 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheraAgent: Multi-Agent Framework with Self-Evolving Memory and Evidence-Calibrated Reasoning for PET Theranostics
Mar 14, 2026PET theranostics is transforming precision oncology, yet treatment response varies substantially; many patients receiving 177Lu-PSMA radioligand therapy (RLT) for metastatic castration-resistant prostate cancer (mCRPC) fail to respond, demanding reliable pre-therapy prediction. While LLM-based agents have shown remarkable potential in complex medical diagnosis, their application to PET theranostic outcome prediction remains unexplored, which faces three key challenges: (1) data and knowledge scarcity: RLT was only FDA-approved in 2022, yielding few training cases and insufficient domain knowledge in general LLMs; (2) heterogeneous information integration: robust prediction hinges on structured knowledge extraction from PET/CT, laboratory tests, and free-text clinical documentation; (3) evidence-grounded reasoning: clinical decisions must be anchored in trial evidence rather than LLM hallucinations. In this paper, we present TheraAgent, to our knowledge, the first agentic framework for PET theranostics, with three core innovations: (1) Multi-Expert Feature Extraction with Confidence-Weighted Consensus, where three specialized experts process heterogeneous inputs with uncertainty quantification; (2) Self-Evolving Agentic Memory (SEA-Mem), which learns prognostic patterns from accumulated cases, enabling case-based reasoning from limited data; (3) Evidence-Calibrated Reasoning, integrating a curated theranostics knowledge base to ground predictions in VISION/TheraP trial evidence. Evaluated on 35 real patients and 400 synthetic cases, TheraAgent achieves 75.7% overall accuracy on real patients and 87.0% on synthetic cases, outperforming MDAgents and MedAgent-Pro by over 20%. These results highlight a promising blueprint for trustworthy AI agents in PET theranostics, enabling trial-calibrated, multi-source decision support. Code will be released upon acceptance.
MedXIAOHE: A Comprehensive Recipe for Building Medical MLLMs
Feb 16, 2026We present MedXIAOHE, a medical vision-language foundation model designed to advance general-purpose medical understanding and reasoning in real-world clinical applications. MedXIAOHE achieves state-of-the-art performance across diverse medical benchmarks and surpasses leading closed-source multimodal systems on multiple capabilities. To achieve this, we propose an entity-aware continual pretraining framework that organizes heterogeneous medical corpora to broaden knowledge coverage and reduce long-tail gaps (e.g., rare diseases). For medical expert-level reasoning and interaction, MedXIAOHE incorporates diverse medical reasoning patterns via reinforcement learning and tool-augmented agentic training, enabling multi-step diagnostic reasoning with verifiable decision traces. To improve reliability in real-world use, MedXIAOHE integrates user-preference rubrics, evidence-grounded reasoning, and low-hallucination long-form report generation, with improved adherence to medical instructions. We release this report to document our practical design choices, scaling insights, and evaluation framework, hoping to inspire further research.
DEEPMED: Building a Medical DeepResearch Agent via Multi-hop Med-Search Data and Turn-Controlled Agentic Training & Inference
Jan 26, 2026Medical reasoning models remain constrained by parametric knowledge and are thus susceptible to forgetting and hallucinations. DeepResearch (DR) models ground outputs in verifiable evidence from tools and perform strongly in general domains, but their direct transfer to medical field yields relatively limited gains. We attribute this to two gaps: task characteristic and tool-use scaling. Medical questions require evidence interpretation in a knowledge-intensive clinical context; while general DR models can retrieve information, they often lack clinical-context reasoning and thus "find it but fail to use it," leaving performance limited by medical abilities. Moreover, in medical scenarios, blindly scaling tool-call can inject noisy context, derailing sensitive medical reasoning and prompting repetitive evidence-seeking along incorrect paths. Therefore, we propose DeepMed. For data, we deploy a multi-hop med-search QA synthesis method supporting the model to apply the DR paradigm in medical contexts. For training, we introduce a difficulty-aware turn-penalty to suppress excessive tool-call growth. For inference, we bring a monitor to help validate hypotheses within a controlled number of steps and avoid context rot. Overall, on seven medical benchmarks, DeepMed improves its base model by 9.79\% on average and outperforms larger medical reasoning and DR models.
