 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Dual Bottlenecks: Evolving Unified Multimodal Models into Self-Adaptive Interleaved Visual Reasoners
May 14, 2026Recent unified models integrate multimodal understanding and generation within a single framework. However, an "understanding-generation gap" persists, where models can capture user intent but often fail to translate this semantic knowledge into precise pixel-level manipulation. This gap results in two bottlenecks in anything-to-image task (X2I): the attention entanglement bottleneck, where blind planning struggles with complex prompts, and the visual refinement bottleneck, where unstructured feedback fails to correct imperfections efficiently. In this paper, we propose a novel framework that empowers unified models to autonomously switch between generation strategies based on instruction complexity and model capability. To achieve this, we construct a hierarchical data pipeline that constructs execution paths across three adaptive modes: direct generation for simple cases, self-reflection for quality refinement, and multi-step planning for decomposing complex scenarios. Building on this pipeline, we contribute a high-quality dataset with over 50,000 samples and implement a two-stage training strategy comprising SFT and RL. Specifically, we design step-wise reasoning rewards to ensure logical consistency and intra-group complexity penalty to prevent redundant computational overhead. Extensive experiments demonstrate that our method outperforms existing baselines on X2I, achieving superior generation fidelity among simple-to-complex instructions. The code is released at https://github.com/WeChatCV/Interleaved_Visual_Reasoner.
BitLM: Unlocking Multi-Token Language Generation with Bitwise Continuous Diffusion
May 12, 2026Autoregressive language models generate text one token at a time, yet natural language is inherently structured in multi-token units, including phrases, n-grams, and collocations that carry meaning jointly. This one-token bottleneck limits both the expressiveness of the model during pre-training and its throughput at inference time. Existing remedies such as speculative decoding or diffusion-based language models either leave the underlying bottleneck intact or sacrifice the causal structure essential to language modeling. We propose BitLM, a language model that represents each token as a fixed-length binary code and employs a lightweight diffusion head to denoise multiple tokens in parallel within each block. Crucially, BitLM preserves left-to-right causal attention across blocks while making joint lexical decisions within each block, combining the reliability of autoregressive modeling with the parallelism of iterative refinement. By replacing the large-vocabulary softmax with bitwise denoising, BitLM reframes token generation as iterative commitment in a compact binary space, enabling more efficient pre-training and substantially faster inference without altering the causal foundation that makes language models effective. Our results demonstrate that the one-token-at-a-time paradigm is not a fundamental requirement but an interface choice, and that changing it can yield a stronger and faster language model. We hope BitLM points toward a promising direction for next-generation language model architectures.
UniWeTok: An Unified Binary Tokenizer with Codebook Size $\mathit{2^{128}}$ for Unified Multimodal Large Language Model
Feb 15, 2026Unified Multimodal Large Language Models (MLLMs) require a visual representation that simultaneously supports high-fidelity reconstruction, complex semantic extraction, and generative suitability. However, existing visual tokenizers typically struggle to satisfy these conflicting objectives within a single framework. In this paper, we introduce UniWeTok, a unified discrete tokenizer designed to bridge this gap using a massive binary codebook ($\mathit{2^{128}}$). For training framework, we introduce Pre-Post Distillation and a Generative-Aware Prior to enhance the semantic extraction and generative prior of the discrete tokens. In terms of model architecture, we propose a convolution-attention hybrid architecture with the SigLu activation function. SigLu activation not only bounds the encoder output and stabilizes the semantic distillation process but also effectively addresses the optimization conflict between token entropy loss and commitment loss. We further propose a three-stage training framework designed to enhance UniWeTok's adaptability cross various image resolutions and perception-sensitive scenarios, such as those involving human faces and textual content. On ImageNet, UniWeTok achieves state-of-the-art image generation performance (FID: UniWeTok 1.38 vs. REPA 1.42) while requiring a remarkably low training compute (Training Tokens: UniWeTok 33B vs. REPA 262B). On general-domain, UniWeTok demonstrates highly competitive capabilities across a broad range of tasks, including multimodal understanding, image generation (DPG Score: UniWeTok 86.63 vs. FLUX.1 [Dev] 83.84), and editing (GEdit Overall Score: UniWeTok 5.09 vs. OmniGen 5.06). We release code and models to facilitate community exploration of unified tokenizer and MLLM.
