 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025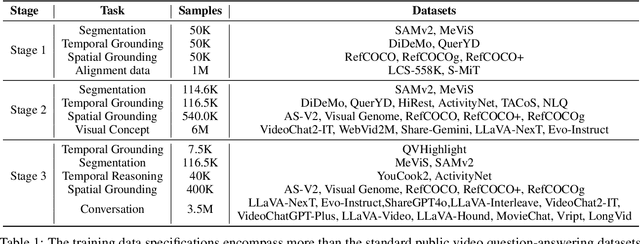
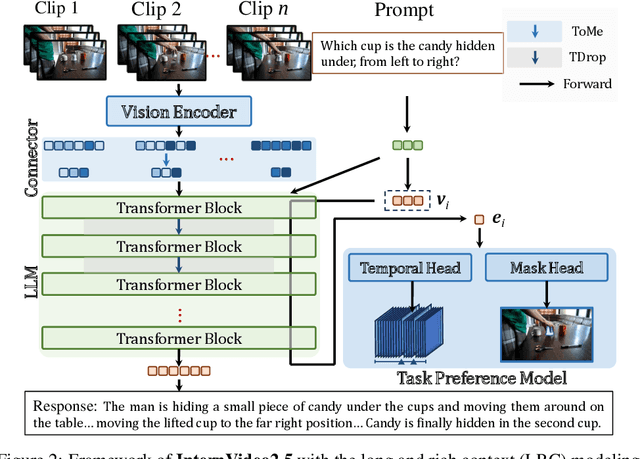
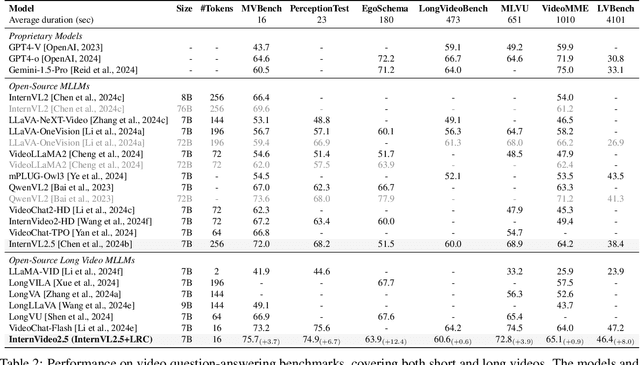
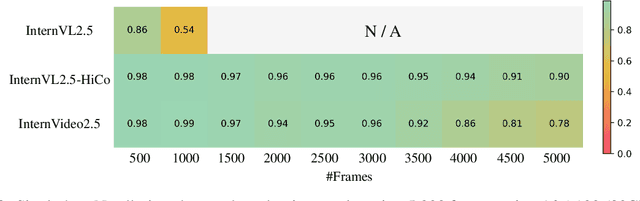
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5