 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHADSF: Aspect Aware Semantic Control for Explainable Recommendation
Oct 30, 2025Recent advances in large language models (LLMs) promise more effective information extraction for review-based recommender systems, yet current methods still (i) mine free-form reviews without scope control, producing redundant and noisy representations, (ii) lack principled metrics that link LLM hallucination to downstream effectiveness, and (iii) leave the cost-quality trade-off across model scales largely unexplored. We address these gaps with the Hyper-Adaptive Dual-Stage Semantic Framework (HADSF), a two-stage approach that first induces a compact, corpus-level aspect vocabulary via adaptive selection and then performs vocabulary-guided, explicitly constrained extraction of structured aspect-opinion triples. To assess the fidelity of the resulting representations, we introduce Aspect Drift Rate (ADR) and Opinion Fidelity Rate (OFR) and empirically uncover a nonmonotonic relationship between hallucination severity and rating prediction error. Experiments on approximately 3 million reviews across LLMs spanning 1.5B-70B parameters show that, when integrated into standard rating predictors, HADSF yields consistent reductions in prediction error and enables smaller models to achieve competitive performance in representative deployment scenarios. We release code, data pipelines, and metric implementations to support reproducible research on hallucination-aware, LLM-enhanced explainable recommendation. Code is available at https://github.com/niez233/HADSF
NovelSeek: When Agent Becomes the Scientist -- Building Closed-Loop System from Hypothesis to Verification
May 22, 2025
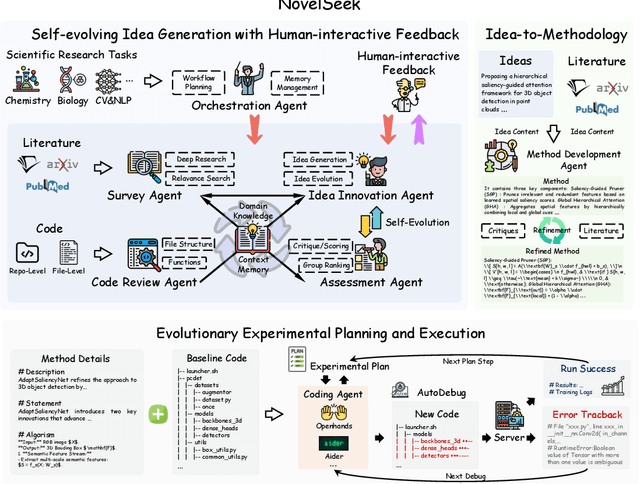

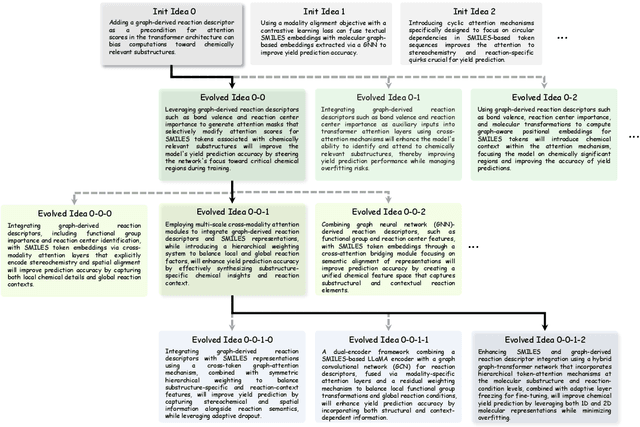
Artificial Intelligence (AI) is accelerating the transformation of scientific research paradigms, not only enhancing research efficiency but also driving innovation. We introduce NovelSeek, a unified closed-loop multi-agent framework to conduct Autonomous Scientific Research (ASR) across various scientific research fields, enabling researchers to tackle complicated problems in these fields with unprecedented speed and precision. NovelSeek highlights three key advantages: 1) Scalability: NovelSeek has demonstrated its versatility across 12 scientific research tasks, capable of generating innovative ideas to enhance the performance of baseline code. 2) Interactivity: NovelSeek provides an interface for human expert feedback and multi-agent interaction in automated end-to-end processes, allowing for the seamless integration of domain expert knowledge. 3) Efficiency: NovelSeek has achieved promising performance gains in several scientific fields with significantly less time cost compared to human efforts. For instance, in reaction yield prediction, it increased from 27.6% to 35.4% in just 12 hours; in enhancer activity prediction, accuracy rose from 0.52 to 0.79 with only 4 hours of processing; and in 2D semantic segmentation, precision advanced from 78.8% to 81.0% in a mere 30 hours.
