 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Cross-Layer Information Routing in Diffusion Transformers
May 20, 2026Diffusion Transformers (DiTs) have become a de facto backbone of modern visual generation, and nearly every major axis of their design -- tokenization, attention, conditioning, objectives, and latent autoencoders -- has been extensively revisited. The residual stream that governs how information accumulates across layers, however, has been directly inherited from the original Transformer. In this paper, we present a systematic empirical analysis of cross-layer information flow in DiTs, jointly along depth and denoising timestep, and identify three concrete symptoms of traditional residual addition, namely monotonic forward magnitude inflation, sharp backward gradient decay, and pronounced block-wise redundancy. Motivated by this diagnosis, we propose Diffusion-Adaptive Routing (\textsc{DAR}), a drop-in residual replacement that performs \emph{learnable, timestep-adaptive, and non-incremental} aggregation over the history of sublayer outputs. Moreover, the proposed \textsc{DAR} is compatible with many modern Transformer enhancement methods, such as REPA. On ImageNet $256\times256$, \textsc{DAR} improves SiT-XL/2 by $2.11$ FID ($7.56$ vs.\ $9.67$) and matches the baseline's converged quality with $8.75\times$ fewer training iterations. Stacked on top of REPA, it yields a $2\times$ training acceleration in the early stage, suggesting cross-layer information routing as an underexplored design axis in diffusion modeling, one that operates orthogonally to existing representation-alignment objectives. Beyond pretraining, \textsc{DAR} can also be applied during the fine-tuning stage of large-scale T2I models and preserves high-frequency details during Distribution Matching Distillation.
InpaintDPO: Mitigating Spatial Relationship Hallucinations in Foreground-conditioned Inpainting via Diverse Preference Optimization
Dec 16, 2025



Foreground-conditioned inpainting, which aims at generating a harmonious background for a given foreground subject based on the text prompt, is an important subfield in controllable image generation. A common challenge in current methods, however, is the occurrence of Spatial Relationship Hallucinations between the foreground subject and the generated background, including inappropriate scale, positional relationships, and viewpoints. Critically, the subjective nature of spatial rationality makes it challenging to quantify, hindering the use of traditional reward-based RLHF methods. To address this issue, we propose InpaintDPO, the first Direct Preference Optimization (DPO) based framework dedicated to spatial rationality in foreground-conditioned inpainting, ensuring plausible spatial relationships between foreground and background elements. To resolve the gradient conflicts in standard DPO caused by identical foreground in win-lose pairs, we propose MaskDPO, which confines preference optimization exclusively to the background to enhance background spatial relationships, while retaining the inpainting loss in the foreground region for robust foreground preservation. To enhance coherence at the foreground-background boundary, we propose Conditional Asymmetric Preference Optimization, which samples pairs with differentiated cropping operations and applies global preference optimization to promote contextual awareness and enhance boundary coherence. Finally, based on the observation that winning samples share a commonality in plausible spatial relationships, we propose Shared Commonality Preference Optimization to enhance the model's understanding of spatial commonality across high-quality winning samples, further promoting shared spatial rationality.
VRBench: A Benchmark for Multi-Step Reasoning in Long Narrative Videos
Jun 12, 2025We present VRBench, the first long narrative video benchmark crafted for evaluating large models' multi-step reasoning capabilities, addressing limitations in existing evaluations that overlook temporal reasoning and procedural validity. It comprises 1,010 long videos (with an average duration of 1.6 hours), along with 9,468 human-labeled multi-step question-answering pairs and 30,292 reasoning steps with timestamps. These videos are curated via a multi-stage filtering process including expert inter-rater reviewing to prioritize plot coherence. We develop a human-AI collaborative framework that generates coherent reasoning chains, each requiring multiple temporally grounded steps, spanning seven types (e.g., event attribution, implicit inference). VRBench designs a multi-phase evaluation pipeline that assesses models at both the outcome and process levels. Apart from the MCQs for the final results, we propose a progress-level LLM-guided scoring metric to evaluate the quality of the reasoning chain from multiple dimensions comprehensively. Through extensive evaluations of 12 LLMs and 16 VLMs on VRBench, we undertake a thorough analysis and provide valuable insights that advance the field of multi-step reasoning.
