 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Achieving Controllable Code Completion in Code LLM
Jan 22, 2026Code completion has become a central task, gaining significant attention with the rise of large language model (LLM)-based tools in software engineering. Although recent advances have greatly improved LLMs' code completion abilities, evaluation methods have not advanced equally. Most current benchmarks focus solely on functional correctness of code completions based on given context, overlooking models' ability to follow user instructions during completion-a common scenario in LLM-assisted programming. To address this limitation, we present the first instruction-guided code completion benchmark, Controllable Code Completion Benchmark (C3-Bench), comprising 2,195 carefully designed completion tasks. Through comprehensive evaluation of over 40 mainstream LLMs across C3-Bench and conventional benchmarks, we reveal substantial gaps in instruction-following capabilities between open-source and advanced proprietary models during code completion tasks. Moreover, we develop a straightforward data synthesis pipeline that leverages Qwen2.5-Coder to generate high-quality instruction-completion pairs for supervised fine-tuning (SFT). The resulting model, Qwen2.5-Coder-C3, achieves state-of-the-art performance on C3-Bench. Our findings provide valuable insights for enhancing LLMs' code completion and instruction-following capabilities, establishing new directions for future research in code LLMs. To facilitate reproducibility and foster further research in code LLMs, we open-source all code, datasets, and models.
From Completion to Editing: Unlocking Context-Aware Code Infilling via Search-and-Replace Instruction Tuning
Jan 19, 2026The dominant Fill-in-the-Middle (FIM) paradigm for code completion is constrained by its rigid inability to correct contextual errors and reliance on unaligned, insecure Base models. While Chat LLMs offer safety and Agentic workflows provide flexibility, they suffer from performance degradation and prohibitive latency, respectively. To resolve this dilemma, we propose Search-and-Replace Infilling (SRI), a framework that internalizes the agentic verification-and-editing mechanism into a unified, single-pass inference process. By structurally grounding edits via an explicit search phase, SRI harmonizes completion tasks with the instruction-following priors of Chat LLMs, extending the paradigm from static infilling to dynamic context-aware editing. We synthesize a high-quality dataset, SRI-200K, and fine-tune the SRI-Coder series. Extensive evaluations demonstrate that with minimal data (20k samples), SRI-Coder enables Chat models to surpass the completion performance of their Base counterparts. Crucially, unlike FIM-style tuning, SRI preserves general coding competencies and maintains inference latency comparable to standard FIM. We empower the entire Qwen3-Coder series with SRI, encouraging the developer community to leverage this framework for advanced auto-completion and assisted development.
Predict the Retrieval! Test time adaptation for Retrieval Augmented Generation
Jan 16, 2026Retrieval-Augmented Generation (RAG) has emerged as a powerful approach for enhancing large language models' question-answering capabilities through the integration of external knowledge. However, when adapting RAG systems to specialized domains, challenges arise from distribution shifts, resulting in suboptimal generalization performance. In this work, we propose TTARAG, a test-time adaptation method that dynamically updates the language model's parameters during inference to improve RAG system performance in specialized domains. Our method introduces a simple yet effective approach where the model learns to predict retrieved content, enabling automatic parameter adjustment to the target domain. Through extensive experiments across six specialized domains, we demonstrate that TTARAG achieves substantial performance improvements over baseline RAG systems. Code available at https://github.com/sunxin000/TTARAG.
KBQA-R1: Reinforcing Large Language Models for Knowledge Base Question Answering
Dec 10, 2025Knowledge Base Question Answering (KBQA) challenges models to bridge the gap between natural language and strict knowledge graph schemas by generating executable logical forms. While Large Language Models (LLMs) have advanced this field, current approaches often struggle with a dichotomy of failure: they either generate hallucinated queries without verifying schema existence or exhibit rigid, template-based reasoning that mimics synthesized traces without true comprehension of the environment. To address these limitations, we present \textbf{KBQA-R1}, a framework that shifts the paradigm from text imitation to interaction optimization via Reinforcement Learning. Treating KBQA as a multi-turn decision process, our model learns to navigate the knowledge base using a list of actions, leveraging Group Relative Policy Optimization (GRPO) to refine its strategies based on concrete execution feedback rather than static supervision. Furthermore, we introduce \textbf{Referenced Rejection Sampling (RRS)}, a data synthesis method that resolves cold-start challenges by strictly aligning reasoning traces with ground-truth action sequences. Extensive experiments on WebQSP, GrailQA, and GraphQuestions demonstrate that KBQA-R1 achieves state-of-the-art performance, effectively grounding LLM reasoning in verifiable execution.