An Egocentric Vision-Language Model based Portable Real-time Smart Assistant
Mar 06, 2025We present Vinci, a vision-language system designed to provide real-time, comprehensive AI assistance on portable devices. At its core, Vinci leverages EgoVideo-VL, a novel model that integrates an egocentric vision foundation model with a large language model (LLM), enabling advanced functionalities such as scene understanding, temporal grounding, video summarization, and future planning. To enhance its utility, Vinci incorporates a memory module for processing long video streams in real time while retaining contextual history, a generation module for producing visual action demonstrations, and a retrieval module that bridges egocentric and third-person perspectives to provide relevant how-to videos for skill acquisition. Unlike existing systems that often depend on specialized hardware, Vinci is hardware-agnostic, supporting deployment across a wide range of devices, including smartphones and wearable cameras. In our experiments, we first demonstrate the superior performance of EgoVideo-VL on multiple public benchmarks, showcasing its vision-language reasoning and contextual understanding capabilities. We then conduct a series of user studies to evaluate the real-world effectiveness of Vinci, highlighting its adaptability and usability in diverse scenarios. We hope Vinci can establish a new framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. Including the frontend, backend, and models, all codes of Vinci are available at https://github.com/OpenGVLab/vinci.
Vinci: A Real-time Embodied Smart Assistant based on Egocentric Vision-Language Model
Dec 30, 2024



We introduce Vinci, a real-time embodied smart assistant built upon an egocentric vision-language model. Designed for deployment on portable devices such as smartphones and wearable cameras, Vinci operates in an "always on" mode, continuously observing the environment to deliver seamless interaction and assistance. Users can wake up the system and engage in natural conversations to ask questions or seek assistance, with responses delivered through audio for hands-free convenience. With its ability to process long video streams in real-time, Vinci can answer user queries about current observations and historical context while also providing task planning based on past interactions. To further enhance usability, Vinci integrates a video generation module that creates step-by-step visual demonstrations for tasks that require detailed guidance. We hope that Vinci can establish a robust framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. We release the complete implementation for the development of the device in conjunction with a demo web platform to test uploaded videos at https://github.com/OpenGVLab/vinci.
