 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciIF: Benchmarking Scientific Instruction Following Towards Rigorous Scientific Intelligence
Jan 08, 2026As large language models (LLMs) transition from general knowledge retrieval to complex scientific discovery, their evaluation standards must also incorporate the rigorous norms of scientific inquiry. Existing benchmarks exhibit a critical blind spot: general instruction-following metrics focus on superficial formatting, while domain-specific scientific benchmarks assess only final-answer correctness, often rewarding models that arrive at the right result with the wrong reasons. To address this gap, we introduce scientific instruction following: the capability to solve problems while strictly adhering to the constraints that establish scientific validity. Specifically, we introduce SciIF, a multi-discipline benchmark that evaluates this capability by pairing university-level problems with a fixed catalog of constraints across three pillars: scientific conditions (e.g., boundary checks and assumptions), semantic stability (e.g., unit and symbol conventions), and specific processes(e.g., required numerical methods). Uniquely, SciIF emphasizes auditability, requiring models to provide explicit evidence of constraint satisfaction rather than implicit compliance. By measuring both solution correctness and multi-constraint adherence, SciIF enables finegrained diagnosis of compositional reasoning failures, ensuring that LLMs can function as reliable agents within the strict logical frameworks of science.
SciEvalKit: An Open-source Evaluation Toolkit for Scientific General Intelligence
Dec 30, 2025We introduce SciEvalKit, a unified benchmarking toolkit designed to evaluate AI models for science across a broad range of scientific disciplines and task capabilities. Unlike general-purpose evaluation platforms, SciEvalKit focuses on the core competencies of scientific intelligence, including Scientific Multimodal Perception, Scientific Multimodal Reasoning, Scientific Multimodal Understanding, Scientific Symbolic Reasoning, Scientific Code Generation, Science Hypothesis Generation and Scientific Knowledge Understanding. It supports six major scientific domains, spanning from physics and chemistry to astronomy and materials science. SciEvalKit builds a foundation of expert-grade scientific benchmarks, curated from real-world, domain-specific datasets, ensuring that tasks reflect authentic scientific challenges. The toolkit features a flexible, extensible evaluation pipeline that enables batch evaluation across models and datasets, supports custom model and dataset integration, and provides transparent, reproducible, and comparable results. By bridging capability-based evaluation and disciplinary diversity, SciEvalKit offers a standardized yet customizable infrastructure to benchmark the next generation of scientific foundation models and intelligent agents. The toolkit is open-sourced and actively maintained to foster community-driven development and progress in AI4Science.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Human-Imperceptible Physical Adversarial Attack for NIR Face Recognition Models
Apr 22, 2025Near-infrared (NIR) face recognition systems, which can operate effectively in low-light conditions or in the presence of makeup, exhibit vulnerabilities when subjected to physical adversarial attacks. To further demonstrate the potential risks in real-world applications, we design a novel, stealthy, and practical adversarial patch to attack NIR face recognition systems in a black-box setting. We achieved this by utilizing human-imperceptible infrared-absorbing ink to generate multiple patches with digitally optimized shapes and positions for infrared images. To address the optimization mismatch between digital and real-world NIR imaging, we develop a light reflection model for human skin to minimize pixel-level discrepancies by simulating NIR light reflection. Compared to state-of-the-art (SOTA) physical attacks on NIR face recognition systems, the experimental results show that our method improves the attack success rate in both digital and physical domains, particularly maintaining effectiveness across various face postures. Notably, the proposed approach outperforms SOTA methods, achieving an average attack success rate of 82.46% in the physical domain across different models, compared to 64.18% for existing methods. The artifact is available at https://anonymous.4open.science/r/Human-imperceptible-adversarial-patch-0703/.
