 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Your Training Flexible: Towards Deployment-Efficient Video Models
Mar 18, 2025Popular video training methods mainly operate on a fixed number of tokens sampled from a predetermined spatiotemporal grid, resulting in sub-optimal accuracy-computation trade-offs due to inherent video redundancy. They also lack adaptability to varying computational budgets for downstream tasks, hindering applications of the most competitive model in real-world scenes. We thus propose a new test setting, Token Optimization, for maximized input information across budgets, which optimizes the size-limited set of input tokens through token selection from more suitably sampled videos. To this end, we propose a novel augmentation tool termed Flux. By making the sampling grid flexible and leveraging token selection, it is easily adopted in most popular video training frameworks, boosting model robustness with nearly no additional cost. We integrate Flux in large-scale video pre-training, and the resulting FluxViT establishes new state-of-the-art results across extensive tasks at standard costs. Notably, with 1/4 tokens only, it can still match the performance of previous state-of-the-art models with Token Optimization, yielding nearly 90\% savings. All models and data are available at https://github.com/OpenGVLab/FluxViT.
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025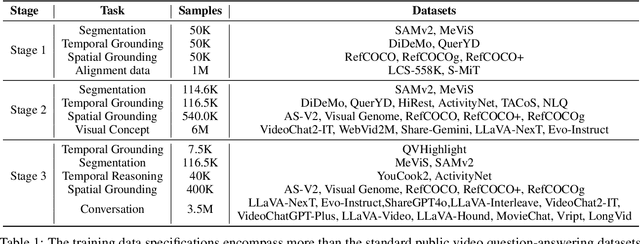
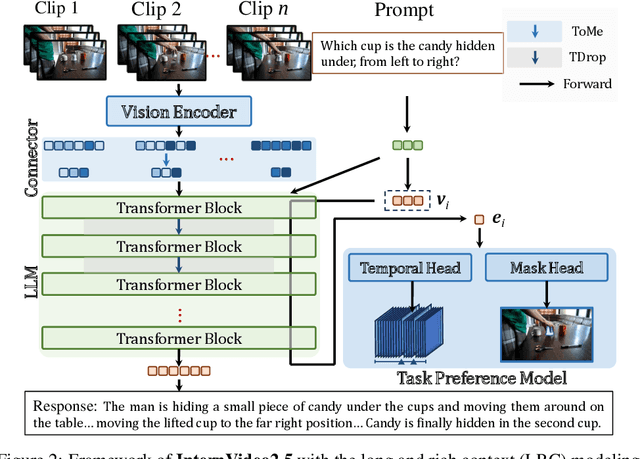
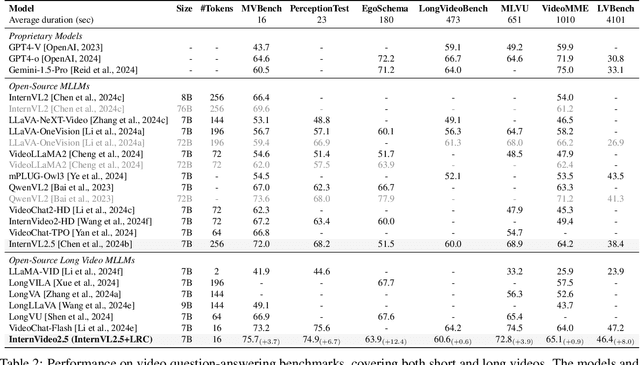
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Dec 31, 2024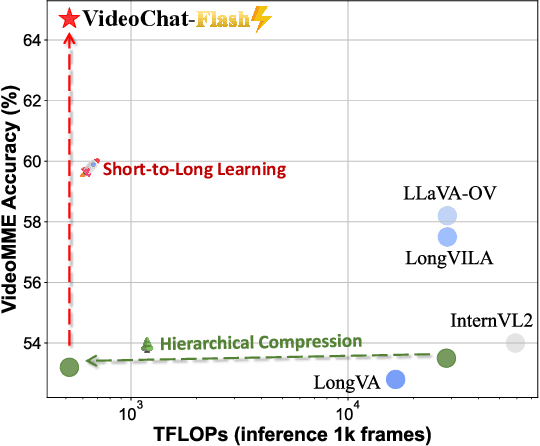
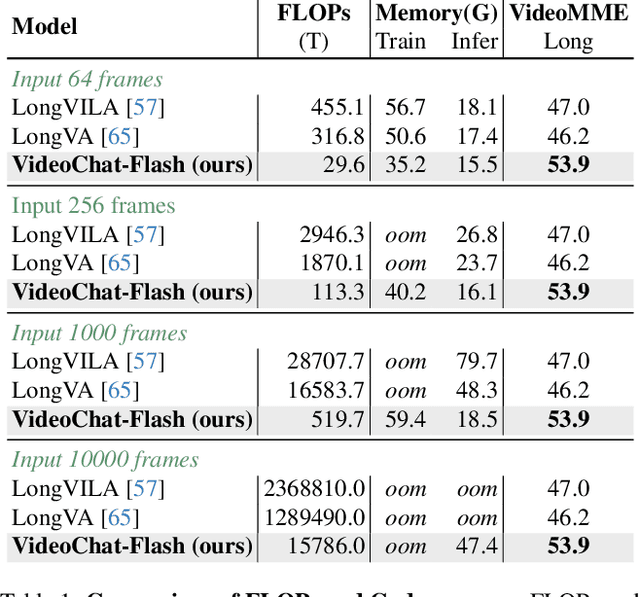

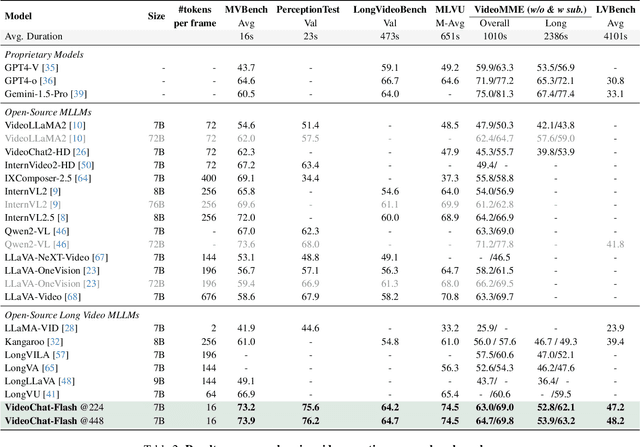
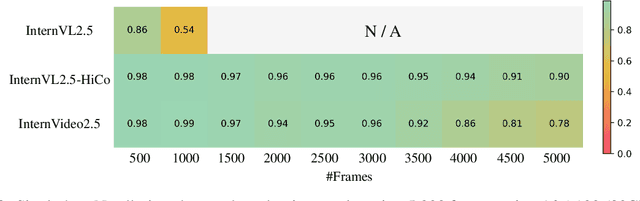
Long-context modeling is a critical capability for multimodal large language models (MLLMs), enabling them to process long-form contents with implicit memorization. Despite its advances, handling extremely long videos remains challenging due to the difficulty in maintaining crucial features over extended sequences. This paper introduces a Hierarchical visual token Compression (HiCo) method designed for high-fidelity representation and a practical context modeling system VideoChat-Flash tailored for multimodal long-sequence processing. HiCo capitalizes on the