 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTVCrafter: 4D Motion Tokenization for Open-World Human Image Animation
May 15, 2025


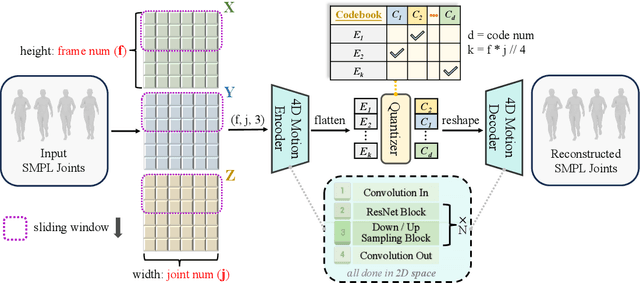
Human image animation has gained increasing attention and developed rapidly due to its broad applications in digital humans. However, existing methods rely largely on 2D-rendered pose images for motion guidance, which limits generalization and discards essential 3D information for open-world animation. To tackle this problem, we propose MTVCrafter (Motion Tokenization Video Crafter), the first framework that directly models raw 3D motion sequences (i.e., 4D motion) for human image animation. Specifically, we introduce 4DMoT (4D motion tokenizer) to quantize 3D motion sequences into 4D motion tokens. Compared to 2D-rendered pose images, 4D motion tokens offer more robust spatio-temporal cues and avoid strict pixel-level alignment between pose image and character, enabling more flexible and disentangled control. Then, we introduce MV-DiT (Motion-aware Video DiT). By designing unique motion attention with 4D positional encodings, MV-DiT can effectively leverage motion tokens as 4D compact yet expressive context for human image animation in the complex 3D world. Hence, it marks a significant step forward in this field and opens a new direction for pose-guided human video generation. Experiments show that our MTVCrafter achieves state-of-the-art results with an FID-VID of 6.98, surpassing the second-best by 65%. Powered by robust motion tokens, MTVCrafter also generalizes well to diverse open-world characters (single/multiple, full/half-body) across various styles and scenarios. Our video demos and code are provided in the supplementary material and at this anonymous GitHub link: https://anonymous.4open.science/r/MTVCrafter-1B13.
V-Stylist: Video Stylization via Collaboration and Reflection of MLLM Agents
Mar 15, 2025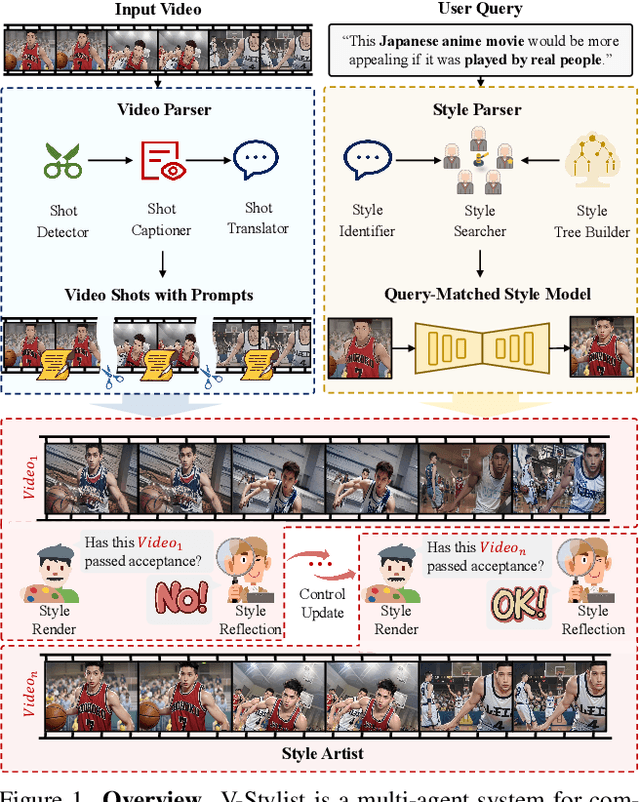
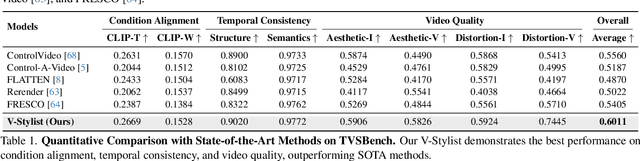


