 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-visual Controlled Video Diffusion with Masked Selective State Spaces Modeling for Natural Talking Head Generation
Apr 03, 2025Talking head synthesis is vital for virtual avatars and human-computer interaction. However, most existing methods are typically limited to accepting control from a single primary modality, restricting their practical utility. To this end, we introduce \textbf{ACTalker}, an end-to-end video diffusion framework that supports both multi-signals control and single-signal control for talking head video generation. For multiple control, we design a parallel mamba structure with multiple branches, each utilizing a separate driving signal to control specific facial regions. A gate mechanism is applied across all branches, providing flexible control over video generation. To ensure natural coordination of the controlled video both temporally and spatially, we employ the mamba structure, which enables driving signals to manipulate feature tokens across both dimensions in each branch. Additionally, we introduce a mask-drop strategy that allows each driving signal to independently control its corresponding facial region within the mamba structure, preventing control conflicts. Experimental results demonstrate that our method produces natural-looking facial videos driven by diverse signals and that the mamba layer seamlessly integrates multiple driving modalities without conflict.
Video Motion Graphs
Mar 26, 2025We present Video Motion Graphs, a system designed to generate realistic human motion videos. Using a reference video and conditional signals such as music or motion tags, the system synthesizes new videos by first retrieving video clips with gestures matching the conditions and then generating interpolation frames to seamlessly connect clip boundaries. The core of our approach is HMInterp, a robust Video Frame Interpolation (VFI) model that enables seamless interpolation of discontinuous frames, even for complex motion scenarios like dancing. HMInterp i) employs a dual-branch interpolation approach, combining a Motion Diffusion Model for human skeleton motion interpolation with a diffusion-based video frame interpolation model for final frame generation. ii) adopts condition progressive training to effectively leverage identity strong and weak conditions, such as images and pose. These designs ensure both high video texture quality and accurate motion trajectory. Results show that our Video Motion Graphs outperforms existing generative- and retrieval-based methods for multi-modal conditioned human motion video generation. Project page can be found at https://h-liu1997.github.io/Video-Motion-Graphs/
FireEdit: Fine-grained Instruction-based Image Editing via Region-aware Vision Language Model
Mar 25, 2025Currently, instruction-based image editing methods have made significant progress by leveraging the powerful cross-modal understanding capabilities of vision language models (VLMs). However, they still face challenges in three key areas: 1) complex scenarios; 2) semantic consistency; and 3) fine-grained editing. To address these issues, we propose FireEdit, an innovative Fine-grained Instruction-based image editing framework that exploits a REgion-aware VLM. FireEdit is designed to accurately comprehend user instructions and ensure effective control over the editing process. Specifically, we enhance the fine-grained visual perception capabilities of the VLM by introducing additional region tokens. Relying solely on the output of the LLM to guide the diffusion model may lead to suboptimal editing results. Therefore, we propose a Time-Aware Target Injection module and a Hybrid Visual Cross Attention module. The former dynamically adjusts the guidance strength at various denoising stages by integrating timestep embeddings with the text embeddings. The latter enhances visual details for image editing, thereby preserving semantic consistency between the edited result and the source image. By combining the VLM enhanced with fine-grained region tokens and the time-dependent diffusion model, FireEdit demonstrates significant advantages in comprehending editing instructions and maintaining high semantic consistency. Extensive experiments indicate that our approach surpasses the state-of-the-art instruction-based image editing methods. Our project is available at https://zjgans.github.io/fireedit.github.io.
HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation
Mar 25, 2025We introduce HunyuanPortrait, a diffusion-based condition control method that employs implicit representations for highly controllable and lifelike portrait animation. Given a single portrait image as an appearance reference and video clips as driving templates, HunyuanPortrait can animate the character in the reference image by the facial expression and head pose of the driving videos. In our framework, we utilize pre-trained encoders to achieve the decoupling of portrait motion information and identity in videos. To do so, implicit representation is adopted to encode motion information and is employed as control signals in the animation phase. By leveraging the power of stable video diffusion as the main building block, we carefully design adapter layers to inject control signals into the denoising unet through attention mechanisms. These bring spatial richness of details and temporal consistency. HunyuanPortrait also exhibits strong generalization performance, which can effectively disentangle appearance and motion under different image styles. Our framework outperforms existing methods, demonstrating superior temporal consistency and controllability. Our project is available at https://kkakkkka.github.io/HunyuanPortrait.