Divide-Then-Align: Honest Alignment based on the Knowledge Boundary of RAG
May 27, 2025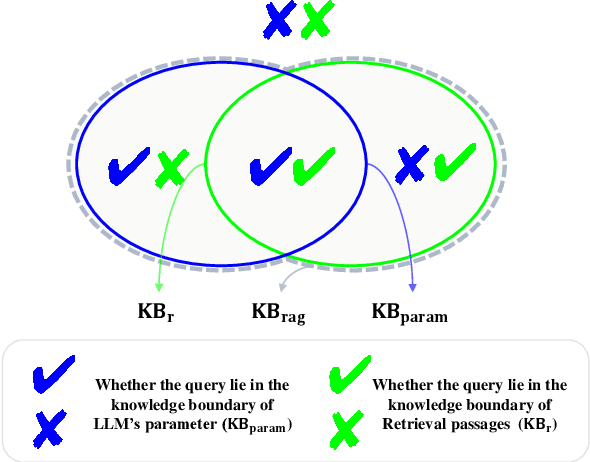
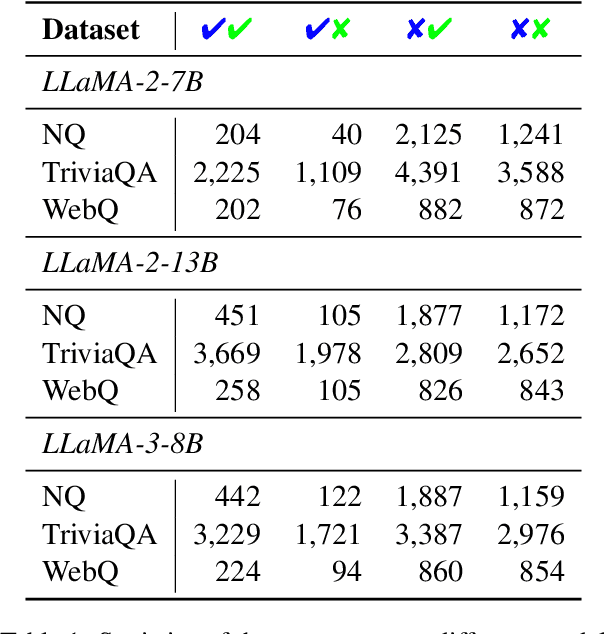
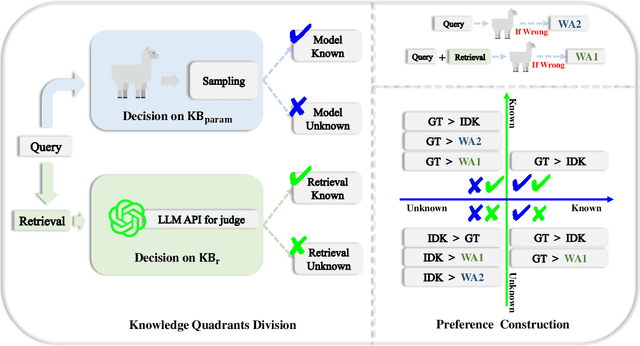

Large language models (LLMs) augmented with retrieval systems have significantly advanced natural language processing tasks by integrating external knowledge sources, enabling more accurate and contextually rich responses. To improve the robustness of such systems against noisy retrievals, Retrieval-Augmented Fine-Tuning (RAFT) has emerged as a widely adopted method. However, RAFT conditions models to generate answers even in the absence of reliable knowledge. This behavior undermines their reliability in high-stakes domains, where acknowledging uncertainty is critical. To address this issue, we propose Divide-Then-Align (DTA), a post-training approach designed to endow RAG systems with the ability to respond with "I don't know" when the query is out of the knowledge boundary of both the retrieved passages and the model's internal knowledge. DTA divides data samples into four knowledge quadrants and constructs tailored preference data for each quadrant, resulting in a curated dataset for Direct Preference Optimization (DPO). Experimental results on three benchmark datasets demonstrate that DTA effectively balances accuracy with appropriate abstention, enhancing the reliability and trustworthiness of retrieval-augmented systems.