Despite the recent advancement in video stylization, most existing methods struggle to render any video with complex transitions, based on an open style description of user query. To fill this gap, we introduce a generic multi-agent system for video stylization, V-Stylist, by a novel collaboration and reflection paradigm of multi-modal large language models. Specifically, our V-Stylist is a systematical workflow with three key roles: (1) Video Parser decomposes the input video into a number of shots and generates their text prompts of key shot content. Via a concise video-to-shot prompting paradigm, it allows our V-Stylist to effectively handle videos with complex transitions. (2) Style Parser identifies the style in the user query and progressively search the matched style model from a style tree. Via a robust tree-of-thought searching paradigm, it allows our V-Stylist to precisely specify vague style preference in the open user query. (3) Style Artist leverages the matched model to render all the video shots into the required style. Via a novel multi-round self-reflection paradigm, it allows our V-Stylist to adaptively adjust detail control, according to the style requirement. With such a distinct design of mimicking human professionals, our V-Stylist achieves a major breakthrough over the primary challenges for effective and automatic video stylization. Moreover,we further construct a new benchmark Text-driven Video Stylization Benchmark (TVSBench), which fills the gap to assess stylization of complex videos on open user queries. Extensive experiments show that, V-Stylist achieves the state-of-the-art, e.g.,V-Stylist surpasses FRESCO and ControlVideo by 6.05% and 4.51% respectively in overall average metrics, marking a significant advance in video stylization.
TimeStep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in Vision
Mar 10, 2025



Diffusion models have driven the advancement of vision generation over the past years. However, it is often difficult to apply these large models in downstream tasks, due to massive fine-tuning cost. Recently, Low-Rank Adaptation (LoRA) has been applied for efficient tuning of diffusion models. Unfortunately, the capabilities of LoRA-tuned diffusion models are limited, since the same LoRA is used for different timesteps of the diffusion process. To tackle this problem, we introduce a general and concise TimeStep Master (TSM) paradigm with two key fine-tuning stages. In the fostering stage (1-stage), we apply different LoRAs to fine-tune the diffusion model at different timestep intervals. This results in different TimeStep LoRA experts that can effectively capture different noise levels. In the assembling stage (2-stage), we design a novel asymmetrical mixture of TimeStep LoRA experts, via core-context collaboration of experts at multi-scale intervals. For each timestep, we leverage TimeStep LoRA expert within the smallest interval as the core expert without gating, and use experts within the bigger intervals as the context experts with time-dependent gating. Consequently, our TSM can effectively model the noise level via the expert in the finest interval, and adaptively integrate contexts from the experts of other scales, boosting the versatility of diffusion models. To show the effectiveness of our TSM paradigm, we conduct extensive experiments on three typical and popular LoRA-related tasks of diffusion models, including domain adaptation, post-pretraining, and model distillation. Our TSM achieves the state-of-the-art results on all these tasks, throughout various model structures (UNet, DiT and MM-DiT) and visual data modalities (Image, Video), showing its remarkable generalization capacity.
MUSES: 3D-Controllable Image Generation via Multi-Modal Agent Collaboration
Aug 21, 2024


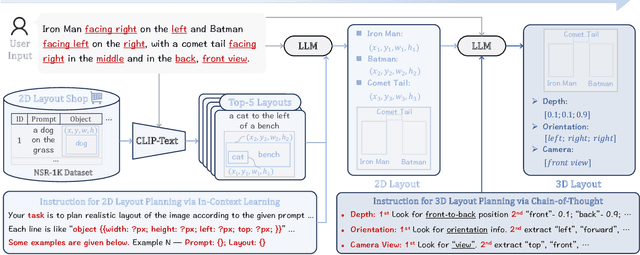
Despite recent advancements in text-to-image generation, most existing methods struggle to create images with multiple objects and complex spatial relationships in 3D world. To tackle this limitation, we introduce a generic AI system, namely MUSES, for 3D-controllable image generation from user queries. Specifically, our MUSES addresses this challenging task by developing a progressive workflow with three key components, including (1) Layout Manager for 2D-to-3D layout lifting, (2) Model Engineer for 3D object acquisition and calibration, (3) Image Artist for 3D-to-2D image rendering. By mimicking the collaboration of human professionals, this multi-modal agent pipeline facilitates the effective and automatic creation of images with 3D-controllable objects, through an explainable integration of top-down planning and bottom-up generation. Additionally, we find that existing benchmarks lack detailed descriptions of complex 3D spatial relationships of multiple objects. To fill this gap, we further construct a new benchmark of T2I-3DisBench (3D image scene), which describes diverse 3D image scenes with 50 detailed prompts. Extensive experiments show the state-of-the-art performance of MUSES on both T2I-CompBench and T2I-3DisBench, outperforming recent strong competitors such as DALL-E 3 and Stable Diffusion 3. These results demonstrate a significant step of MUSES forward in bridging natural language, 2D image generation, and 3D world.