Identity-Preserving Video Dubbing Using Motion Warping
Jan 08, 2025



Video dubbing aims to synthesize realistic, lip-synced videos from a reference video and a driving audio signal. Although existing methods can accurately generate mouth shapes driven by audio, they often fail to preserve identity-specific features, largely because they do not effectively capture the nuanced interplay between audio cues and the visual attributes of reference identity . As a result, the generated outputs frequently lack fidelity in reproducing the unique textural and structural details of the reference identity. To address these limitations, we propose IPTalker, a novel and robust framework for video dubbing that achieves seamless alignment between driving audio and reference identity while ensuring both lip-sync accuracy and high-fidelity identity preservation. At the core of IPTalker is a transformer-based alignment mechanism designed to dynamically capture and model the correspondence between audio features and reference images, thereby enabling precise, identity-aware audio-visual integration. Building on this alignment, a motion warping strategy further refines the results by spatially deforming reference images to match the target audio-driven configuration. A dedicated refinement process then mitigates occlusion artifacts and enhances the preservation of fine-grained textures, such as mouth details and skin features. Extensive qualitative and quantitative evaluations demonstrate that IPTalker consistently outperforms existing approaches in terms of realism, lip synchronization, and identity retention, establishing a new state of the art for high-quality, identity-consistent video dubbing.
Free-viewpoint Human Animation with Pose-correlated Reference Selection
Dec 23, 2024



Diffusion-based human animation aims to animate a human character based on a source human image as well as driving signals such as a sequence of poses. Leveraging the generative capacity of diffusion model, existing approaches are able to generate high-fidelity poses, but struggle with significant viewpoint changes, especially in zoom-in/zoom-out scenarios where camera-character distance varies. This limits the applications such as cinematic shot type plan or camera control. We propose a pose-correlated reference selection diffusion network, supporting substantial viewpoint variations in human animation. Our key idea is to enable the network to utilize multiple reference images as input, since significant viewpoint changes often lead to missing appearance details on the human body. To eliminate the computational cost, we first introduce a novel pose correlation module to compute similarities between non-aligned target and source poses, and then propose an adaptive reference selection strategy, utilizing the attention map to identify key regions for animation generation. To train our model, we curated a large dataset from public TED talks featuring varied shots of the same character, helping the model learn synthesis for different perspectives. Our experimental results show that with the same number of reference images, our model performs favorably compared to the current SOTA methods under large viewpoint change. We further show that the adaptive reference selection is able to choose the most relevant reference regions to generate humans under free viewpoints.
Synergizing Motion and Appearance: Multi-Scale Compensatory Codebooks for Talking Head Video Generation
Dec 01, 2024



Talking head video generation aims to generate a realistic talking head video that preserves the person's identity from a source image and the motion from a driving video. Despite the promising progress made in the field, it remains a challenging and critical problem to generate videos with accurate poses and fine-grained facial details simultaneously. Essentially, facial motion is often highly complex to model precisely, and the one-shot source face image cannot provide sufficient appearance guidance during generation due to dynamic pose changes. To tackle the problem, we propose to jointly learn motion and appearance codebooks and perform multi-scale codebook compensation to effectively refine both the facial motion conditions and appearance features for talking face image decoding. Specifically, the designed multi-scale motion and appearance codebooks are learned simultaneously in a unified framework to store representative global facial motion flow and appearance patterns. Then, we present a novel multi-scale motion and appearance compensation module, which utilizes a transformer-based codebook retrieval strategy to query complementary information from the two codebooks for joint motion and appearance compensation. The entire process produces motion flows of greater flexibility and appearance features with fewer distortions across different scales, resulting in a high-quality talking head video generation framework. Extensive experiments on various benchmarks validate the effectiveness of our approach and demonstrate superior generation results from both qualitative and quantitative perspectives when compared to state-of-the-art competitors.
DreamHead: Learning Spatial-Temporal Correspondence via Hierarchical Diffusion for Audio-driven Talking Head Synthesis
Sep 16, 2024



Audio-driven talking head synthesis strives to generate lifelike video portraits from provided audio. The diffusion model, recognized for its superior quality and robust generalization, has been explored for this task. However, establishing a robust correspondence between temporal audio cues and corresponding spatial facial expressions with diffusion models remains a significant challenge in talking head generation. To bridge this gap, we present DreamHead, a hierarchical diffusion framework that learns spatial-temporal correspondences in talking head synthesis without compromising the model's intrinsic quality and adaptability.~DreamHead learns to predict dense facial landmarks from audios as intermediate signals to model the spatial and temporal correspondences.~Specifically, a first hierarchy of audio-to-landmark diffusion is first designed to predict temporally smooth and accurate landmark sequences given audio sequence signals. Then, a second hierarchy of landmark-to-image diffusion is further proposed to produce spatially consistent facial portrait videos, by modeling spatial correspondences between the dense facial landmark and appearance. Extensive experiments show that proposed DreamHead can effectively learn spatial-temporal consistency with the designed hierarchical diffusion and produce high-fidelity audio-driven talking head videos for multiple identities.
