 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVideo3: Agentify Foundation Models with Multimodal Contextual Reasoning
Jun 10, 2026Recent progress in foundation models has shifted toward agentic behavior involving multi-step reasoning and tool use. However, open-source efforts largely focus on text-dominant settings, leaving long-horizon multimodal tasks underexplored. This gap is evident in video tasks requiring sustained temporal understanding and iterative interaction. We present InternVideo3, a framework enhancing these capabilities via Multimodal Contextual Reasoning (MCR). MCR treats understanding as a closed-loop process over a shared, evolving context containing observations, instructions, reasoning, tool actions, and memory. This frames long-video understanding as evidence accumulation and verification. To ensure efficiency, we introduce Multimodal Multi-head Latent Attention (M^2LA), a token-preserving reparameterization compressing KV-cache states while retaining the full token stream. Our staged training includes continued pretraining, short-to-long supervised fine-tuning, rule-based reinforcement learning, and on-policy distillation. Experiments show InternVideo3 achieves strong performance on benchmarks like Video-MME, MLVU, and EgoSchema. We further instantiate the model as a video agent with retrieval tools, demonstrating robust evidence-grounded behavior. Our results suggest that efficient context handling and closed-loop reasoning are vital for adapting open multimodal models toward long-horizon visually grounded agency.
Imagine Before You Predict: Interleaved Latent Visual Reasoning for Video Event Prediction
Jun 04, 2026Video event prediction (VEP) requires models to infer unobserved future states from partial video evidence. Existing video MLLMs usually verbalize intermediate future reasoning in text space: once visual evidence is verbalized, fine-grained motion, geometry, and interaction cues can be lost, leading to plausible but visually ungrounded hallucinations. We introduce Future-L1, an interleaved latent visual reasoning framework that lets an MLLM alternate between language tokens and continuous latent visual spans during autoregressive decoding. To train this capability, we construct Future-L1-50K by selecting examples where future visual hints help prediction and align latent states to future-frame embeddings, then further optimize sampled latent trajectories with LA-DAPO, a latent-aware RL objective with outcome-contrastive and temporal-diversity rewards. Future-L1 achieves new state-of-the-art results on both benchmarks: on FutureBench, it improves Qwen3-VL-8B from 61.0 to 85.4 and exceeds the previous best Video-CoE by 10.4 points; on TwiFF-Bench, it improves the average score from 2.44 to 3.04. These results suggest that future-oriented video reasoning benefits from preserving intermediate visual semantics in latent space rather than translating every reasoning step into text.
ViCuR: Visual Cues as Recoverable Privilege for Multimodal On-Policy Distillation
Jun 04, 2026On-policy distillation (OPD) improves reasoning by training a student on trajectories sampled from its own policy under supervision from a teacher. In multimodal reasoning, a common extension is to use a privileged teacher that observes training-time-only signals such as reference answers or rationales. However, such answer-side privilege creates a train-test mismatch: the teacher's supervision may depend on signals unavailable to the student, encouraging shortcut imitation rather than visually grounded reasoning. We propose ViCuR, a visually grounded privileged-teacher distillation framework that replaces answer-side privilege with visual cues (query-related evidence in the input). Because these cues are derived from the same visual input available at inference, their evidence is recoverable by the student. To support this, ViCuR introduces a lightweight cue recovery module that uses dedicated sink-token cross-attention during prefill to aggregate task-relevant visual evidence into an internal representation, without changing the inference interface or requiring auxiliary cue-generation losses. Across seven benchmarks with Qwen3-VL-2B and 8B students, ViCuR consistently improves over answer-based on-policy self-distillation by +1.19 and +1.24 on overall average performance. It also extends naturally to stronger-teacher OPD, surpassing OPD baselines by +0.64 and +1.08, with consistent out-of-domain gains at the 8B scale. These results show that, in multimodal on-policy distillation, the design of teacher privilege is as important as teacher strength.
Intern-S1-Pro: Scientific Multimodal Foundation Model at Trillion Scale
Mar 26, 2026We introduce Intern-S1-Pro, the first one-trillion-parameter scientific multimodal foundation model. Scaling to this unprecedented size, the model delivers a comprehensive enhancement across both general and scientific domains. Beyond stronger reasoning and image-text understanding capabilities, its intelligence is augmented with advanced agent capabilities. Simultaneously, its scientific expertise has been vastly expanded to master over 100 specialized tasks across critical science fields, including chemistry, materials, life sciences, and earth sciences. Achieving this massive scale is made possible by the robust infrastructure support of XTuner and LMDeploy, which facilitates highly efficient Reinforcement Learning (RL) training at the 1-trillion parameter level while ensuring strict precision consistency between training and inference. By seamlessly integrating these advancements, Intern-S1-Pro further fortifies the fusion of general and specialized intelligence, working as a Specializable Generalist, demonstrating its position in the top tier of open-source models for general capabilities, while outperforming proprietary models in the depth of specialized scientific tasks.