R-TPT: Improving Adversarial Robustness of Vision-Language Models through Test-Time Prompt Tuning
Apr 15, 2025Vision-language models (VLMs), such as CLIP, have gained significant popularity as foundation models, with numerous fine-tuning methods developed to enhance performance on downstream tasks. However, due to their inherent vulnerability and the common practice of selecting from a limited set of open-source models, VLMs suffer from a higher risk of adversarial attacks than traditional vision models. Existing defense techniques typically rely on adversarial fine-tuning during training, which requires labeled data and lacks of flexibility for downstream tasks. To address these limitations, we propose robust test-time prompt tuning (R-TPT), which mitigates the impact of adversarial attacks during the inference stage. We first reformulate the classic marginal entropy objective by eliminating the term that introduces conflicts under adversarial conditions, retaining only the pointwise entropy minimization. Furthermore, we introduce a plug-and-play reliability-based weighted ensembling strategy, which aggregates useful information from reliable augmented views to strengthen the defense. R-TPT enhances defense against adversarial attacks without requiring labeled training data while offering high flexibility for inference tasks. Extensive experiments on widely used benchmarks with various attacks demonstrate the effectiveness of R-TPT. The code is available in https://github.com/TomSheng21/R-TPT.
The Mirage of Performance Gains: Why Contrastive Decoding Fails to Address Multimodal Hallucination
Apr 14, 2025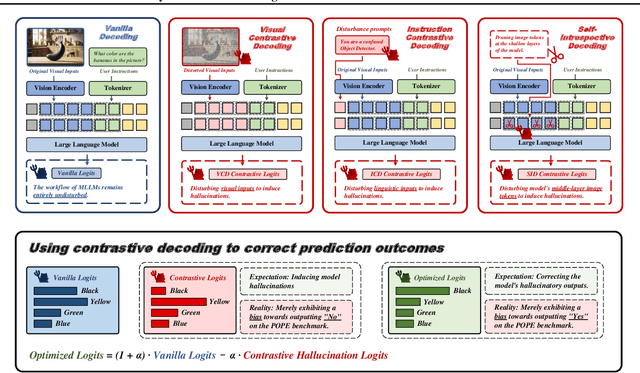
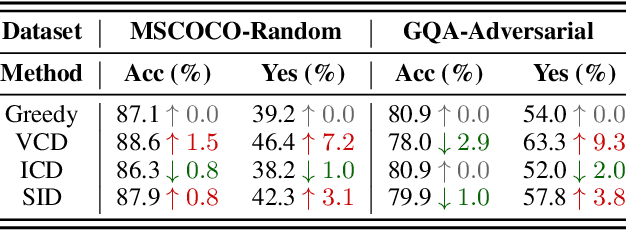
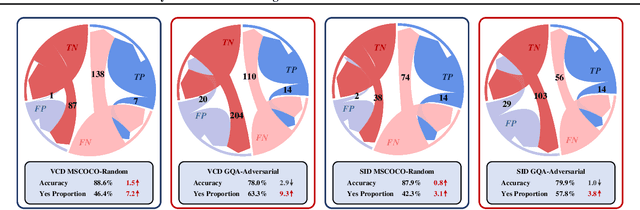
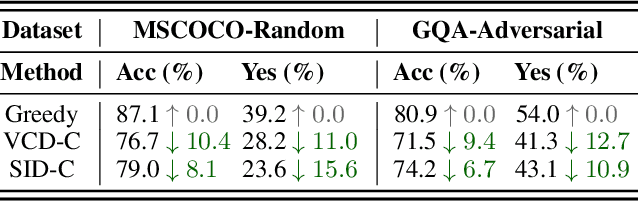
Contrastive decoding strategies are widely used to reduce hallucinations in multimodal large language models (MLLMs). These methods work by constructing contrastive samples to induce hallucinations and then suppressing them in the output distribution. However, this paper demonstrates that such approaches fail to effectively mitigate the hallucination problem. The performance