InternLM-XComposer2.5-OmniLive: A Comprehensive Multimodal System for Long-term Streaming Video and Audio Interactions
Dec 12, 2024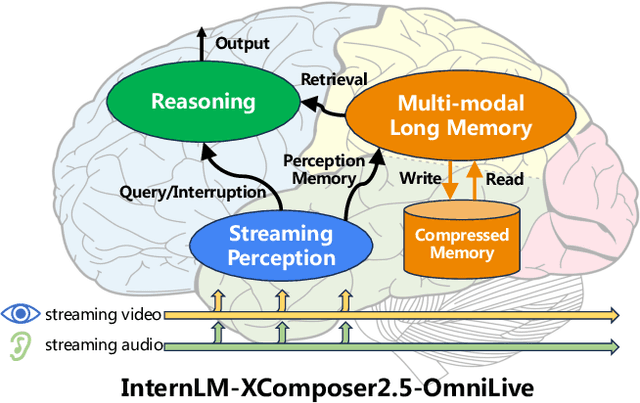
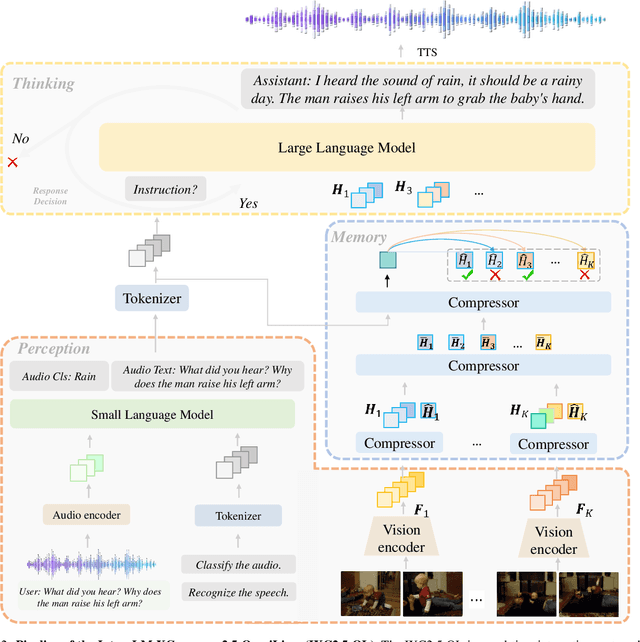

Creating AI systems that can interact with environments over long periods, similar to human cognition, has been a longstanding research goal. Recent advancements in multimodal large language models (MLLMs) have made significant strides in open-world understanding. However, the challenge of continuous and simultaneous streaming perception, memory, and reasoning remains largely unexplored. Current MLLMs are constrained by their sequence-to-sequence architecture, which limits their ability to process inputs and generate responses simultaneously, akin to being unable to think while perceiving. Furthermore, relying on long contexts to store historical data is impractical for long-term interactions, as retaining all information becomes costly and inefficient. Therefore, rather than relying on a single foundation model to perform all functions, this project draws inspiration from the concept of the Specialized Generalist AI and introduces disentangled streaming perception, reasoning, and memory mechanisms, enabling real-time interaction with streaming video and audio input. The proposed framework InternLM-XComposer2.5-OmniLive (IXC2.5-OL) consists of three key modules: (1) Streaming Perception Module: Processes multimodal information in real-time, storing key details in memory and triggering reasoning in response to user queries. (2) Multi-modal Long Memory Module: Integrates short-term and long-term memory, compressing short-term memories into long-term ones for efficient retrieval and improved accuracy. (3) Reasoning Module: Responds to queries and executes reasoning tasks, coordinating with the perception and memory modules. This project simulates human-like cognition, enabling multimodal large language models to provide continuous and adaptive service over time.
Analysis on DeepLabV3+ Performance for Automatic Steel Defects Detection
Apr 15, 2020
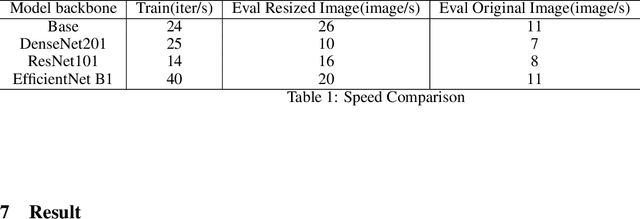
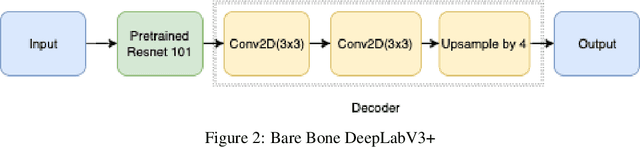

Our works experimented DeepLabV3+ with different backbones on a large volume of steel images aiming to automatically detect different types of steel defects. Our methods applied random weighted augmentation to balance different defects types in the training set. And then applied DeeplabV3+ model three different backbones, ResNet, DenseNet and EfficientNet, on segmenting defection regions on the steel images. Based on experiments, we found that applying ResNet101 or EfficientNet as backbones could reach the best IoU scores on the test set, which is around 0.57, comparing with 0.325 for using DenseNet. Also, DeepLabV3+ model with ResNet101 as backbone has the fewest training time.