 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Perspectives: A Survey on Cross-view Collaborative Intelligence with Egocentric-Exocentric Vision
Jun 06, 2025



Perceiving the world from both egocentric (first-person) and exocentric (third-person) perspectives is fundamental to human cognition, enabling rich and complementary understanding of dynamic environments. In recent years, allowing the machines to leverage the synergistic potential of these dual perspectives has emerged as a compelling research direction in video understanding. In this survey, we provide a comprehensive review of video understanding from both exocentric and egocentric viewpoints. We begin by highlighting the practical applications of integrating egocentric and exocentric techniques, envisioning their potential collaboration across domains. We then identify key research tasks to realize these applications. Next, we systematically organize and review recent advancements into three main research directions: (1) leveraging egocentric data to enhance exocentric understanding, (2) utilizing exocentric data to improve egocentric analysis, and (3) joint learning frameworks that unify both perspectives. For each direction, we analyze a diverse set of tasks and relevant works. Additionally, we discuss benchmark datasets that support research in both perspectives, evaluating their scope, diversity, and applicability. Finally, we discuss limitations in current works and propose promising future research directions. By synthesizing insights from both perspectives, our goal is to inspire advancements in video understanding and artificial intelligence, bringing machines closer to perceiving the world in a human-like manner. A GitHub repo of related works can be found at https://github.com/ayiyayi/Awesome-Egocentric-and-Exocentric-Vision.
EgoExo-Gen: Ego-centric Video Prediction by Watching Exo-centric Videos
Apr 16, 2025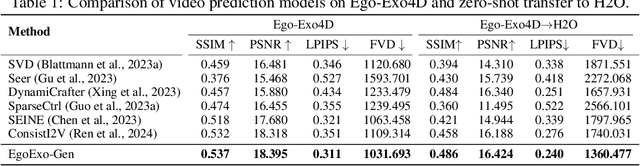
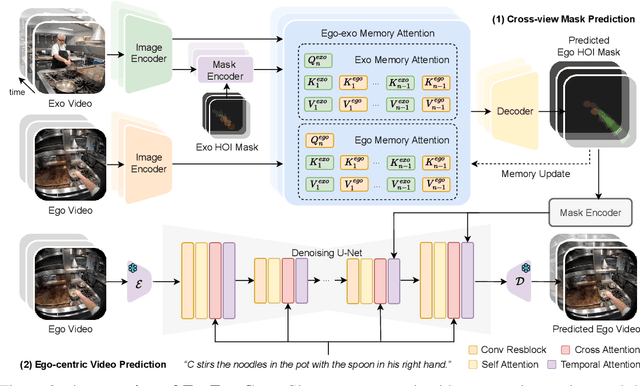

