 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mirage of Performance Gains: Why Contrastive Decoding Fails to Address Multimodal Hallucination
Apr 14, 2025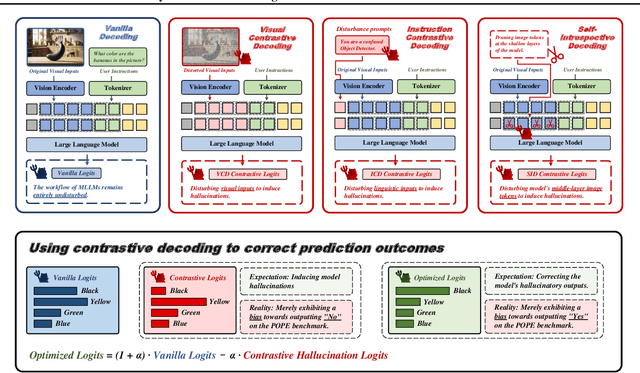
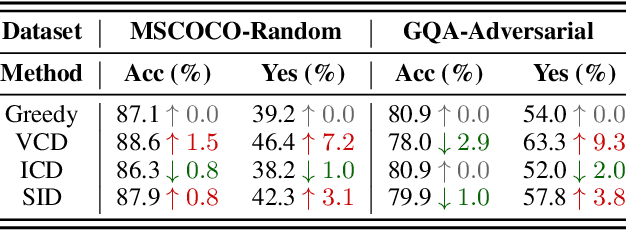
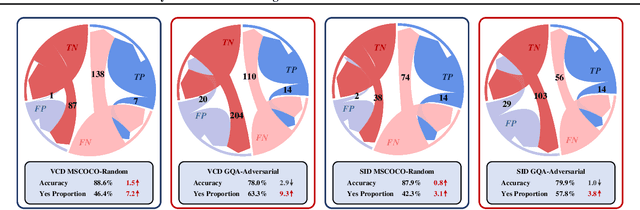
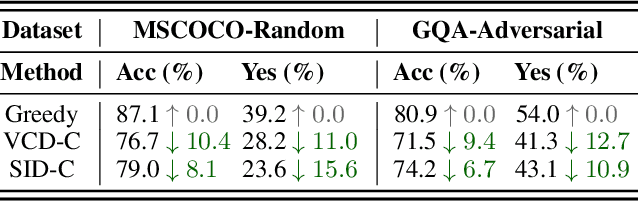
Contrastive decoding strategies are widely used to reduce hallucinations in multimodal large language models (MLLMs). These methods work by constructing contrastive samples to induce hallucinations and then suppressing them in the output distribution. However, this paper demonstrates that such approaches fail to effectively mitigate the hallucination problem. The performance improvements observed on POPE Benchmark are largely driven by two misleading factors: (1) crude, unidirectional adjustments to the model's output distribution and (2) the adaptive plausibility constraint, which reduces the sampling strategy to greedy search. To further illustrate these issues, we introduce a series of spurious improvement methods and evaluate their performance against contrastive decoding techniques. Experimental results reveal that the observed performance gains in contrastive decoding are entirely unrelated to its intended goal of mitigating hallucinations. Our findings challenge common assumptions about the effectiveness of contrastive decoding strategies and pave the way for developing genuinely effective solutions to hallucinations in MLLMs.