 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrime and Reach: Synthesising Body Motion for Gaze-Primed Object Reach
Dec 18, 2025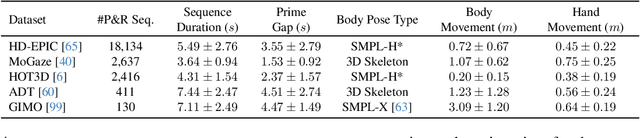



Human motion generation is a challenging task that aims to create realistic motion imitating natural human behaviour. We focus on the well-studied behaviour of priming an object/location for pick up or put down -- that is, the spotting of an object/location from a distance, known as gaze priming, followed by the motion of approaching and reaching the target location. To that end, we curate, for the first time, 23.7K gaze-primed human motion sequences for reaching target object locations from five publicly available datasets, i.e., HD-EPIC, MoGaze, HOT3D, ADT, and GIMO. We pre-train a text-conditioned diffusion-based motion generation model, then fine-tune it conditioned on goal pose or location, on our curated sequences. Importantly, we evaluate the ability of the generated motion to imitate natural human movement through several metrics, including the 'Reach Success' and a newly introduced 'Prime Success' metric. On the largest dataset, HD-EPIC, our model achieves 60% prime success and 89% reach success when conditioned on the goal object location.
UniSTD: Towards Unified Spatio-Temporal Learning across Diverse Disciplines
Mar 26, 2025

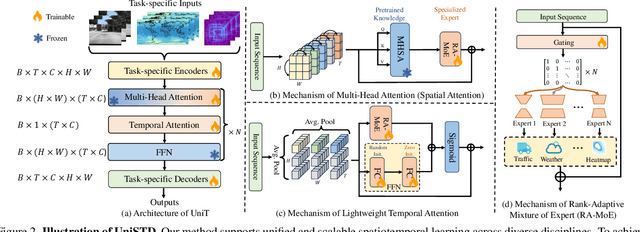

Traditional spatiotemporal models generally rely on task-specific architectures, which limit their generalizability and scalability across diverse tasks due to domain-specific design requirements. In this paper, we introduce \textbf{UniSTD}, a unified Transformer-based framework for spatiotemporal modeling, which is inspired by advances in recent foundation models with the two-stage pretraining-then-adaption paradigm. Specifically, our work demonstrates that task-agnostic pretraining on 2D vision and vision-text datasets can build a generalizable model foundation for spatiotemporal learning, followed by specialized joint training on spatiotemporal datasets to enhance task-specific adaptability. To improve the learning capabilities across domains, our framework employs a rank-adaptive mixture-of-expert adaptation by using fractional interpolation to relax the discrete variables so that can be optimized in the continuous space. Additionally, we introduce a temporal module to incorporate temporal dynamics explicitly. We evaluate our approach on a large-scale dataset covering 10 tasks across 4 disciplines, demonstrating that a unified spatiotemporal model can achieve scalable, cross-task learning and support up to 10 tasks simultaneously within one model while reducing training costs in multi-domain applications. Code will be available at https://github.com/1hunters/UniSTD.
Multi-task Learning with 3D-Aware Regularization
Oct 02, 2023

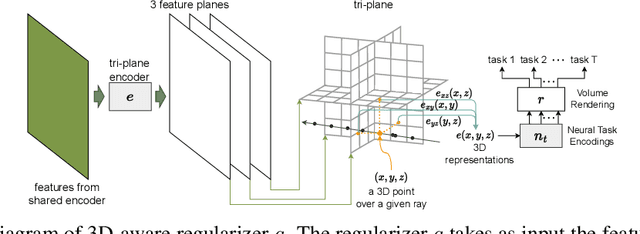
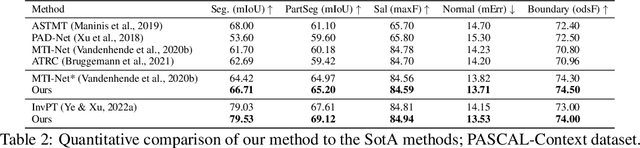
Deep neural networks have become a standard building block for designing models that can perform multiple dense computer vision tasks such as depth estimation and semantic segmentation thanks to their ability to capture complex correlations in high dimensional feature space across tasks. However, the cross-task correlations that are learned in the unstructured feature space can be extremely noisy and susceptible to overfitting, consequently hurting performance. We propose to address this problem by introducing a structured 3D-aware regularizer which interfaces multiple tasks through the projection of features extracted from an image encoder to a shared 3D feature space and decodes them into their task output space through differentiable rendering. We show that the proposed method is architecture agnostic and can be plugged into various prior multi-task backbones to improve their performance; as we evidence using standard benchmarks NYUv2 and PASCAL-Context.
Universal Representations: A Unified Look at Multiple Task and Domain Learning
Apr 06, 2022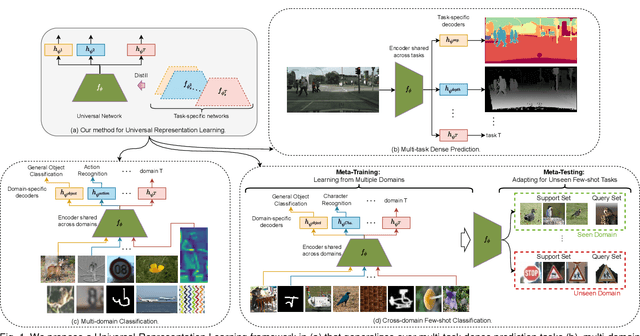