Align and Surpass Human Camouflaged Perception: Visual Refocus Reinforcement Fine-Tuning
May 26, 2025

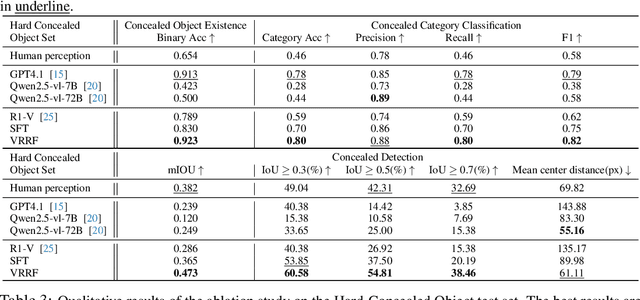

Current multi-modal models exhibit a notable misalignment with the human visual system when identifying objects that are visually assimilated into the background. Our observations reveal that these multi-modal models cannot distinguish concealed objects, demonstrating an inability to emulate human cognitive processes which effectively utilize foreground-background similarity principles for visual analysis. To analyze this hidden human-model visual thinking discrepancy, we build a visual system that mimicks human visual camouflaged perception to progressively and iteratively `refocus' visual concealed content. The refocus is a progressive guidance mechanism enabling models to logically localize objects in visual images through stepwise reasoning. The localization process of concealed objects requires hierarchical attention shifting with dynamic adjustment and refinement of prior cognitive knowledge. In this paper, we propose a visual refocus reinforcement framework via the policy optimization algorithm to encourage multi-modal models to think and refocus more before answering, and achieve excellent reasoning abilities to align and even surpass human camouflaged perception systems. Our extensive experiments on camouflaged perception successfully demonstrate the emergence of refocus visual phenomena, characterized by multiple reasoning tokens and dynamic adjustment of the detection box. Besides, experimental results on both camouflaged object classification and detection tasks exhibit significantly superior performance compared to Supervised Fine-Tuning (SFT) baselines.
Disentangle Identity, Cooperate Emotion: Correlation-Aware Emotional Talking Portrait Generation
Apr 25, 2025Recent advances in Talking Head Generation (THG) have achieved impressive lip synchronization and visual quality through diffusion models; yet existing methods struggle to generate emotionally expressive portraits while preserving speaker identity. We identify three critical limitations in current emotional talking head generation: insufficient utilization of audio's inherent emotional cues, identity leakage in emotion representations, and isolated learning of emotion correlations. To address these challenges, we propose a novel framework dubbed as DICE-Talk, following the idea of disentangling identity with emotion, and then cooperating emotions with similar characteristics. First, we develop a disentangled emotion embedder that jointly models audio-visual emotional cues through cross-modal attention, representing emotions as identity-agnostic Gaussian distributions. Second, we introduce a correlation-enhanced emotion conditioning module with learnable Emotion Banks that explicitly capture inter-emotion relationships through vector quantization and attention-based feature aggregation. Third, we design an emotion discrimination objective that enforces affective consistency during the diffusion process through latent-space classification. Extensive experiments on MEAD and HDTF datasets demonstrate our method's superiority, outperforming state-of-the-art approaches in emotion accuracy while maintaining competitive lip-sync performance. Qualitative results and user studies further confirm our method's ability to generate identity-preserving portraits with rich, correlated emotional expressions that naturally adapt to unseen identities.
HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation
Mar 25, 2025We introduce HunyuanPortrait, a diffusion-based condition control method that employs implicit representations for highly controllable and lifelike portrait animation. Given a single portrait image as an appearance reference and video clips as driving templates, HunyuanPortrait can animate the character in the reference image by the facial expression and head pose of the driving videos. In our framework, we utilize pre-trained encoders to achieve the decoupling of portrait motion information and identity in videos. To do so, implicit representation is adopted to encode motion information and is employed as control signals in the animation phase. By leveraging the power of stable video diffusion as the main building block, we carefully design adapter layers to inject control signals into the denoising unet through attention mechanisms. These bring spatial richness of details and temporal consistency. HunyuanPortrait also exhibits strong generalization performance, which can effectively disentangle appearance and motion under different image styles. Our framework outperforms existing methods, demonstrating superior temporal consistency and controllability. Our project is available at https://kkakkkka.github.io/HunyuanPortrait.
