 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausalMotion: Structured Physical Reasoning as Keyframe and Trajectory Guidance for Training-Free Video Generation
Jun 12, 2026Recent advances in diffusion-based video generation have significantly improved visual quality and short-term temporal coherence. However, existing methods still struggle to produce videos with physically consistent and causally plausible dynamics, especially in scenarios involving long-horizon interactions. This limitation arises from the fact that video diffusion models primarily learn physical consistency implicitly, while vision-language models can directly model physical laws. Based on this idea, in this work, we propose \textbf{CausalMotion}, a training-free framework that injects explicit physical reasoning into video generation through structured intermediate representations. Our key idea is to decouple reasoning from generation by leveraging a vision-language model to decompose a text prompt into a sequence of causally consistent keyframes and object-centric motion trajectories. These representations are then aligned and integrated as soft constraints to guide a pretrained video diffusion model during inference. This design enables explicit modeling of object dynamics and causal transitions without requiring additional training or supervision. Extensive experiments show that our method consistently improves physical plausibility and temporal coherence, particularly in dynamics-intensive scenarios, while maintaining high perceptual video quality.
TIDE: Task-Isolated Diffusion for Unified Video Editing and Generation
Jun 06, 2026Recent advances in Diffusion Transformers have driven rapid progress in video generation and editing, yet these capabilities are still handled by separate, task-specific models. Building a unified framework that supports diverse video tasks remains an open challenge: existing unified attempts either require dedicated auxiliary encoders or lack explicit mechanisms to distinguish heterogeneous conditioning tokens, struggling when the number and type of visual conditions vary across tasks. We propose TIDE, a unified framework that integrates instruction-based editing, reference-guided editing, and multi-reference generation. At its core, we introduce per-token task embeddings that assign each input token a task-specific identifier, enabling the model to explicitly disambiguate target, source, and reference tokens. To simultaneously capture high-level semantic understanding and fine-grained structural fidelity, we design a dual-path conditioning scheme that couples a vision-language model with a VAE latent path for complementary signals. We further devise a multi-task progressive training strategy that incrementally introduces tasks of increasing complexity, effectively harmonizing diverse objectives and enabling smooth generalization across heterogeneous task distributions. Extensive experiments on multiple video editing and generation benchmarks demonstrate that TIDE achieves state-of-the-art performance across all evaluated tasks. Our project page is available at https://LittleWork123.github.io/tide.
PARE: Pruning and Adaptive Routing for Efficient Video Generation
May 26, 2026Video Diffusion Transformers (DiTs) generate high-quality videos but demand substantial compute due to wide blocks, deep architectures, and iterative sampling. Recent methods reduce cost by compressing width, depth, or sampling steps, but typically commit to a fixed architecture that cannot adapt to individual inputs or denoising stages. We propose PARE (Pruning and Adaptive Routing for Efficient video generation), which jointly compresses width and depth with structure-aware pruning and input-adaptive routing. For width, we observe that attention heads specialize into spatial and temporal roles, and design importance scoring that accounts for this distinction to prevent motion-critical temporal heads from being pruned prematurely. For depth, we train a lightweight router conditioned on denoising timestep and visual content to dynamically select which blocks to execute at each step, enabling per-input compute adaptation rather than static block removal. A progressive pipeline first recovers width-pruned quality via distillation, then jointly optimizes the student and router to decouple the two learning objectives. Experiments on Wan2.1-14B for both image-to-video and text-to-video generation show that PARE substantially reduces per-step computation while preserving quality across VBench dimensions, and composes with step distillation for further acceleration.
ShotDirector: Directorially Controllable Multi-Shot Video Generation with Cinematographic Transitions
Dec 11, 2025
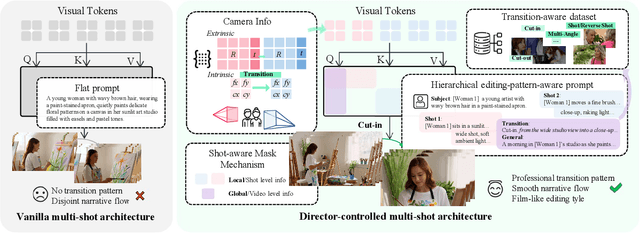

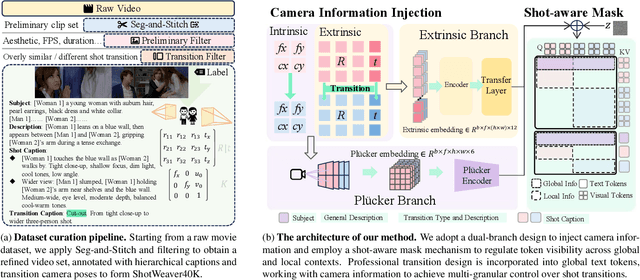
Shot transitions play a pivotal role in multi-shot video generation, as they determine the overall narrative expression and the directorial design of visual storytelling. However, recent progress has primarily focused on low-level visual consistency across shots, neglecting how transitions are designed and how cinematographic language contributes to coherent narrative expression. This often leads to mere sequential shot changes without intentional film-editing patterns. To address this limitation, we propose ShotDirector, an efficient framework that integrates parameter-level camera control and hierarchical editing-pattern-aware prompting. Specifically, we adopt a camera control module that incorporates 6-DoF poses and intrinsic settings to enable precise camera information injection. In addition, a shot-aware mask mechanism is employed to introduce hierarchical prompts aware of professional editing patterns, allowing fine-grained control over shot content. Through this design, our framework effectively combines parameter-level conditions with high-level semantic guidance, achieving film-like controllable shot transitions. To facilitate training and evaluation, we construct ShotWeaver40K, a dataset that captures the priors of film-like editing patterns, and develop a set of evaluation metrics for controllable multi-shot video generation. Extensive experiments demonstrate the effectiveness of our framework.