Learning Online Scale Transformation for Talking Head Video Generation
Jul 13, 2024
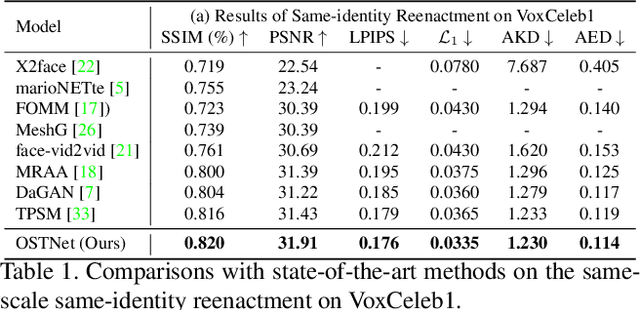
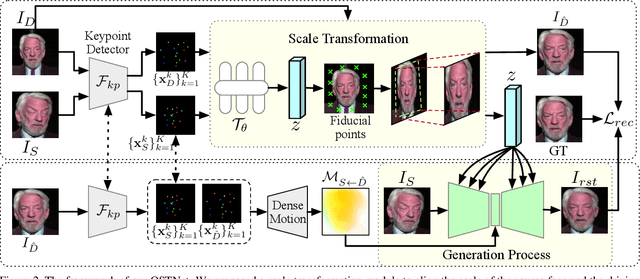
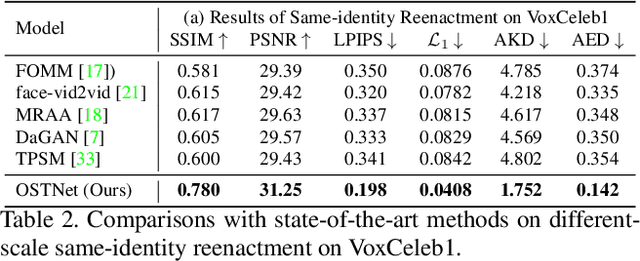
One-shot talking head video generation uses a source image and driving video to create a synthetic video where the source person's facial movements imitate those of the driving video. However, differences in scale between the source and driving images remain a challenge for face reenactment. Existing methods attempt to locate a frame in the driving video that aligns best with the source image, but imprecise alignment can result in suboptimal outcomes. To this end, we introduce a scale transformation module that can automatically adjust the scale of the driving image to fit that of the source image, by using the information of scale difference maintained in the detected keypoints of the source image and the driving frame. Furthermore, to keep perceiving the scale information of faces during the generation process, we incorporate the scale information learned from the scale transformation module into each layer of the generation process to produce a final result with an accurate scale. Our method can perform accurate motion transfer between the two images without any anchor frame, achieved through the contributions of the proposed online scale transformation facial reenactment network. Extensive experiments have demonstrated that our proposed method adjusts the scale of the driving face automatically according to the source face, and generates high-quality faces with an accurate scale in the cross-identity facial reenactment.
Implicit Identity Representation Conditioned Memory Compensation Network for Talking Head video Generation
Jul 20, 2023Talking head video generation aims to animate a human face in a still image with dynamic poses and expressions using motion information derived from a target-driving video, while maintaining the person's identity in the source image. However, dramatic and complex motions in the driving video cause ambiguous generation, because the still source image cannot provide sufficient appearance information for occluded regions or delicate expression variations, which produces severe artifacts and significantly degrades the generation quality. To tackle this problem, we propose to learn a global facial representation space, and design a novel implicit identity representation conditioned memory compensation network, coined as MCNet, for high-fidelity talking head generation.~Specifically, we devise a network module to learn a unified spatial facial meta-memory bank from all training samples, which can provide rich facial structure and appearance priors to compensate warped source facial features for the generation. Furthermore, we propose an effective query mechanism based on implicit identity representations learned from the discrete keypoints of the source image. It can greatly facilitate the retrieval of more correlated information from the memory bank for the compensation. Extensive experiments demonstrate that MCNet can learn representative and complementary facial memory, and can clearly outperform previous state-of-the-art talking head generation methods on VoxCeleb1 and CelebV datasets. Please check our \href{https://github.com/harlanhong/ICCV2023-MCNET}{Project}.