improvements observed on POPE Benchmark are largely driven by two misleading factors: (1) crude, unidirectional adjustments to the model's output distribution and (2) the adaptive plausibility constraint, which reduces the sampling strategy to greedy search. To further illustrate these issues, we introduce a series of spurious improvement methods and evaluate their performance against contrastive decoding techniques. Experimental results reveal that the observed performance gains in contrastive decoding are entirely unrelated to its intended goal of mitigating hallucinations. Our findings challenge common assumptions about the effectiveness of contrastive decoding strategies and pave the way for developing genuinely effective solutions to hallucinations in MLLMs.
Lifting the Veil on Visual Information Flow in MLLMs: Unlocking Pathways to Faster Inference
Mar 17, 2025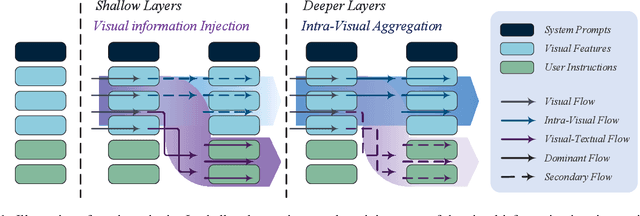
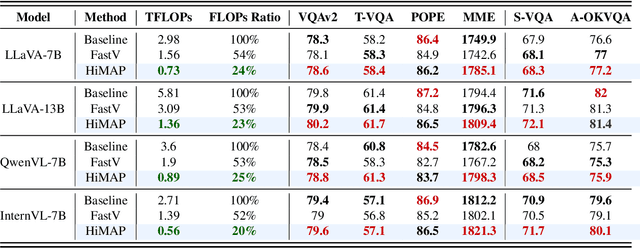
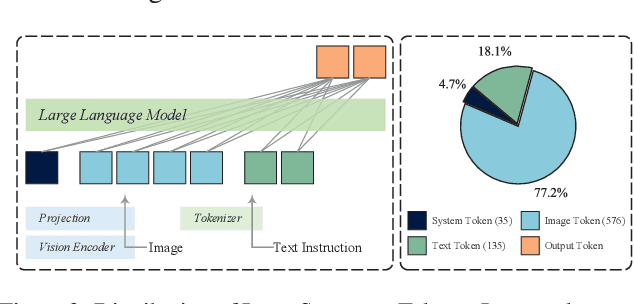
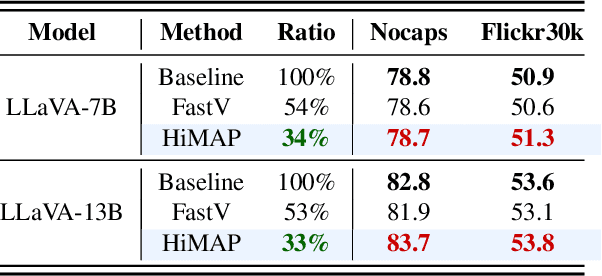
Multimodal large language models (MLLMs) improve performance on vision-language tasks by integrating visual features from pre-trained vision encoders into large language models (LLMs). However, how MLLMs process and utilize visual information remains unclear. In this paper, a shift in the dominant flow of visual information is uncovered: (1) in shallow layers, strong interactions are observed between image tokens and instruction tokens, where most visual information is injected into instruction tokens to form cross-modal semantic representations; (2) in deeper layers, image tokens primarily interact with each other, aggregating the remaining visual information to optimize semantic representations within visual modality. Based on these insights, we propose Hierarchical Modality-Aware Pruning (HiMAP), a plug-and-play inference acceleration method that dynamically prunes image tokens at specific layers, reducing computational costs by approximately 65% without sacrificing performance. Our findings offer a new understanding of visual information processing in MLLMs and provide a state-of-the-art solution for efficient inference.
