 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
VIKI-R: Coordinating Embodied Multi-Agent Cooperation via Reinforcement Learning
Jun 10, 2025Coordinating multiple embodied agents in dynamic environments remains a core challenge in artificial intelligence, requiring both perception-driven reasoning and scalable cooperation strategies. While recent works have leveraged large language models (LLMs) for multi-agent planning, a few have begun to explore vision-language models (VLMs) for visual reasoning. However, these VLM-based approaches remain limited in their support for diverse embodiment types. In this work, we introduce VIKI-Bench, the first hierarchical benchmark tailored for embodied multi-agent cooperation, featuring three structured levels: agent activation, task planning, and trajectory perception. VIKI-Bench includes diverse robot embodiments, multi-view visual observations, and structured supervision signals to evaluate reasoning grounded in visual inputs. To demonstrate the utility of VIKI-Bench, we propose VIKI-R, a two-stage framework that fine-tunes a pretrained vision-language model (VLM) using Chain-of-Thought annotated demonstrations, followed by reinforcement learning under multi-level reward signals. Our extensive experiments show that VIKI-R significantly outperforms baselines method across all task levels. Furthermore, we show that reinforcement learning enables the emergence of compositional cooperation patterns among heterogeneous agents. Together, VIKI-Bench and VIKI-R offer a unified testbed and method for advancing multi-agent, visual-driven cooperation in embodied AI systems.
UniSTD: Towards Unified Spatio-Temporal Learning across Diverse Disciplines
Mar 26, 2025

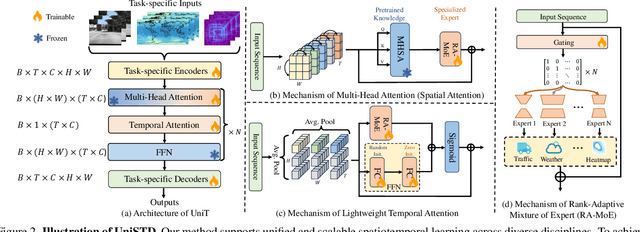

Traditional spatiotemporal models generally rely on task-specific architectures, which limit their generalizability and scalability across diverse tasks due to domain-specific design requirements. In this paper, we introduce \textbf{UniSTD}, a unified Transformer-based framework for spatiotemporal modeling, which is inspired by advances in recent foundation models with the two-stage pretraining-then-adaption paradigm. Specifically, our work demonstrates that task-agnostic pretraining on 2D vision and vision-text datasets can build a generalizable model foundation for spatiotemporal learning, followed by specialized joint training on spatiotemporal datasets to enhance task-specific adaptability. To improve the learning capabilities across domains, our framework employs a rank-adaptive mixture-of-expert adaptation by using fractional interpolation to relax the discrete variables so that can be optimized in the continuous space. Additionally, we introduce a temporal module to incorporate temporal dynamics explicitly. We evaluate our approach on a large-scale dataset covering 10 tasks across 4 disciplines, demonstrating that a unified spatiotemporal model can achieve scalable, cross-task learning and support up to 10 tasks simultaneously within one model while reducing training costs in multi-domain applications. Code will be available at https://github.com/1hunters/UniSTD.
Rethinking Vision-Language Model in Face Forensics: Multi-Modal Interpretable Forged Face Detector
Mar 26, 2025Deepfake detection is a long-established research topic vital for mitigating the spread of malicious misinformation. Unlike prior methods that provide either binary classification results or textual explanations separately, we introduce a novel method capable of generating both simultaneously. Our method harnesses the multi-modal learning capability of the pre-trained CLIP and the unprecedented interpretability of large language models (LLMs) to enhance both the generalization and explainability of deepfake detection. Specifically, we introduce a multi-modal face forgery detector (M2F2-Det) that employs tailored face forgery prompt learning, incorporating the pre-trained CLIP to improve generalization to unseen forgeries. Also, M2F2-Det incorporates an LLM to provide detailed textual explanations of its detection decisions, enhancing interpretability by bridging the gap between natural language and subtle cues of facial forgeries. Empirically, we evaluate M2F2-Det on both detection and explanation generation tasks, where it achieves state-of-the-art performance, demonstrating its effectiveness in identifying and explaining diverse forgeries.
RoboFactory: Exploring Embodied Agent Collaboration with Compositional Constraints
Mar 20, 2025Designing effective embodied multi-agent systems is critical for solving complex real-world tasks across domains. Due to the complexity of multi-agent embodied systems, existing methods fail to automatically generate safe and efficient training data for such systems. To this end, we propose the concept of compositional constraints for embodied multi-agent systems, addressing the challenges arising from collaboration among embodied agents. We design various interfaces tailored to different types of constraints, enabling seamless interaction with the physical world. Leveraging compositional constraints and specifically designed interfaces, we develop an automated data collection framework for embodied multi-agent systems and introduce the first benchmark for embodied multi-agent manipulation, RoboFactory. Based on RoboFactory benchmark, we adapt and evaluate the method of imitation learning and analyzed its performance in different difficulty agent tasks. Furthermore, we explore the architectures and training strategies for multi-agent imitation learning, aiming to build safe and efficient embodied multi-agent systems.
On Learning Multi-Modal Forgery Representation for Diffusion Generated Video Detection
Oct 31, 2024Large numbers of synthesized videos from diffusion models pose threats to information security and authenticity, leading to an increasing demand for generated content detection. However, existing video-level detection algorithms primarily focus on detecting facial forgeries and often fail to identify diffusion-generated content with a diverse range of semantics. To advance the field of video forensics, we propose an innovative algorithm named Multi-Modal Detection(MM-Det) for detecting diffusion-generated videos. MM-Det utilizes the profound perceptual and comprehensive abilities of Large Multi-modal Models (LMMs) by generating a Multi-Modal Forgery Representation (MMFR) from LMM's multi-modal space, enhancing its ability to detect unseen forgery content. Besides, MM-Det leverages an In-and-Across Frame Attention (IAFA) mechanism for feature augmentation in the spatio-temporal domain. A dynamic fusion strategy helps refine forgery representations for the fusion. Moreover, we construct a comprehensive diffusion video dataset, called Diffusion Video Forensics (DVF), across a wide range of forgery videos. MM-Det achieves state-of-the-art performance in DVF, demonstrating the effectiveness of our algorithm. Both source code and DVF are available at https://github.com/SparkleXFantasy/MM-Det.