On Learning Multi-Modal Forgery Representation for Diffusion Generated Video Detection
Oct 31, 2024Large numbers of synthesized videos from diffusion models pose threats to information security and authenticity, leading to an increasing demand for generated content detection. However, existing video-level detection algorithms primarily focus on detecting facial forgeries and often fail to identify diffusion-generated content with a diverse range of semantics. To advance the field of video forensics, we propose an innovative algorithm named Multi-Modal Detection(MM-Det) for detecting diffusion-generated videos. MM-Det utilizes the profound perceptual and comprehensive abilities of Large Multi-modal Models (LMMs) by generating a Multi-Modal Forgery Representation (MMFR) from LMM's multi-modal space, enhancing its ability to detect unseen forgery content. Besides, MM-Det leverages an In-and-Across Frame Attention (IAFA) mechanism for feature augmentation in the spatio-temporal domain. A dynamic fusion strategy helps refine forgery representations for the fusion. Moreover, we construct a comprehensive diffusion video dataset, called Diffusion Video Forensics (DVF), across a wide range of forgery videos. MM-Det achieves state-of-the-art performance in DVF, demonstrating the effectiveness of our algorithm. Both source code and DVF are available at https://github.com/SparkleXFantasy/MM-Det.
MetaScript: Few-Shot Handwritten Chinese Content Generation via Generative Adversarial Networks
Dec 25, 2023In this work, we propose MetaScript, a novel Chinese content generation system designed to address the diminishing presence of personal handwriting styles in the digital representation of Chinese characters. Our approach harnesses the power of few-shot learning to generate Chinese characters that not only retain the individual's unique handwriting style but also maintain the efficiency of digital typing. Trained on a diverse dataset of handwritten styles, MetaScript is adept at producing high-quality stylistic imitations from minimal style references and standard fonts. Our work demonstrates a practical solution to the challenges of digital typography in preserving the personal touch in written communication, particularly in the context of Chinese script. Notably, our system has demonstrated superior performance in various evaluations, including recognition accuracy, inception score, and Frechet inception distance. At the same time, the training conditions of our model are easy to meet and facilitate generalization to real applications.
Learning Graph Embedding with Limited Labeled Data: An Efficient Sampling Approach
Mar 13, 2020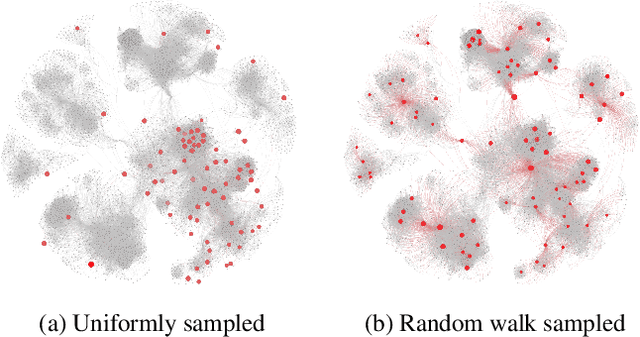
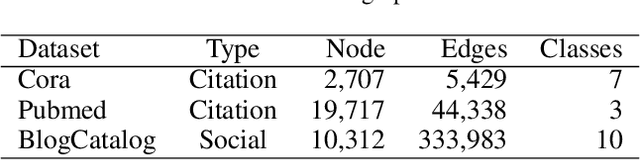
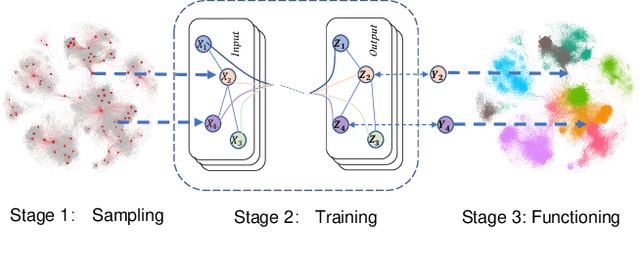
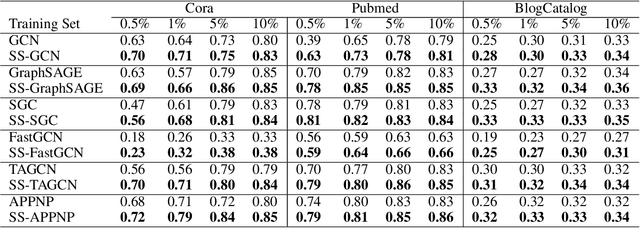
Semi-supervised graph embedding methods represented by graph convolutional network has become one of the most popular methods for utilizing deep learning approaches to process the graph-based data for applications. Mostly existing work focus on designing novel algorithm structure to improve the performance, but ignore one common training problem, i.e., could these methods achieve the same performance with limited labelled data? To tackle this research gap, we propose a sampling-based training framework for semi-supervised graph embedding methods to achieve better performance with smaller training data set. The key idea is to integrate the sampling theory and embedding methods by a pipeline form, which has the following advantages: 1) the sampled training data can maintain more accurate graph characteristics than uniformly chosen data, which eliminates the model deviation; 2) the smaller scale of training data is beneficial to reduce the human resource cost to label them; The extensive experiments show that the sampling-based method can achieve the same performance only with 10$\%$-50$\%$ of the scale of training data. It verifies that the framework could extend the existing semi-supervised methods to the scenarios with the extremely small scale of labelled data.