ClearSight: Visual Signal Enhancement for Object Hallucination Mitigation in Multimodal Large language Models
Mar 17, 2025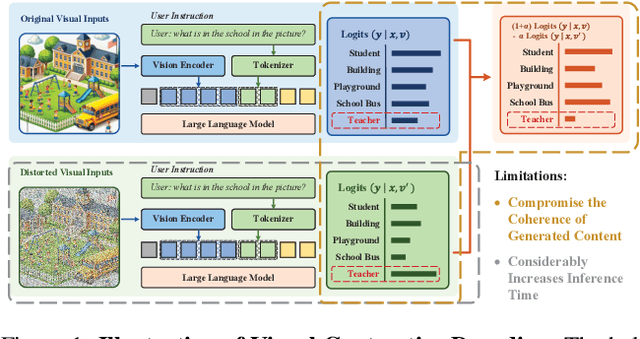

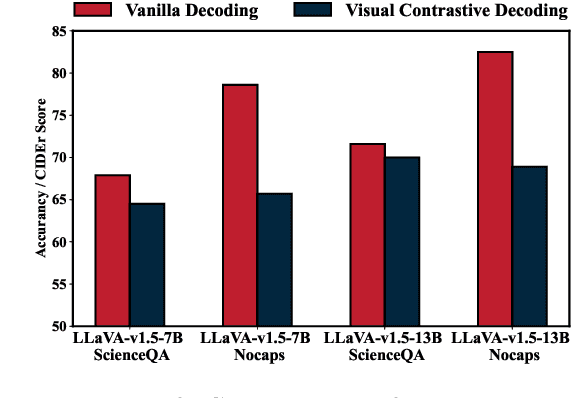

Contrastive decoding strategies are widely used to mitigate object hallucinations in multimodal large language models (MLLMs). By reducing over-reliance on language priors, these strategies ensure that generated content remains closely grounded in visual inputs, producing contextually accurate outputs. Since contrastive decoding requires no additional training or external tools, it offers both computational efficiency and versatility, making it highly attractive. However, these methods present two main limitations: (1) bluntly suppressing language priors can compromise coherence and accuracy of generated content, and (2) processing contrastive inputs adds computational load, significantly slowing inference speed. To address these challenges, we propose Visual Amplification Fusion (VAF), a plug-and-play technique that enhances attention to visual signals within the model's middle layers, where modality fusion predominantly occurs. This approach enables more effective capture of visual features, reducing the model's bias toward language modality. Experimental results demonstrate that VAF significantly reduces hallucinations across various MLLMs without affecting inference speed, while maintaining coherence and accuracy in generated outputs.
Towards Compatible Fine-tuning for Vision-Language Model Updates
Dec 30, 2024



So far, efficient fine-tuning has become a popular strategy for enhancing the capabilities of foundation models on downstream tasks by learning plug-and-play modules. However, existing methods overlook a crucial issue: if the underlying foundation model is updated, are these plug-and-play modules still effective? In this paper, we first conduct a detailed analysis of various fine-tuning methods on the CLIP in terms of their compatibility with model updates. The study reveals that many high-performing fine-tuning methods fail to be compatible with the upgraded models. To address this, we propose a novel approach, Class-conditioned Context Optimization (ContCoOp), which integrates learnable prompts with class embeddings using an attention layer before inputting them into the text encoder. Consequently, the prompts can dynamically adapt to the changes in embedding space (due to model updates), ensuring continued effectiveness. Extensive experiments over 15 datasets show that our ContCoOp achieves the highest compatibility over the baseline methods, and exhibits robust out-of-distribution generalization.