We propose a unified look at jointly learning multiple vision tasks and visual domains through universal representations, a single deep neural network. Learning multiple problems simultaneously involves minimizing a weighted sum of multiple loss functions with different magnitudes and characteristics and thus results in unbalanced state of one loss dominating the optimization and poor results compared to learning a separate model for each problem. To this end, we propose distilling knowledge of multiple task/domain-specific networks into a single deep neural network after aligning its representations with the task/domain-specific ones through small capacity adapters. We rigorously show that universal representations achieve state-of-the-art performances in learning of multiple dense prediction problems in NYU-v2 and Cityscapes, multiple image classification problems from diverse domains in Visual Decathlon Dataset and cross-domain few-shot learning in MetaDataset. Finally we also conduct multiple analysis through ablation and qualitative studies.
Learning Multiple Dense Prediction Tasks from Partially Annotated Data
Nov 29, 2021



Despite the recent advances in multi-task learning of dense prediction problems, most methods rely on expensive labelled datasets. In this paper, we present a label efficient approach and look at jointly learning of multiple dense prediction tasks on partially annotated data, which we call multi-task partially-supervised learning. We propose a multi-task training procedure that successfully leverages task relations to supervise its multi-task learning when data is partially annotated. In particular, we learn to map each task pair to a joint pairwise task-space which enables sharing information between them in a computationally efficient way through another network conditioned on task pairs, and avoids learning trivial cross-task relations by retaining high-level information about the input image. We rigorously demonstrate that our proposed method effectively exploits the images with unlabelled tasks and outperforms existing semi-supervised learning approaches and related methods on three standard benchmarks.
Improving Task Adaptation for Cross-domain Few-shot Learning
Jul 01, 2021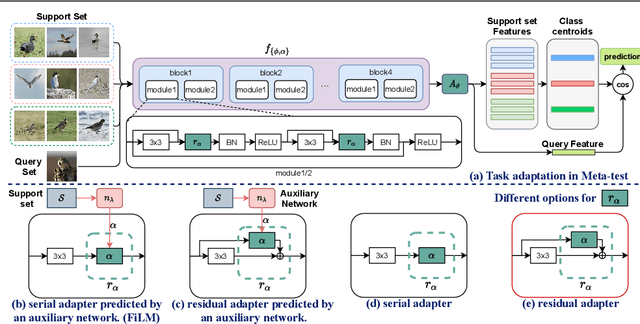



In this paper, we look at the problem of cross-domain few-shot classification that aims to learn a classifier from previously unseen classes and domains with few labeled samples. We study several strategies including various adapter topologies and operations in terms of their performance and efficiency that can be easily attached to existing methods with different meta-training strategies and adapt them for a given task during meta-test phase. We show that parametric adapters attached to convolutional layers with residual connections performs the best, and significantly improves the performance of the state-of-the-art models in the Meta-Dataset benchmark with minor additional cost. Our code will be available at https://github.com/VICO-UoE/URL.
Universal Representation Learning from Multiple Domains for Few-shot Classification
Mar 25, 2021
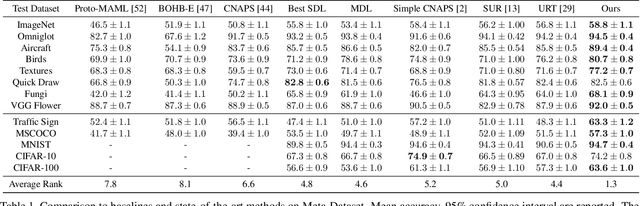