BiSeg-SAM: Weakly-Supervised Post-Processing Framework for Boosting Binary Segmentation in Segment Anything Models
Apr 02, 2025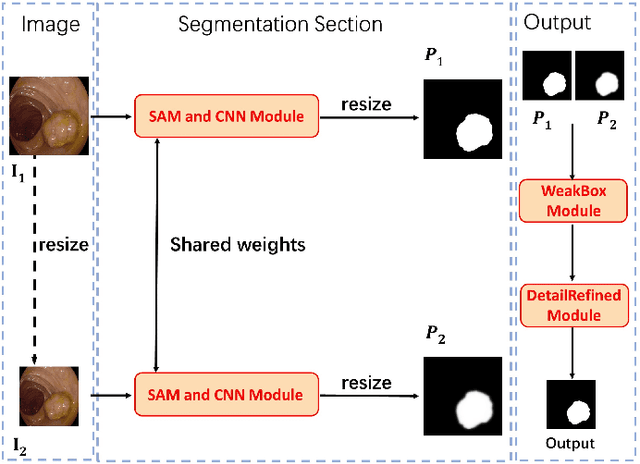
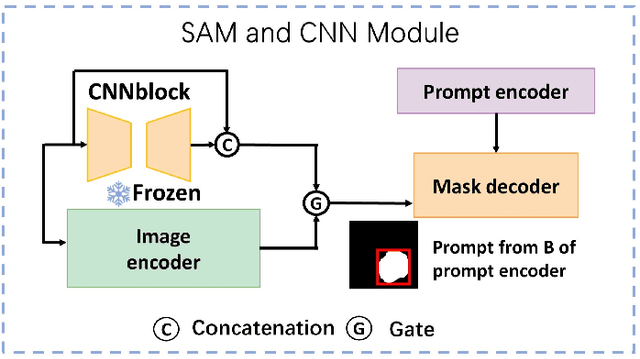
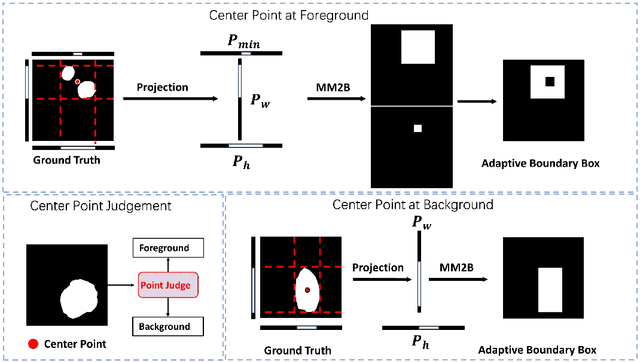
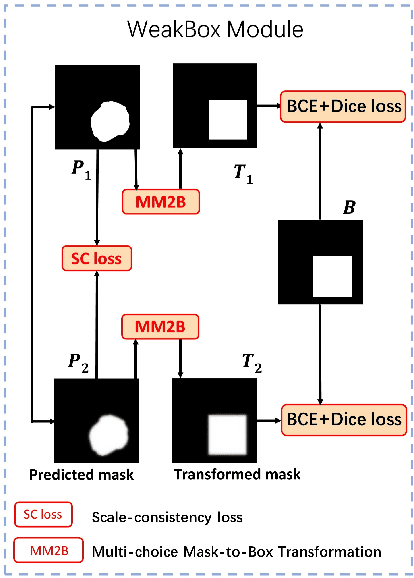
Accurate segmentation of polyps and skin lesions is essential for diagnosing colorectal and skin cancers. While various segmentation methods for polyps and skin lesions using fully supervised deep learning techniques have been developed, the pixel-level annotation of medical images by doctors is both time-consuming and costly. Foundational vision models like the Segment Anything Model (SAM) have demonstrated superior performance; however, directly applying SAM to medical segmentation may not yield satisfactory results due to the lack of domain-specific medical knowledge. In this paper, we propose BiSeg-SAM, a SAM-guided weakly supervised prompting and boundary refinement network for the segmentation of polyps and skin lesions. Specifically, we fine-tune SAM combined with a CNN module to learn local features. We introduce a WeakBox with two functions: automatically generating box prompts for the SAM model and using our proposed Multi-choice Mask-to-Box (MM2B) transformation for rough mask-to-box conversion, addressing the mismatch between coarse labels and precise predictions. Additionally, we apply scale consistency (SC) loss for prediction scale alignment. Our DetailRefine module enhances boundary precision and segmentation accuracy by refining coarse predictions using a limited amount of ground truth labels. This comprehensive approach enables BiSeg-SAM to achieve excellent multi-task segmentation performance. Our method demonstrates significant superiority over state-of-the-art (SOTA) methods when tested on five polyp datasets and one skin cancer dataset.
UniSTD: Towards Unified Spatio-Temporal Learning across Diverse Disciplines
Mar 26, 2025

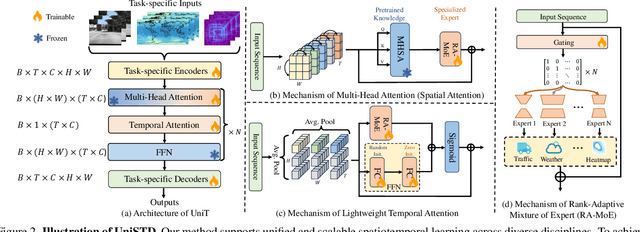

Traditional spatiotemporal models generally rely on task-specific architectures, which limit their generalizability and scalability across diverse tasks due to domain-specific design requirements. In this paper, we introduce \textbf{UniSTD}, a unified Transformer-based framework for spatiotemporal modeling, which is inspired by advances in recent foundation models with the two-stage pretraining-then-adaption paradigm. Specifically, our work demonstrates that task-agnostic pretraining on 2D vision and vision-text datasets can build a generalizable model foundation for spatiotemporal learning, followed by specialized joint training on spatiotemporal datasets to enhance task-specific adaptability. To improve the learning capabilities across domains, our framework employs a rank-adaptive mixture-of-expert adaptation by using fractional interpolation to relax the discrete variables so that can be optimized in the continuous space. Additionally, we introduce a temporal module to incorporate temporal dynamics explicitly. We evaluate our approach on a large-scale dataset covering 10 tasks across 4 disciplines, demonstrating that a unified spatiotemporal model can achieve scalable, cross-task learning and support up to 10 tasks simultaneously within one model while reducing training costs in multi-domain applications. Code will be available at https://github.com/1hunters/UniSTD.