 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Disruption in Reinforcement Learning:Adversarial Attack with Large Language Models and Critical State Identification
Jul 24, 2025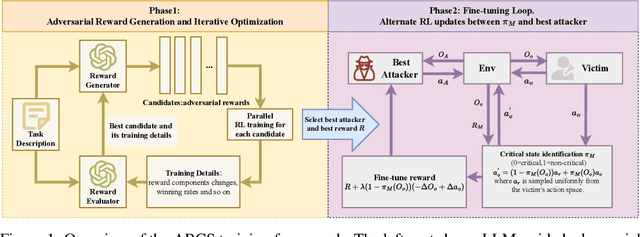
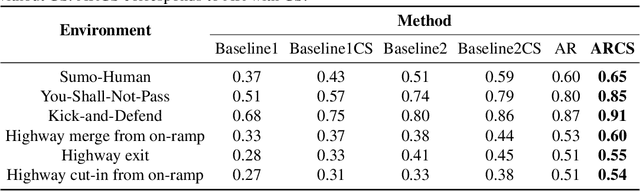
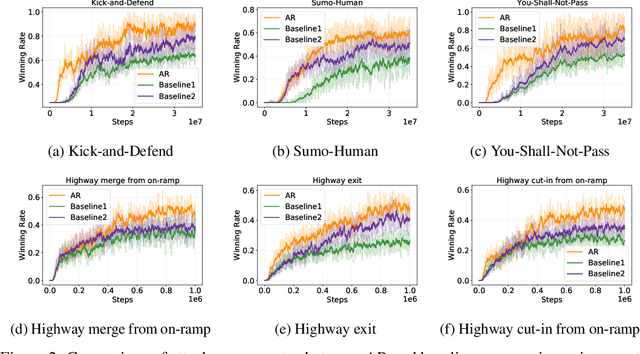
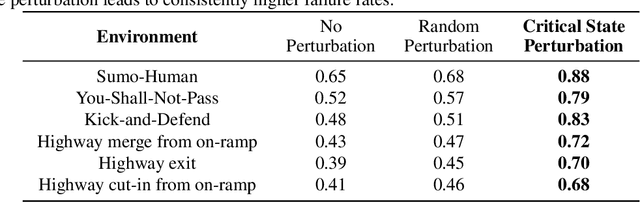
Reinforcement learning (RL) has achieved remarkable success in fields like robotics and autonomous driving, but adversarial attacks designed to mislead RL systems remain challenging. Existing approaches often rely on modifying the environment or policy, limiting their practicality. This paper proposes an adversarial attack method in which existing agents in the environment guide the target policy to output suboptimal actions without altering the environment. We propose a reward iteration optimization framework that leverages large language models (LLMs) to generate adversarial rewards explicitly tailored to the vulnerabilities of the target agent, thereby enhancing the effectiveness of inducing the target agent toward suboptimal decision-making. Additionally, a critical state identification algorithm is designed to pinpoint the target agent's most vulnerable states, where suboptimal behavior from the victim leads to significant degradation in overall performance. Experimental results in diverse environments demonstrate the superiority of our method over existing approaches.
Weakly Supervised Temporal Sentence Grounding via Positive Sample Mining
May 10, 2025The task of weakly supervised temporal sentence grounding (WSTSG) aims to detect temporal intervals corresponding to a language description from untrimmed videos with only video-level video-language correspondence. For an anchor sample, most existing approaches generate negative samples either from other videos or within the same video for contrastive learning. However, some training samples are highly similar to the anchor sample, directly regarding them as negative samples leads to difficulties for optimization and ignores the correlations between these similar samples and the anchor sample. To address this, we propose Positive Sample Mining (PSM), a novel framework that mines positive samples from the training set to provide more discriminative supervision. Specifically, for a given anchor sample, we partition the remaining training set into semantically similar and dissimilar subsets based on the similarity of their text queries. To effectively leverage these correlations, we introduce a PSM-guided contrastive loss to ensure that the anchor proposal is closer to similar samples and further from dissimilar ones. Additionally, we design a PSM-guided rank loss to ensure that similar samples are closer to the anchor proposal than to the negative intra-video proposal, aiming to distinguish the anchor proposal and the negative intra-video proposal. Experiments on the WSTSG and grounded VideoQA tasks demonstrate the effectiveness and superiority of our method.