MotionWeaver: Holistic 4D-Anchored Framework for Multi-Humanoid Image Animation
Feb 11, 2026Character image animation, which synthesizes videos of reference characters driven by pose sequences, has advanced rapidly but remains largely limited to single-human settings. Existing methods struggle to generalize to multi-humanoid scenarios, which involve diverse humanoid forms, complex interactions, and frequent occlusions. We address this gap with two key innovations. First, we introduce unified motion representations that extract identity-agnostic motions and explicitly bind them to corresponding characters, enabling generalization across diverse humanoid forms and seamless extension to multi-humanoid scenarios. Second, we propose a holistic 4D-anchored paradigm that constructs a shared 4D space to fuse motion representations with video latents, and further reinforces this process with hierarchical 4D-level supervision to better handle interactions and occlusions. We instantiate these ideas in MotionWeaver, an end-to-end framework for multi-humanoid image animation. To support this setting, we curate a 46-hour dataset of multi-human videos with rich interactions, and construct a 300-video benchmark featuring paired humanoid characters. Quantitative and qualitative experiments demonstrate that MotionWeaver not only achieves state-of-the-art results on our benchmark but also generalizes effectively across diverse humanoid forms, complex interactions, and challenging multi-humanoid scenarios.
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
WeTok: Powerful Discrete Tokenization for High-Fidelity Visual Reconstruction
Aug 07, 2025Visual tokenizer is a critical component for vision generation. However, the existing tokenizers often face unsatisfactory trade-off between compression ratios and reconstruction fidelity. To fill this gap, we introduce a powerful and concise WeTok tokenizer, which surpasses the previous leading tokenizers via two core innovations. (1) Group-wise lookup-free Quantization (GQ). We partition the latent features into groups, and perform lookup-free quantization for each group. As a result, GQ can efficiently overcome memory and computation limitations of prior tokenizers, while achieving a reconstruction breakthrough with more scalable codebooks. (2) Generative Decoding (GD). Different from prior tokenizers, we introduce a generative decoder with a prior of extra noise variable. In this case, GD can probabilistically model the distribution of visual data conditioned on discrete tokens, allowing WeTok to reconstruct visual details, especially at high compression ratios. Extensive experiments on mainstream benchmarks show superior performance of our WeTok. On the ImageNet 50k validation set, WeTok achieves a record-low zero-shot rFID (WeTok: 0.12 vs. FLUX-VAE: 0.18 vs. SD-VAE 3.5: 0.19). Furthermore, our highest compression model achieves a zero-shot rFID of 3.49 with a compression ratio of 768, outperforming Cosmos (384) 4.57 which has only 50% compression rate of ours. Code and models are available: https://github.com/zhuangshaobin/WeTok.
VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos
Jun 12, 2025We present VRBench, the first long narrative video benchmark crafted for evaluating large models' multi-step reasoning capabilities, addressing limitations in existing evaluations that overlook temporal reasoning and procedural validity. It comprises 1,010 long videos (with an average duration of 1.6 hours), along with 9,468 human-labeled multi-step question-answering pairs and 30,292 reasoning steps with timestamps. These videos are curated via a multi-stage filtering process including expert inter-rater reviewing to prioritize plot coherence. We develop a human-AI collaborative framework that generates coherent reasoning chains, each requiring multiple temporally grounded steps, spanning seven types (e.g., event attribution, implicit inference). VRBench designs a multi-phase evaluation pipeline that assesses models at both the outcome and process levels. Apart from the MCQs for the final results, we propose a progress-level LLM-guided scoring metric to evaluate the quality of the reasoning chain from multiple dimensions comprehensively. Through extensive evaluations of 12 LLMs and 16 VLMs on VRBench, we undertake a thorough analysis and provide valuable insights that advance the field of multi-step reasoning.