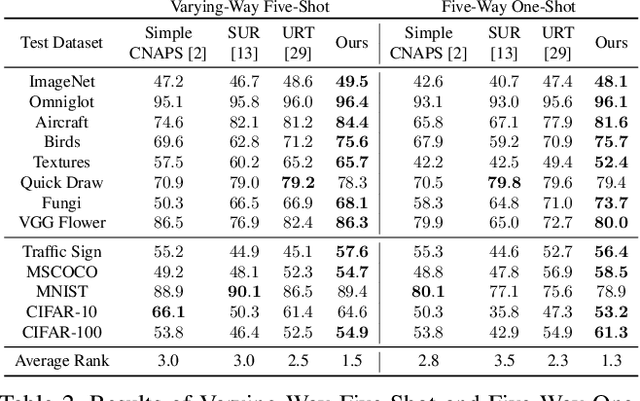
In this paper, we look at the problem of few-shot classification that aims to learn a classifier for previously unseen classes and domains from few labeled samples. Recent methods use adaptation networks for aligning their features to new domains or select the relevant features from multiple domain-specific feature extractors. In this work, we propose to learn a single set of universal deep representations by distilling knowledge of multiple separately trained networks after co-aligning their features with the help of adapters and centered kernel alignment. We show that the universal representations can be further refined for previously unseen domains by an efficient adaptation step in a similar spirit to distance learning methods. We rigorously evaluate our model in the recent Meta-Dataset benchmark and demonstrate that it significantly outperforms the previous methods while being more efficient. Our code will be available at https://github.com/VICO-UoE/URL.
MINI-Net: Multiple Instance Ranking Network for Video Highlight Detection
Aug 13, 2020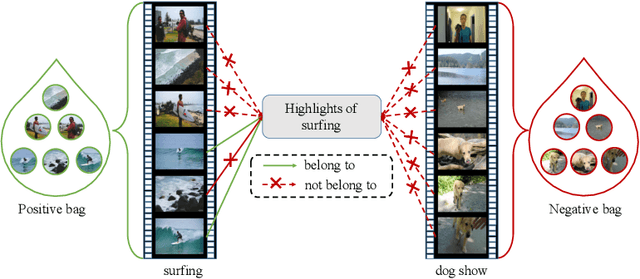

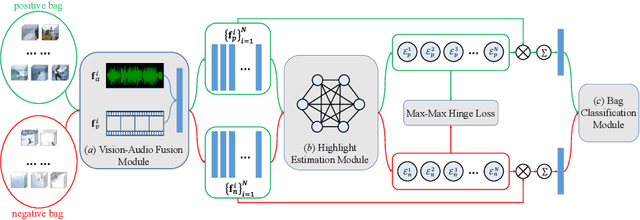

We address the weakly supervised video highlight detection problem for learning to detect segments that are more attractive in training videos given their video event label but without expensive supervision of manually annotating highlight segments. While manually averting localizing highlight segments, weakly supervised modeling is challenging, as a video in our daily life could contain highlight segments with multiple event types, e.g., skiing and surfing. In this work, we propose casting weakly supervised video highlight detection modeling for a given specific event as a multiple instance ranking network (MINI-Net) learning. We consider each video as a bag of segments, and therefore, the proposed MINI-Net learns to enforce a higher highlight score for a positive bag that contains highlight segments of a specific event than those for negative bags that are irrelevant. In particular, we form a max-max ranking loss to acquire a reliable relative comparison between the most likely positive segment instance and the hardest negative segment instance. With this max-max ranking loss, our MINI-Net effectively leverages all segment information to acquire a more distinct video feature representation for localizing the highlight segments of a specific event in a video. The extensive experimental results on three challenging public benchmarks clearly validate the efficacy of our multiple instance ranking approach for solving the problem.
Knowledge Distillation for Multi-task Learning
Jul 14, 2020
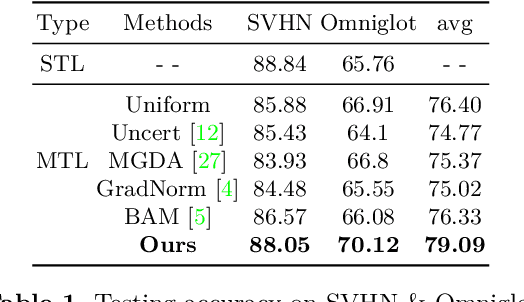