A Survey on Small Sample Imbalance Problem: Metrics, Feature Analysis, and Solutions
Apr 21, 2025The small sample imbalance (S&I) problem is a major challenge in machine learning and data analysis. It is characterized by a small number of samples and an imbalanced class distribution, which leads to poor model performance. In addition, indistinct inter-class feature distributions further complicate classification tasks. Existing methods often rely on algorithmic heuristics without sufficiently analyzing the underlying data characteristics. We argue that a detailed analysis from the data perspective is essential before developing an appropriate solution. Therefore, this paper proposes a systematic analytical framework for the S\&I problem. We first summarize imbalance metrics and complexity analysis methods, highlighting the need for interpretable benchmarks to characterize S&I problems. Second, we review recent solutions for conventional, complexity-based, and extreme S&I problems, revealing methodological differences in handling various data distributions. Our summary finds that resampling remains a widely adopted solution. However, we conduct experiments on binary and multiclass datasets, revealing that classifier performance differences significantly exceed the improvements achieved through resampling. Finally, this paper highlights open questions and discusses future trends.
VideoChat-R1: Enhancing Spatio-Temporal Perception via Reinforcement Fine-Tuning
Apr 10, 2025Recent advancements in reinforcement learning have significantly advanced the reasoning capabilities of multimodal large language models (MLLMs). While approaches such as Group Relative Policy Optimization (GRPO) and rule-based reward mechanisms demonstrate promise in text and image domains, their application to video understanding remains limited. This paper presents a systematic exploration of Reinforcement Fine-Tuning (RFT) with GRPO for video MLLMs, aiming to enhance spatio-temporal perception while maintaining general capabilities. Our experiments reveal that RFT is highly data-efficient for task-specific improvements. Through multi-task RFT on spatio-temporal perception objectives with limited samples, we develop VideoChat-R1, a powerful video MLLM that achieves state-of-the-art performance on spatio-temporal perception tasks without sacrificing chat ability, while exhibiting emerging spatio-temporal reasoning abilities. Compared to Qwen2.5-VL-7B, VideoChat-R1 boosts performance several-fold in tasks like temporal grounding (+31.8) and object tracking (+31.2). Additionally, it significantly improves on general QA benchmarks such as VideoMME (+0.9), MVBench (+1.0), and Perception Test (+0.9). Our findings underscore the potential of RFT for specialized task enhancement of Video MLLMs. We hope our work offers valuable insights for future RL research in video MLLMs.
AutoMisty: A Multi-Agent LLM Framework for Automated Code Generation in the Misty Social Robot
Mar 09, 2025The social robot's open API allows users to customize open-domain interactions. However, it remains inaccessible to those without programming experience. In this work, we introduce AutoMisty, the first multi-agent collaboration framework powered by large language models (LLMs), to enable the seamless generation of executable Misty robot code from natural language instructions. AutoMisty incorporates four specialized agent modules to manage task decomposition, assignment, problem-solving, and result synthesis. Each agent incorporates a two-layer optimization mechanism, with self-reflection for iterative refinement and human-in-the-loop for better alignment with user preferences. AutoMisty ensures a transparent reasoning process, allowing users to iteratively refine tasks through natural language feedback for precise execution. To evaluate AutoMisty's effectiveness, we designed a benchmark task set spanning four levels of complexity and conducted experiments in a real Misty robot environment. Extensive evaluations demonstrate that AutoMisty not only consistently generates high-quality code but also enables precise code control, significantly outperforming direct reasoning with ChatGPT-4o and ChatGPT-o1. All code, optimized APIs, and experimental videos will be publicly released through the webpage: https://wangxiaoshawn.github.io/AutoMisty.html
Ig3D: Integrating 3D Face Representations in Facial Expression Inference
Aug 29, 2024Reconstructing 3D faces with facial geometry from single images has allowed for major advances in animation, generative models, and virtual reality. However, this ability to represent faces with their 3D features is not as fully explored by the facial expression inference (FEI) community. This study therefore aims to investigate the impacts of integrating such 3D representations into the FEI task, specifically for facial expression classification and face-based valence-arousal (VA) estimation. To accomplish this, we first assess the performance of two 3D face representations (both based on the 3D morphable model, FLAME) for the FEI tasks. We further explore two fusion architectures, intermediate fusion and late fusion, for integrating the 3D face representations with existing 2D inference frameworks. To evaluate our proposed architecture, we extract the corresponding 3D representations and perform extensive tests on the AffectNet and RAF-DB datasets. Our experimental results demonstrate that our proposed method outperforms the state-of-the-art AffectNet VA estimation and RAF-DB classification tasks. Moreover, our method can act as a complement to other existing methods to boost performance in many emotion inference tasks.