Sonic: Shifting Focus to Global Audio Perception in Portrait Animation
Nov 25, 2024



The study of talking face generation mainly explores the intricacies of synchronizing facial movements and crafting visually appealing, temporally-coherent animations. However, due to the limited exploration of global audio perception, current approaches predominantly employ auxiliary visual and spatial knowledge to stabilize the movements, which often results in the deterioration of the naturalness and temporal inconsistencies.Considering the essence of audio-driven animation, the audio signal serves as the ideal and unique priors to adjust facial expressions and lip movements, without resorting to interference of any visual signals. Based on this motivation, we propose a novel paradigm, dubbed as Sonic, to {s}hift f{o}cus on the exploration of global audio per{c}ept{i}o{n}.To effectively leverage global audio knowledge, we disentangle it into intra- and inter-clip audio perception and collaborate with both aspects to enhance overall perception.For the intra-clip audio perception, 1). \textbf{Context-enhanced audio learning}, in which long-range intra-clip temporal audio knowledge is extracted to provide facial expression and lip motion priors implicitly expressed as the tone and speed of speech. 2). \textbf{Motion-decoupled controller}, in which the motion of the head and expression movement are disentangled and independently controlled by intra-audio clips. Most importantly, for inter-clip audio perception, as a bridge to connect the intra-clips to achieve the global perception, \textbf{Time-aware position shift fusion}, in which the global inter-clip audio information is considered and fused for long-audio inference via through consecutively time-aware shifted windows. Extensive experiments demonstrate that the novel audio-driven paradigm outperform existing SOTA methodologies in terms of video quality, temporally consistency, lip synchronization precision, and motion diversity.
SVP: Style-Enhanced Vivid Portrait Talking Head Diffusion Model
Sep 05, 2024Talking Head Generation (THG), typically driven by audio, is an important and challenging task with broad application prospects in various fields such as digital humans, film production, and virtual reality. While diffusion model-based THG methods present high quality and stable content generation, they often overlook the intrinsic style which encompasses personalized features such as speaking habits and facial expressions of a video. As consequence, the generated video content lacks diversity and vividness, thus being limited in real life scenarios. To address these issues, we propose a novel framework named Style-Enhanced Vivid Portrait (SVP) which fully leverages style-related information in THG. Specifically, we first introduce the novel probabilistic style prior learning to model the intrinsic style as a Gaussian distribution using facial expressions and audio embedding. The distribution is learned through the 'bespoked' contrastive objective, effectively capturing the dynamic style information in each video. Then we finetune a pretrained Stable Diffusion (SD) model to inject the learned intrinsic style as a controlling signal via cross attention. Experiments show that our model generates diverse, vivid, and high-quality videos with flexible control over intrinsic styles, outperforming existing state-of-the-art methods.
RealTalk: Real-time and Realistic Audio-driven Face Generation with 3D Facial Prior-guided Identity Alignment Network
Jun 26, 2024Person-generic audio-driven face generation is a challenging task in computer vision. Previous methods have achieved remarkable progress in audio-visual synchronization, but there is still a significant gap between current results and practical applications. The challenges are two-fold: 1) Preserving unique individual traits for achieving high-precision lip synchronization. 2) Generating high-quality facial renderings in real-time performance. In this paper, we propose a novel generalized audio-driven framework RealTalk, which consists of an audio-to-expression transformer and a high-fidelity expression-to-face renderer. In the first component, we consider both identity and intra-personal variation features related to speaking lip movements. By incorporating cross-modal attention on the enriched facial priors, we can effectively align lip movements with audio, thus attaining greater precision in expression prediction. In the second component, we design a lightweight facial identity alignment (FIA) module which includes a lip-shape control structure and a face texture reference structure. This novel design allows us to generate fine details in real-time, without depending on sophisticated and inefficient feature alignment modules. Our experimental results, both quantitative and qualitative, on public datasets demonstrate the clear advantages of our method in terms of lip-speech synchronization and generation quality. Furthermore, our method is efficient and requires fewer computational resources, making it well-suited to meet the needs of practical applications.
DiffuMatting: Synthesizing Arbitrary Objects with Matting-level Annotation
Mar 10, 2024Due to the difficulty and labor-consuming nature of getting highly accurate or matting annotations, there only exists a limited amount of highly accurate labels available to the public. To tackle this challenge, we propose a DiffuMatting which inherits the strong Everything generation ability of diffusion and endows the power of "matting anything". Our DiffuMatting can 1). act as an anything matting factory with high accurate annotations 2). be well-compatible with community LoRAs or various conditional control approaches to achieve the community-friendly art design and controllable generation. Specifically, inspired by green-screen-matting, we aim to teach the diffusion model to paint on a fixed green screen canvas. To this end, a large-scale greenscreen dataset (Green100K) is collected as a training dataset for DiffuMatting. Secondly, a green background control loss is proposed to keep the drawing board as a pure green color to distinguish the foreground and background. To ensure the synthesized object has more edge details, a detailed-enhancement of transition boundary loss is proposed as a guideline to generate objects with more complicated edge structures. Aiming to simultaneously generate the object and its matting annotation, we build a matting head to make a green color removal in the latent space of the VAE decoder. Our DiffuMatting shows several potential applications (e.g., matting-data generator, community-friendly art design and controllable generation). As a matting-data generator, DiffuMatting synthesizes general object and portrait matting sets, effectively reducing the relative MSE error by 15.4% in General Object Matting and 11.4% in Portrait Matting tasks.