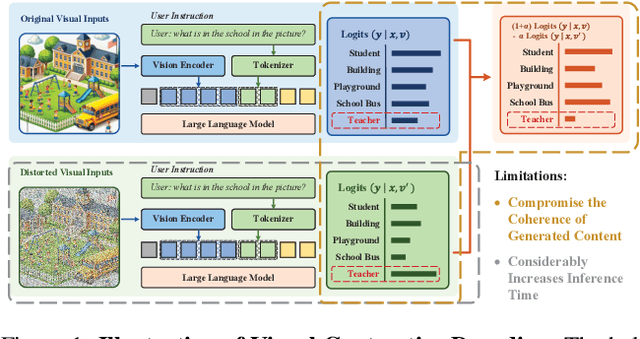


Contrastive decoding strategies are widely used to mitigate object hallucinations in multimodal large language models (MLLMs). By reducing over-reliance on language priors, these strategies ensure that generated content remains closely grounded in visual inputs, producing contextually accurate outputs. Since contrastive decoding requires no additional training or external tools, it offers both computational efficiency and versatility, making it highly attractive. However, these methods present two main limitations: (1) bluntly suppressing language priors can compromise coherence and accuracy of generated content, and (2) processing contrastive inputs adds computational load, significantly slowing inference speed. To address these challenges, we propose Visual Amplification Fusion (VAF), a plug-and-play technique that enhances attention to visual signals within the model's middle layers, where modality fusion predominantly occurs. This approach enables more effective capture of visual features, reducing the model's bias toward language modality. Experimental results demonstrate that VAF significantly reduces hallucinations across various MLLMs without affecting inference speed, while maintaining coherence and accuracy in generated outputs.
A Decade of Action Quality Assessment: Largest Systematic Survey of Trends, Challenges, and Future Directions
Feb 05, 2025



Action Quality Assessment (AQA) -- the ability to quantify the quality of human motion, actions, or skill levels and provide feedback -- has far-reaching implications in areas such as low-cost physiotherapy, sports training, and workforce development. As such, it has become a critical field in computer vision & video understanding over the past decade. Significant progress has been made in AQA methodologies, datasets, & applications, yet a pressing need remains for a comprehensive synthesis of this rapidly evolving field. In this paper, we present a thorough survey of the AQA landscape, systematically reviewing over 200 research papers using the preferred reporting items for systematic reviews & meta-analyses (PRISMA) framework. We begin by covering foundational concepts & definitions, then move to general frameworks & performance metrics, & finally discuss the latest advances in methodologies & datasets. This survey provides a detailed analysis of research trends, performance comparisons, challenges, & future directions. Through this work, we aim to offer a valuable resource for both newcomers & experienced researchers, promoting further exploration & progress in AQA. Data are available at https://haoyin116.github.io/Survey_of_AQA/