redundancy of visual information in long videos to compress long video context from the clip-level to the video-level, reducing the compute significantly while preserving essential details. VideoChat-Flash features a multi-stage short-to-long learning scheme, a rich dataset of real-world long videos named LongVid, and an upgraded "Needle-In-A-video-Haystack" (NIAH) for evaluating context capacities. In extensive experiments, VideoChat-Flash shows the leading performance on both mainstream long and short video benchmarks at the 7B model scale. It firstly gets 99.1% accuracy over 10,000 frames in NIAH among open-source models.
Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
Dec 26, 2024Current multimodal large language models (MLLMs) struggle with fine-grained or precise understanding of visuals though they give comprehensive perception and reasoning in a spectrum of vision applications. Recent studies either develop tool-using or unify specific visual tasks into the autoregressive framework, often at the expense of overall multimodal performance. To address this issue and enhance MLLMs with visual tasks in a scalable fashion, we propose Task Preference Optimization (TPO), a novel method that utilizes differentiable task preferences derived from typical fine-grained visual tasks. TPO introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM. By leveraging rich visual labels during training, TPO significantly enhances the MLLM's multimodal capabilities and task-specific performance. Through multi-task co-training within TPO, we observe synergistic benefits that elevate individual task performance beyond what is achievable through single-task training methodologies. Our instantiation of this approach with VideoChat and LLaVA demonstrates an overall 14.6% improvement in multimodal performance compared to baseline models. Additionally, MLLM-TPO demonstrates robust zero-shot capabilities across various tasks, performing comparably to state-of-the-art supervised models. The code will be released at https://github.com/OpenGVLab/TPO
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Oct 25, 2024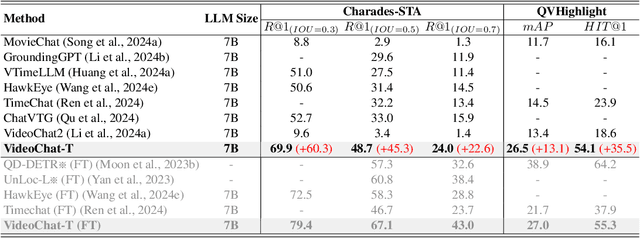
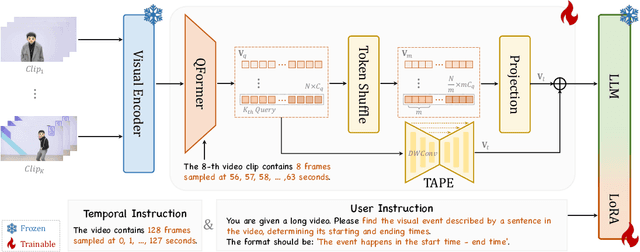
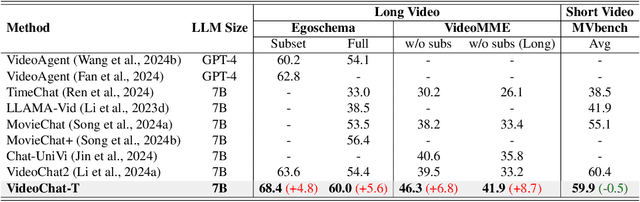
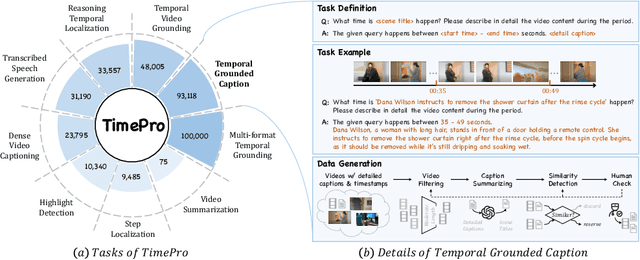
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.