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
DSI-Bench: A Benchmark for Dynamic Spatial Intelligence
Oct 21, 2025Reasoning about dynamic spatial relationships is essential, as both observers and objects often move simultaneously. Although vision-language models (VLMs) and visual expertise models excel in 2D tasks and static scenarios, their ability to fully understand dynamic 3D scenarios remains limited. We introduce Dynamic Spatial Intelligence and propose DSI-Bench, a benchmark with nearly 1,000 dynamic videos and over 1,700 manually annotated questions covering nine decoupled motion patterns of observers and objects. Spatially and temporally symmetric designs reduce biases and enable systematic evaluation of models' reasoning about self-motion and object motion. Our evaluation of 14 VLMs and expert models reveals key limitations: models often conflate observer and object motion, exhibit semantic biases, and fail to accurately infer relative relationships in dynamic scenarios. Our DSI-Bench provides valuable findings and insights about the future development of general and expertise models with dynamic spatial intelligence.
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Apr 10, 2025Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Jan 21, 2025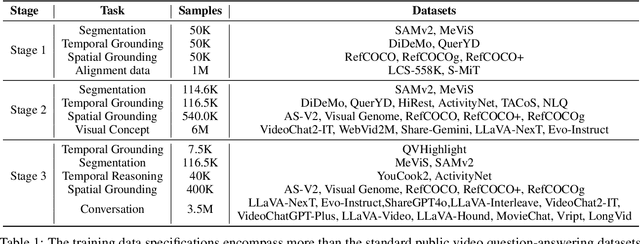
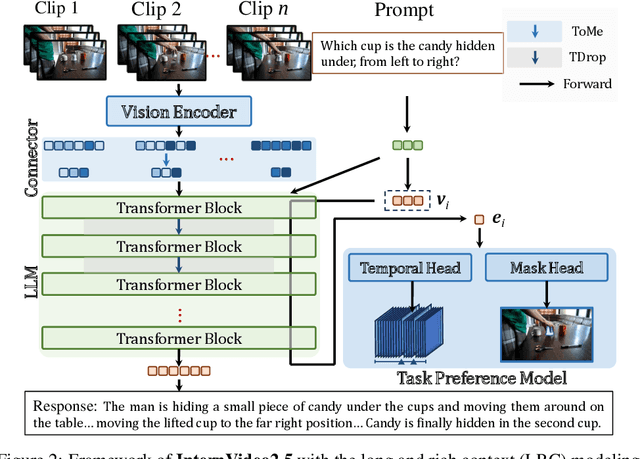
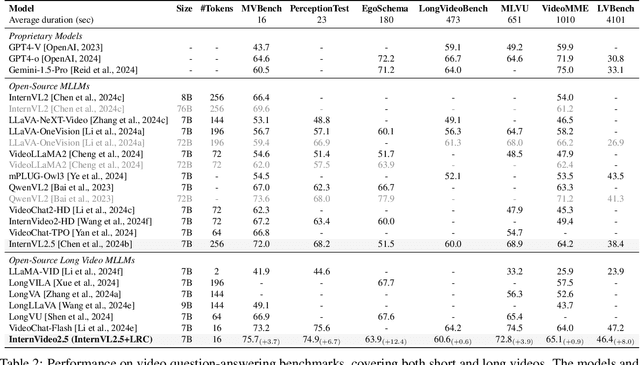
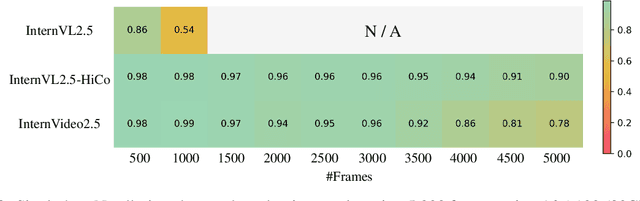
This paper aims to improve the performance of video multimodal large language models (MLLM) via long and rich context (LRC) modeling. As a result, we develop a new version of InternVideo2.5 with a focus on enhancing the original MLLMs' ability to perceive fine-grained details and capture long-form temporal structure in videos. Specifically, our approach incorporates dense vision task annotations into MLLMs using direct preference optimization and develops compact spatiotemporal representations through adaptive hierarchical token compression. Experimental results demonstrate this unique design of LRC greatly improves the results of video MLLM in mainstream video understanding benchmarks (short & long), enabling the MLLM to memorize significantly longer video inputs (at least 6x longer than the original), and master specialized vision capabilities like object tracking and segmentation. Our work highlights the importance of multimodal context richness (length and fineness) in empowering MLLM's innate abilites (focus and memory), providing new insights for future research on video MLLM. Code and models are available at https://github.com/OpenGVLab/InternVideo/tree/main/InternVideo2.5
Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