MSCT: Addressing Time-Varying Confounding with Marginal Structural Causal Transformer for Counterfactual Post-Crash Traffic Prediction
Jul 19, 2024



Traffic crashes profoundly impede traffic efficiency and pose economic challenges. Accurate prediction of post-crash traffic status provides essential information for evaluating traffic perturbations and developing effective solutions. Previous studies have established a series of deep learning models to predict post-crash traffic conditions, however, these correlation-based methods cannot accommodate the biases caused by time-varying confounders and the heterogeneous effects of crashes. The post-crash traffic prediction model needs to estimate the counterfactual traffic speed response to hypothetical crashes under various conditions, which demonstrates the necessity of understanding the causal relationship between traffic factors. Therefore, this paper presents the Marginal Structural Causal Transformer (MSCT), a novel deep learning model designed for counterfactual post-crash traffic prediction. To address the issue of time-varying confounding bias, MSCT incorporates a structure inspired by Marginal Structural Models and introduces a balanced loss function to facilitate learning of invariant causal features. The proposed model is treatment-aware, with a specific focus on comprehending and predicting traffic speed under hypothetical crash intervention strategies. In the absence of ground-truth data, a synthetic data generation procedure is proposed to emulate the causal mechanism between traffic speed, crashes, and covariates. The model is validated using both synthetic and real-world data, demonstrating that MSCT outperforms state-of-the-art models in multi-step-ahead prediction performance. This study also systematically analyzes the impact of time-varying confounding bias and dataset distribution on model performance, contributing valuable insights into counterfactual prediction for intelligent transportation systems.
Towards Open Domain Text-Driven Synthesis of Multi-Person Motions
May 28, 2024This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
SignAvatar: Sign Language 3D Motion Reconstruction and Generation
May 13, 2024Achieving expressive 3D motion reconstruction and automatic generation for isolated sign words can be challenging, due to the lack of real-world 3D sign-word data, the complex nuances of signing motions, and the cross-modal understanding of sign language semantics. To address these challenges, we introduce SignAvatar, a framework capable of both word-level sign language reconstruction and generation. SignAvatar employs a transformer-based conditional variational autoencoder architecture, effectively establishing relationships across different semantic modalities. Additionally, this approach incorporates a curriculum learning strategy to enhance the model's robustness and generalization, resulting in more realistic motions. Furthermore, we contribute the ASL3DWord dataset, composed of 3D joint rotation data for the body, hands, and face, for unique sign words. We demonstrate the effectiveness of SignAvatar through extensive experiments, showcasing its superior reconstruction and automatic generation capabilities. The code and dataset are available on the project page.
EgoExoLearn: A Dataset for Bridging Asynchronous Ego- and Exo-centric View of Procedural Activities in Real World
Mar 24, 2024Being able to map the activities of others into one's own point of view is one fundamental human skill even from a very early age. Taking a step toward understanding this human ability, we introduce EgoExoLearn, a large-scale dataset that emulates the human demonstration following process, in which individuals record egocentric videos as they execute tasks guided by demonstration videos. Focusing on the potential applications in daily assistance and professional support, EgoExoLearn contains egocentric and demonstration video data spanning 120 hours captured in daily life scenarios and specialized laboratories. Along with the videos we record high-quality gaze data and provide detailed multimodal annotations, formulating a playground for modeling the human ability to bridge asynchronous procedural actions from different viewpoints. To this end, we present benchmarks such as cross-view association, cross-view action planning, and cross-view referenced skill assessment, along with detailed analysis. We expect EgoExoLearn can serve as an important resource for bridging the actions across views, thus paving the way for creating AI agents capable of seamlessly learning by observing humans in the real world. Code and data can be found at: https://github.com/OpenGVLab/EgoExoLearn