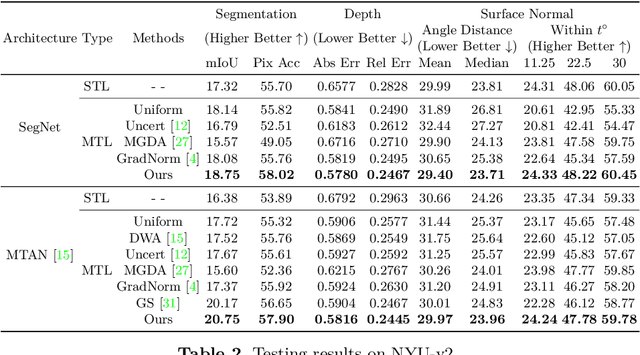
Multi-task learning (MTL) is to learn one single model that performs multiple tasks for achieving good performance on all tasks and lower cost on computation. Learning such a model requires to jointly optimize losses of a set of tasks with different difficulty levels, magnitudes, and characteristics (e.g. cross-entropy, Euclidean loss), leading to the imbalance problem in multi-task learning. To address the imbalance problem, we propose a knowledge distillation based method in this work. We first learn a task-specific model for each task. We then learn the multi-task model for minimizing task-specific loss and for producing the same feature with task-specific models. As the task-specific network encodes different features, we introduce small task-specific adaptors to project multi-task features to the task-specific features. In this way, the adaptors align the task-specific feature and the multi-task feature, which enables a balanced parameter sharing across tasks. Extensive experimental results demonstrate that our method can optimize a multi-task learning model in a more balanced way and achieve better overall performance.
Learning to Detect Important People in Unlabelled Images for Semi-supervised Important People Detection
Apr 16, 2020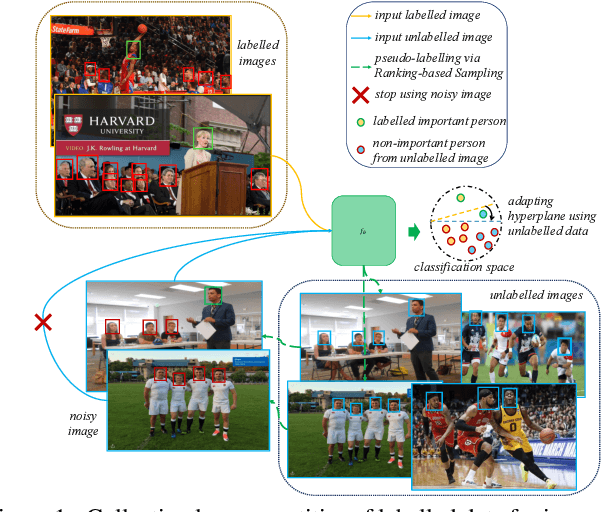
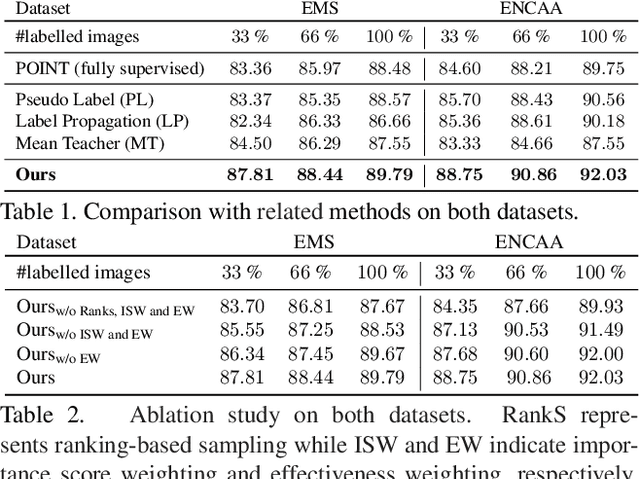

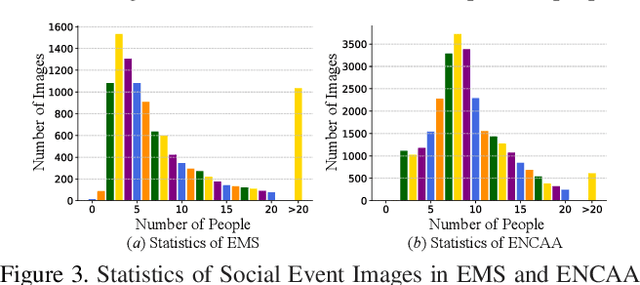
Important people detection is to automatically detect the individuals who play the most important roles in a social event image, which requires the designed model to understand a high-level pattern. However, existing methods rely heavily on supervised learning using large quantities of annotated image samples, which are more costly to collect for important people detection than for individual entity recognition (eg, object recognition). To overcome this problem, we propose learning important people detection on partially annotated images. Our approach iteratively learns to assign pseudo-labels to individuals in un-annotated images and learns to update the important people detection model based on data with both labels and pseudo-labels. To alleviate the pseudo-labelling imbalance problem, we introduce a ranking strategy for pseudo-label estimation, and also introduce two weighting strategies: one for weighting the confidence that individuals are important people to strengthen the learning on important people and the other for neglecting noisy unlabelled images (ie, images without any important people). We have collected two large-scale datasets for evaluation. The extensive experimental results clearly confirm the efficacy of our method attained by leveraging unlabelled images for improving the performance of important people detection.