Dec 26, 2024Current multimodal large language models (MLLMs) struggle with fine-grained or precise understanding of visuals though they give comprehensive perception and reasoning in a spectrum of vision applications. Recent studies either develop tool-using or unify specific visual tasks into the autoregressive framework, often at the expense of overall multimodal performance. To address this issue and enhance MLLMs with visual tasks in a scalable fashion, we propose Task Preference Optimization (TPO), a novel method that utilizes differentiable task preferences derived from typical fine-grained visual tasks. TPO introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM. By leveraging rich visual labels during training, TPO significantly enhances the MLLM's multimodal capabilities and task-specific performance. Through multi-task co-training within TPO, we observe synergistic benefits that elevate individual task performance beyond what is achievable through single-task training methodologies. Our instantiation of this approach with VideoChat and LLaVA demonstrates an overall 14.6% improvement in multimodal performance compared to baseline models. Additionally, MLLM-TPO demonstrates robust zero-shot capabilities across various tasks, performing comparably to state-of-the-art supervised models. The code will be released at https://github.com/OpenGVLab/TPO
TimeSuite: Improving MLLMs for Long Video Understanding via Grounded Tuning
Oct 25, 2024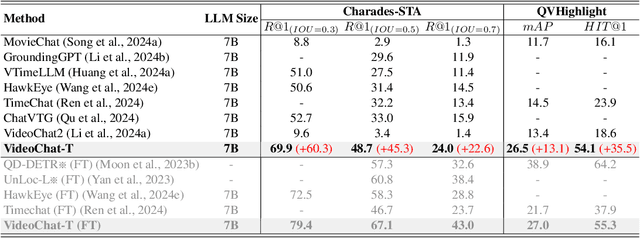
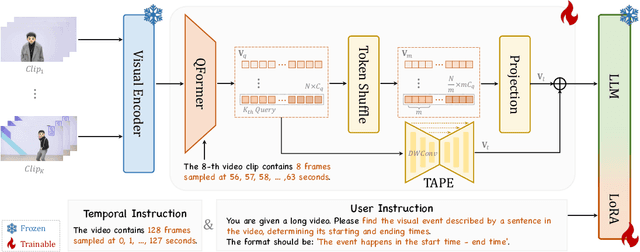
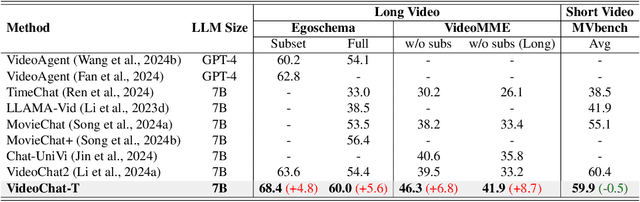
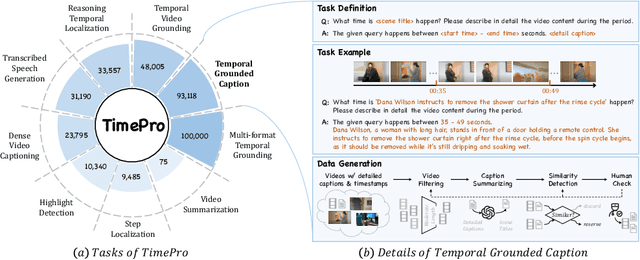
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in short video understanding. However, understanding long-form videos still remains challenging for MLLMs. This paper proposes TimeSuite, a collection of new designs to adapt the existing short-form video MLLMs for long video understanding, including a simple yet efficient framework to process long video sequence, a high-quality video dataset for grounded tuning of MLLMs, and a carefully-designed instruction tuning task to explicitly incorporate the grounding supervision in the traditional QA format. Specifically, based on VideoChat, we propose our long-video MLLM, coined as VideoChat-T, by implementing a token shuffling to compress long video tokens and introducing Temporal Adaptive Position Encoding (TAPE) to enhance the temporal awareness of visual representation. Meanwhile, we introduce the TimePro, a comprehensive grounding-centric instruction tuning dataset composed of 9 tasks and 349k high-quality grounded annotations. Notably, we design a new instruction tuning task type, called Temporal Grounded Caption, to peform detailed video descriptions with the corresponding time stamps prediction. This explicit temporal location prediction will guide MLLM to correctly attend on the visual content when generating description, and thus reduce the hallucination risk caused by the LLMs. Experimental results demonstrate that our TimeSuite provides a successful solution to enhance the long video understanding capability of short-form MLLM, achieving improvement of 5.6% and 6.8% on the benchmarks of Egoschema and VideoMME, respectively. In addition, VideoChat-T exhibits robust zero-shot temporal grounding capabilities, significantly outperforming the existing state-of-the-art MLLMs. After fine-tuning, it performs on par with the traditional supervised expert models.