THEval. Evaluation Framework for Talking Head Video Generation
Nov 06, 2025Video generation has achieved remarkable progress, with generated videos increasingly resembling real ones. However, the rapid advance in generation has outpaced the development of adequate evaluation metrics. Currently, the assessment of talking head generation primarily relies on limited metrics, evaluating general video quality, lip synchronization, and on conducting user studies. Motivated by this, we propose a new evaluation framework comprising 8 metrics related to three dimensions (i) quality, (ii) naturalness, and (iii) synchronization. In selecting the metrics, we place emphasis on efficiency, as well as alignment with human preferences. Based on this considerations, we streamline to analyze fine-grained dynamics of head, mouth, and eyebrows, as well as face quality. Our extensive experiments on 85,000 videos generated by 17 state-of-the-art models suggest that while many algorithms excel in lip synchronization, they face challenges with generating expressiveness and artifact-free details. These videos were generated based on a novel real dataset, that we have curated, in order to mitigate bias of training data. Our proposed benchmark framework is aimed at evaluating the improvement of generative methods. Original code, dataset and leaderboards will be publicly released and regularly updated with new methods, in order to reflect progress in the field.
LIA-X: Interpretable Latent Portrait Animator
Aug 13, 2025We introduce LIA-X, a novel interpretable portrait animator designed to transfer facial dynamics from a driving video to a source portrait with fine-grained control. LIA-X is an autoencoder that models motion transfer as a linear navigation of motion codes in latent space. Crucially, it incorporates a novel Sparse Motion Dictionary that enables the model to disentangle facial dynamics into interpretable factors. Deviating from previous 'warp-render' approaches, the interpretability of the Sparse Motion Dictionary allows LIA-X to support a highly controllable 'edit-warp-render' strategy, enabling precise manipulation of fine-grained facial semantics in the source portrait. This helps to narrow initial differences with the driving video in terms of pose and expression. Moreover, we demonstrate the scalability of LIA-X by successfully training a large-scale model with approximately 1 billion parameters on extensive datasets. Experimental results show that our proposed method outperforms previous approaches in both self-reenactment and cross-reenactment tasks across several benchmarks. Additionally, the interpretable and controllable nature of LIA-X supports practical applications such as fine-grained, user-guided image and video editing, as well as 3D-aware portrait video manipulation.
Consistent and Controllable Image Animation with Motion Linear Diffusion Transformers
Aug 10, 2025



Image animation has seen significant progress, driven by the powerful generative capabilities of diffusion models. However, maintaining appearance consistency with static input images and mitigating abrupt motion transitions in generated animations remain persistent challenges. While text-to-video (T2V) generation has demonstrated impressive performance with diffusion transformer models, the image animation field still largely relies on U-Net-based diffusion models, which lag behind the latest T2V approaches. Moreover, the quadratic complexity of vanilla self-attention mechanisms in Transformers imposes heavy computational demands, making image animation particularly resource-intensive. To address these issues, we propose MiraMo, a framework designed to enhance efficiency, appearance consistency, and motion smoothness in image animation. Specifically, MiraMo introduces three key elements: (1) A foundational text-to-video architecture replacing vanilla self-attention with efficient linear attention to reduce computational overhead while preserving generation quality; (2) A novel motion residual learning paradigm that focuses on modeling motion dynamics rather than directly predicting frames, improving temporal consistency; and (3) A DCT-based noise refinement strategy during inference to suppress sudden motion artifacts, complemented by a dynamics control module to balance motion smoothness and expressiveness. Extensive experiments against state-of-the-art methods validate the superiority of MiraMo in generating consistent, smooth, and controllable animations with accelerated inference speed. Additionally, we demonstrate the versatility of MiraMo through applications in motion transfer and video editing tasks.