Super Encoding Network: Recursive Association of Multi-Modal Encoders for Video Understanding
Jun 09, 2025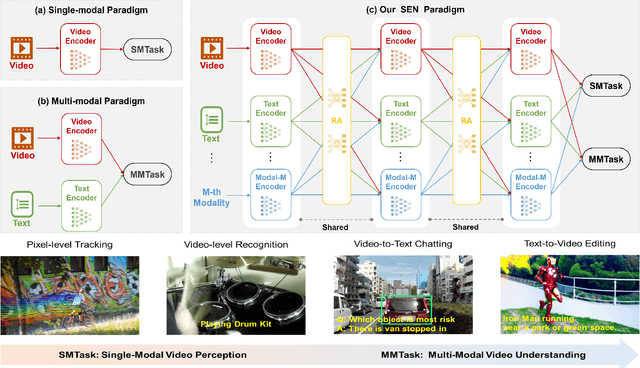
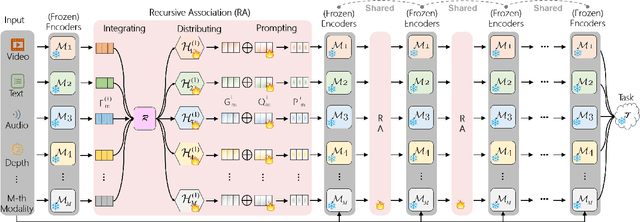
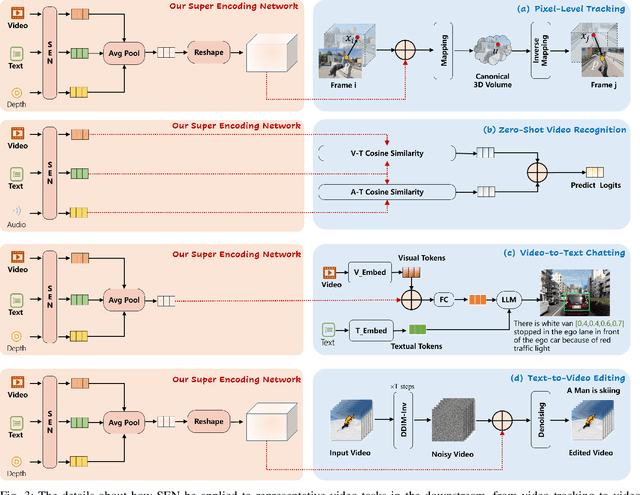

Video understanding has been considered as one critical step towards world modeling, which is an important long-term problem in AI research. Recently, multi-modal foundation models have shown such potential via large-scale pretraining. However, these models simply align encoders of different modalities via contrastive learning, while lacking deeper multi-modal interactions, which is critical for understanding complex target movements with diversified video scenes. To fill this gap, we propose a unified Super Encoding Network (SEN) for video understanding, which builds up such distinct interactions through recursive association of multi-modal encoders in the foundation models. Specifically, we creatively treat those well-trained encoders as "super neurons" in our SEN. Via designing a Recursive Association (RA) block, we progressively fuse multi-modalities with the input video, based on knowledge integrating, distributing, and prompting of super neurons in a recursive manner. In this way, our SEN can effectively encode deeper multi-modal interactions, for prompting various video understanding tasks in downstream. Extensive experiments show that, our SEN can remarkably boost the four most representative video tasks, including tracking, recognition, chatting, and editing, e.g., for pixel-level tracking, the average jaccard index improves 2.7%, temporal coherence(TC) drops 8.8% compared to the popular CaDeX++ approach. For one-shot video editing, textual alignment improves 6.4%, and frame consistency increases 4.1% compared to the popular TuneA-Video approach.
VideoChat-A1: Thinking with Long Videos by Chain-of-Shot Reasoning
Jun 06, 2025The recent advance in video understanding has been driven by multimodal large language models (MLLMs). But these MLLMs are good at analyzing short videos, while suffering from difficulties in understanding videos with a longer context. To address this difficulty, several agent paradigms have recently been proposed, using MLLMs as agents for retrieving extra contextual knowledge in a long video. However, most existing agents ignore the key fact that a long video is composed with multiple shots, i.e., to answer the user question from a long video, it is critical to deeply understand its relevant shots like human. Without such insight, these agents often mistakenly find redundant even noisy temporal context, restricting their capacity for long video understanding. To fill this gap, we propose VideoChat-A1, a novel long video agent paradigm. Different from the previous works, our VideoChat-A1 can deeply think with long videos, via a distinct chain-of-shot reasoning paradigm. More specifically, it can progressively select the relevant shots of user question, and look into these shots in a coarse-to-fine partition. By multi-modal reasoning along the shot chain, VideoChat-A1 can effectively mimic step-by-step human thinking process, allowing to interactively discover preferable temporal context for thoughtful understanding in long videos. Extensive experiments show that, our VideoChat-A1 achieves the state-of-the-art performance on the mainstream long video QA benchmarks, e.g., it achieves 77.0 on VideoMME and 70.1 on EgoSchema, outperforming its strong baselines (e.g., Intern2.5VL-8B and InternVideo2.5-8B), by up to 10.8\% and 6.2\%. Compared to leading close-source GPT-4o and Gemini 1.5 Pro, VideoChat-A1 offers competitive accuracy, but with 7\% input frames and 12\% inference time on average.