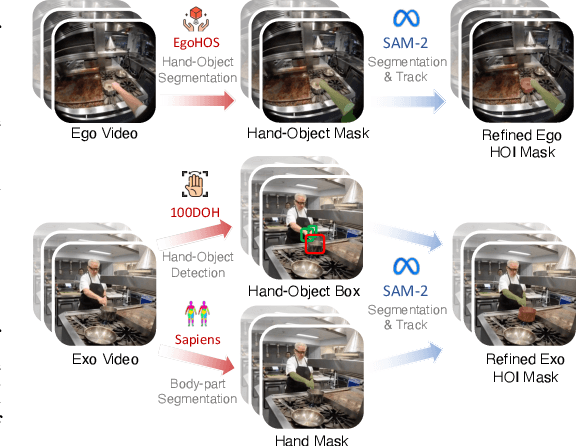
Generating videos in the first-person perspective has broad application prospects in the field of augmented reality and embodied intelligence. In this work, we explore the cross-view video prediction task, where given an exo-centric video, the first frame of the corresponding ego-centric video, and textual instructions, the goal is to generate futur frames of the ego-centric video. Inspired by the notion that hand-object interactions (HOI) in ego-centric videos represent the primary intentions and actions of the current actor, we present EgoExo-Gen that explicitly models the hand-object dynamics for cross-view video prediction. EgoExo-Gen consists of two stages. First, we design a cross-view HOI mask prediction model that anticipates the HOI masks in future ego-frames by modeling the spatio-temporal ego-exo correspondence. Next, we employ a video diffusion model to predict future ego-frames using the first ego-frame and textual instructions, while incorporating the HOI masks as structural guidance to enhance prediction quality. To facilitate training, we develop an automated pipeline to generate pseudo HOI masks for both ego- and exo-videos by exploiting vision foundation models. Extensive experiments demonstrate that our proposed EgoExo-Gen achieves better prediction performance compared to previous video prediction models on the Ego-Exo4D and H2O benchmark datasets, with the HOI masks significantly improving the generation of hands and interactive objects in the ego-centric videos.
An Egocentric Vision-Language Model based Portable Real-time Smart Assistant
Mar 06, 2025We present Vinci, a vision-language system designed to provide real-time, comprehensive AI assistance on portable devices. At its core, Vinci leverages EgoVideo-VL, a novel model that integrates an egocentric vision foundation model with a large language model (LLM), enabling advanced functionalities such as scene understanding, temporal grounding, video summarization, and future planning. To enhance its utility, Vinci incorporates a memory module for processing long video streams in real time while retaining contextual history, a generation module for producing visual action demonstrations, and a retrieval module that bridges egocentric and third-person perspectives to provide relevant how-to videos for skill acquisition. Unlike existing systems that often depend on specialized hardware, Vinci is hardware-agnostic, supporting deployment across a wide range of devices, including smartphones and wearable cameras. In our experiments, we first demonstrate the superior performance of EgoVideo-VL on multiple public benchmarks, showcasing its vision-language reasoning and contextual understanding capabilities. We then conduct a series of user studies to evaluate the real-world effectiveness of Vinci, highlighting its adaptability and usability in diverse scenarios. We hope Vinci can establish a new framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. Including the frontend, backend, and models, all codes of Vinci are available at https://github.com/OpenGVLab/vinci.
Modeling Fine-Grained Hand-Object Dynamics for Egocentric Video Representation Learning
Mar 02, 2025In egocentric video understanding, the motion of hands and objects as well as their interactions play a significant role by nature. However, existing egocentric video representation learning methods mainly focus on aligning video representation with high-level narrations, overlooking the intricate dynamics between hands and objects. In this work, we aim to integrate the modeling of fine-grained hand-object dynamics into the video representation learning process. Since no suitable data is available, we introduce HOD, a novel pipeline employing a hand-object detector and a large language model to generate high-quality narrations with detailed descriptions of hand-object dynamics. To learn these fine-grained dynamics, we propose EgoVideo, a model with a new lightweight motion adapter to capture fine-grained hand-object motion information. Through our co-training strategy, EgoVideo effectively and efficiently leverages the fine-grained hand-object dynamics in the HOD data. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple egocentric downstream tasks, including improvements of 6.3% in EK-100 multi-instance retrieval, 5.7% in EK-100 classification, and 16.3% in EGTEA classification in zero-shot settings. Furthermore, our model exhibits robust generalization capabilities in hand-object interaction and robot manipulation tasks. Code and data are available at https://github.com/OpenRobotLab/EgoHOD/.
Vinci: A Real-time Embodied Smart Assistant based on Egocentric Vision-Language Model
Dec 30, 2024



We introduce Vinci, a real-time embodied smart assistant built upon an egocentric vision-language model. Designed for deployment on portable devices such as smartphones and wearable cameras, Vinci operates in an "always on" mode, continuously observing the environment to deliver seamless interaction and assistance. Users can wake up the system and engage in natural conversations to ask questions or seek assistance, with responses delivered through audio for hands-free convenience. With its ability to process long video streams in real-time, Vinci can answer user queries about current observations and historical context while also providing task planning based on past interactions. To further enhance usability, Vinci integrates a video generation module that creates step-by-step visual demonstrations for tasks that require detailed guidance. We hope that Vinci can establish a robust framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. We release the complete implementation for the development of the device in conjunction with a demo web platform to test uploaded videos at https://github.com/OpenGVLab/vinci.
CG-Bench: Clue-grounded Question Answering Benchmark for Long Video Understanding
Dec 16, 2024



Most existing video understanding benchmarks for multimodal large language models (MLLMs) focus only on short videos. The limited number of benchmarks for long video understanding often rely solely on multiple-choice questions (MCQs). However, because of the inherent limitation of MCQ-based evaluation and the increasing reasoning ability of MLLMs, models can give the current answer purely by combining short video understanding with elimination, without genuinely understanding the video content. To address this gap, we introduce CG-Bench, a novel benchmark designed for clue-grounded question answering in long videos. CG-Bench emphasizes the model's ability to retrieve relevant clues for questions, enhancing evaluation credibility. It features 1,219 manually curated videos categorized by a granular system with 14 primary categories, 171 secondary categories, and 638 tertiary categories, making it the largest benchmark for long video analysis. The benchmark includes 12,129 QA pairs in three major question types: perception, reasoning, and hallucination. Compensating the drawbacks of pure MCQ-based evaluation, we design two novel clue-based evaluation methods: clue-grounded white box and black box evaluations, to assess whether the model generates answers based on the correct understanding of the video. We evaluate multiple closed-source and open-source MLLMs on CG-Bench. Results indicate that current models significantly underperform in understanding long videos compared to short ones, and a significant gap exists between open-source and commercial models. We hope CG-Bench can advance the development of more trustworthy and capable MLLMs for long video understanding. All annotations and video data are released at https://cg-bench.github.io/leaderboard/.
EgoVideo: Exploring Egocentric Foundation Model and Downstream Adaptation
Jun 27, 2024