GenHOI: Generalizing Text-driven 4D Human-Object Interaction Synthesis for Unseen Objects
Jun 18, 2025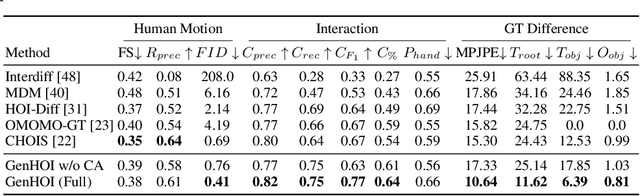
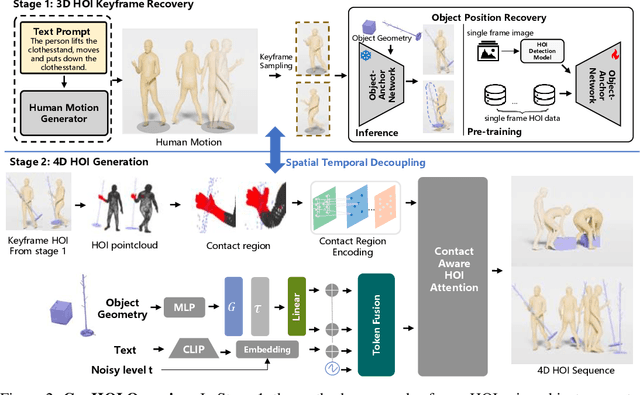
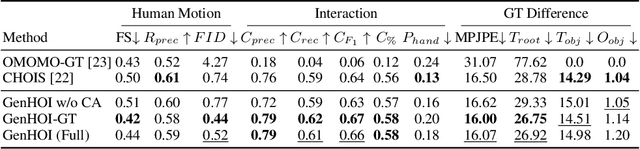
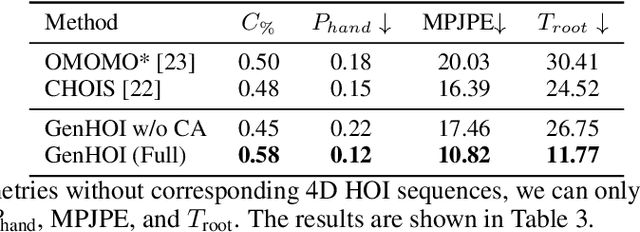
While diffusion models and large-scale motion datasets have advanced text-driven human motion synthesis, extending these advances to 4D human-object interaction (HOI) remains challenging, mainly due to the limited availability of large-scale 4D HOI datasets. In our study, we introduce GenHOI, a novel two-stage framework aimed at achieving two key objectives: 1) generalization to unseen objects and 2) the synthesis of high-fidelity 4D HOI sequences. In the initial stage of our framework, we employ an Object-AnchorNet to reconstruct sparse 3D HOI keyframes for unseen objects, learning solely from 3D HOI datasets, thereby mitigating the dependence on large-scale 4D HOI datasets. Subsequently, we introduce a Contact-Aware Diffusion Model (ContactDM) in the second stage to seamlessly interpolate sparse 3D HOI keyframes into densely temporally coherent 4D HOI sequences. To enhance the quality of generated 4D HOI sequences, we propose a novel Contact-Aware Encoder within ContactDM to extract human-object contact patterns and a novel Contact-Aware HOI Attention to effectively integrate the contact signals into diffusion models. Experimental results show that we achieve state-of-the-art results on the publicly available OMOMO and 3D-FUTURE datasets, demonstrating strong generalization abilities to unseen objects, while enabling high-fidelity 4D HOI generation.
Research on Aerodynamic Performance Prediction of Airfoils Based on a Fusion Algorithm of Transformer and GAN
Jun 08, 2025Predicting of airfoil aerodynamic performance is a key part of aircraft design optimization, but the traditional methods (such as wind tunnel test and CFD simulation) have the problems of high cost and low efficiency, and the existing data-driven models face the challenges of insufficient accuracy and strong data dependence in multi-objective prediction. Therefore, this study proposes a deep learning model, Deeptrans, based on the fusion of improved Transformer and generative Adversarial network (GAN), which aims to predict the multi-parameter aerodynamic performance of airfoil efficiently. By constructing a large-scale data set and designing a model structure that integrates a Transformer coding-decoding framework and confrontation training, synchronous and high-precision prediction of aerodynamic parameters is realized. Experiments show that the MSE loss of Deeptrans on the verification set is reduced to 5.6*10-6, and the single-sample prediction time is only 0.0056 seconds, which is nearly 700 times more efficient than the traditional CFD method. Horizontal comparison shows that the prediction accuracy is significantly better than the original Transformer, GAN, and VAE models. This study provides an efficient data-driven solution for airfoil aerodynamic performance prediction and a new idea for deep learning modeling complex flow problems.
Training-free Stylized Text-to-Image Generation with Fast Inference
May 25, 2025Although diffusion models exhibit impressive generative capabilities, existing methods for stylized image generation based on these models often require textual inversion or fine-tuning with style images, which is time-consuming and limits the practical applicability of large-scale diffusion models. To address these challenges, we propose a novel stylized image generation method leveraging a pre-trained large-scale diffusion model without requiring fine-tuning or any additional optimization, termed as OmniPainter. Specifically, we exploit the self-consistency property of latent consistency models to extract the representative style statistics from reference style images to guide the stylization process. Additionally, we then introduce the norm mixture of self-attention, which enables the model to query the most relevant style patterns from these statistics for the intermediate output content features. This mechanism also ensures that the stylized results align closely with the distribution of the reference style images. Our qualitative and quantitative experimental results demonstrate that the proposed method outperforms state-of-the-art approaches.