Video-GPT via Next Clip Diffusion
May 18, 2025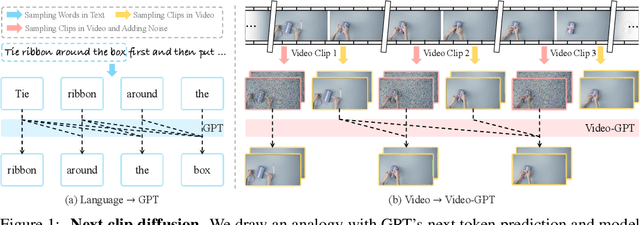
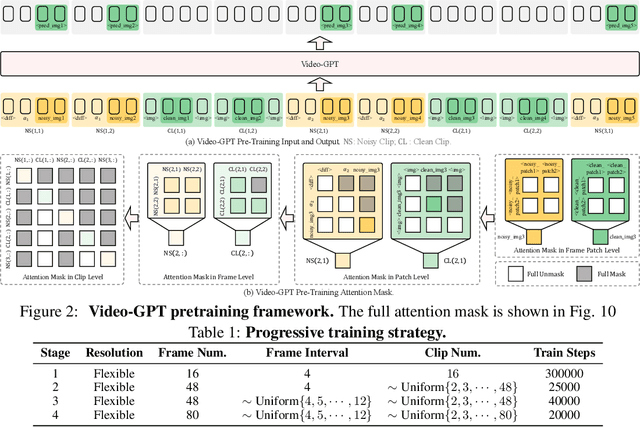
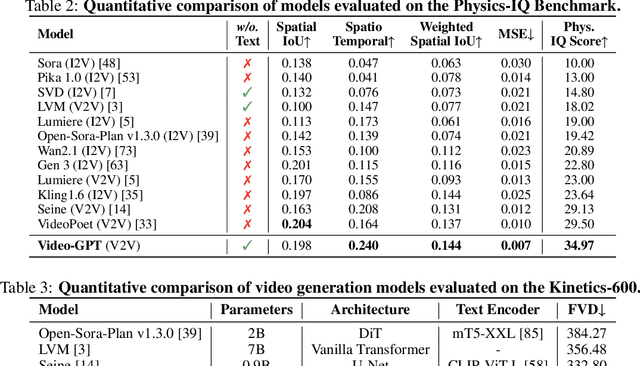
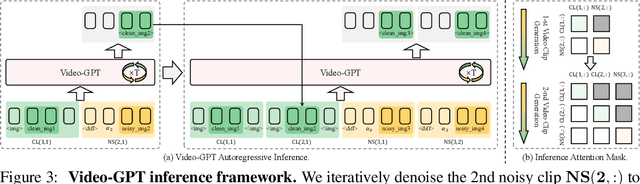
GPT has shown its remarkable success in natural language processing. However, the language sequence is not sufficient to describe spatial-temporal details in the visual world. Alternatively, the video sequence is good at capturing such details. Motivated by this fact, we propose a concise Video-GPT in this paper by treating video as new language for visual world modeling. By analogy to next token prediction in GPT, we introduce a novel next clip diffusion paradigm for pretraining Video-GPT. Different from the previous works, this distinct paradigm allows Video-GPT to tackle both short-term generation and long-term prediction, by autoregressively denoising the noisy clip according to the clean clips in the history. Extensive experiments show our Video-GPT achieves the state-of-the-art performance on video prediction, which is the key factor towards world modeling (Physics-IQ Benchmark: Video-GPT 34.97 vs. Kling 23.64 vs. Wan 20.89). Moreover, it can be well adapted on 6 mainstream video tasks in both video generation and understanding, showing its great generalization capacity in downstream. The project page is at https://Video-GPT.github.io.