In this report, we present our solutions to the EgoVis Challenges in CVPR 2024, including five tracks in the Ego4D challenge and three tracks in the EPIC-Kitchens challenge. Building upon the video-language two-tower model and leveraging our meticulously organized egocentric video data, we introduce a novel foundation model called EgoVideo. This model is specifically designed to cater to the unique characteristics of egocentric videos and provides strong support for our competition submissions. In the Ego4D challenges, we tackle various tasks including Natural Language Queries, Step Grounding, Moment Queries, Short-term Object Interaction Anticipation, and Long-term Action Anticipation. In addition, we also participate in the EPIC-Kitchens challenge, where we engage in the Action Recognition, Multiple Instance Retrieval, and Domain Adaptation for Action Recognition tracks. By adapting EgoVideo to these diverse tasks, we showcase its versatility and effectiveness in different egocentric video analysis scenarios, demonstrating the powerful representation ability of EgoVideo as an egocentric foundation model. Our codebase and pretrained models are publicly available at https://github.com/OpenGVLab/EgoVideo.
EgoExoLearn: A Dataset for Bridging Asynchronous Ego- and Exo-centric View of Procedural Activities in Real World
Mar 24, 2024Being able to map the activities of others into one's own point of view is one fundamental human skill even from a very early age. Taking a step toward understanding this human ability, we introduce EgoExoLearn, a large-scale dataset that emulates the human demonstration following process, in which individuals record egocentric videos as they execute tasks guided by demonstration videos. Focusing on the potential applications in daily assistance and professional support, EgoExoLearn contains egocentric and demonstration video data spanning 120 hours captured in daily life scenarios and specialized laboratories. Along with the videos we record high-quality gaze data and provide detailed multimodal annotations, formulating a playground for modeling the human ability to bridge asynchronous procedural actions from different viewpoints. To this end, we present benchmarks such as cross-view association, cross-view action planning, and cross-view referenced skill assessment, along with detailed analysis. We expect EgoExoLearn can serve as an important resource for bridging the actions across views, thus paving the way for creating AI agents capable of seamlessly learning by observing humans in the real world. Code and data can be found at: https://github.com/OpenGVLab/EgoExoLearn
InternVideo2: Scaling Video Foundation Models for Multimodal Video Understanding
Mar 22, 2024We introduce InternVideo2, a new video foundation model (ViFM) that achieves the state-of-the-art performance in action recognition, video-text tasks, and video-centric dialogue. Our approach employs a progressive training paradigm that unifies the different self- or weakly-supervised learning frameworks of masked video token reconstruction, cross-modal contrastive learning, and next token prediction. Different training stages would guide our model to capture different levels of structure and semantic information through different pretext tasks. At the data level, we prioritize the spatiotemporal consistency by semantically segmenting videos and generating video-audio-speech captions. This improves the alignment between video and text. We scale both data and model size for our InternVideo2. Through extensive experiments, we validate our designs and demonstrate the state-of-the-art performance on over 60 video and audio tasks. Notably, our model outperforms others on various video-related captioning, dialogue, and long video understanding benchmarks, highlighting its ability to reason and comprehend long temporal contexts. Code and models are available at https://github.com/OpenGVLab/InternVideo2/.
Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
Mar 14, 2024



Understanding videos is one of the fundamental directions in computer vision research, with extensive efforts dedicated to exploring various architectures such as RNN, 3D CNN, and Transformers. The newly proposed architecture of state space model, e.g., Mamba, shows promising traits to extend its success in long sequence modeling to video modeling. To assess whether Mamba can be a viable alternative to Transformers in the video understanding domain, in this work, we conduct a comprehensive set of studies, probing different roles Mamba can play in modeling videos, while investigating diverse tasks where Mamba could exhibit superiority. We categorize Mamba into four roles for modeling videos, deriving a Video Mamba Suite composed of 14 models/modules, and evaluating them on 12 video understanding tasks. Our extensive experiments reveal the strong potential of Mamba on both video-only and video-language tasks while showing promising efficiency-performance trade-offs. We hope this work could provide valuable data points and insights for future research on video understanding. Code is public: https://github.com/OpenGVLab/video-mamba-suite.