 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistentRFT: Reducing Visual Hallucinations in Flow-based Reinforcement Fine-Tuning
Feb 03, 2026Reinforcement Fine-Tuning (RFT) on flow-based models is crucial for preference alignment. However, they often introduce visual hallucinations like over-optimized details and semantic misalignment. This work preliminarily explores why visual hallucinations arise and how to reduce them. We first investigate RFT methods from a unified perspective, and reveal the core problems stemming from two aspects, exploration and exploitation: (1) limited exploration during stochastic differential equation (SDE) rollouts, leading to an over-emphasis on local details at the expense of global semantics, and (2) trajectory imitation process inherent in policy gradient methods, distorting the model's foundational vector field and its cross-step consistency. Building on this, we propose ConsistentRFT, a general framework to mitigate these hallucinations. Specifically, we design a Dynamic Granularity Rollout (DGR) mechanism to balance exploration between global semantics and local details by dynamically scheduling different noise sources. We then introduce a Consistent Policy Gradient Optimization (CPGO) that preserves the model's consistency by aligning the current policy with a more stable prior. Extensive experiments demonstrate that ConsistentRFT significantly mitigates visual hallucinations, achieving average reductions of 49\% for low-level and 38\% for high-level perceptual hallucinations. Furthermore, ConsistentRFT outperforms other RFT methods on out-of-domain metrics, showing an improvement of 5.1\% (v.s. the baseline's decrease of -0.4\%) over FLUX1.dev. This is \href{https://xiaofeng-tan.github.io/projects/ConsistentRFT}{Project Page}.
YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection
Dec 30, 2025Existing Real-Time Object Detection (RTOD) methods commonly adopt YOLO-like architectures for their favorable trade-off between accuracy and speed. However, these models rely on static dense computation that applies uniform processing to all inputs, misallocating representational capacity and computational resources such as over-allocating on trivial scenes while under-serving complex ones. This mismatch results in both computational redundancy and suboptimal detection performance. To overcome this limitation, we propose YOLO-Master, a novel YOLO-like framework that introduces instance-conditional adaptive computation for RTOD. This is achieved through a Efficient Sparse Mixture-of-Experts (ES-MoE) block that dynamically allocates computational resources to each input according to its scene complexity. At its core, a lightweight dynamic routing network guides expert specialization during training through a diversity enhancing objective, encouraging complementary expertise among experts. Additionally, the routing network adaptively learns to activate only the most relevant experts, thereby improving detection performance while minimizing computational overhead during inference. Comprehensive experiments on five large-scale benchmarks demonstrate the superiority of YOLO-Master. On MS COCO, our model achieves 42.4% AP with 1.62ms latency, outperforming YOLOv13-N by +0.8% mAP and 17.8% faster inference. Notably, the gains are most pronounced on challenging dense scenes, while the model preserves efficiency on typical inputs and maintains real-time inference speed. Code will be available.
CareCom: Generative Image Composition with Calibrated Reference Features
Nov 14, 2025Image composition aims to seamlessly insert foreground object into background. Despite the huge progress in generative image composition, the existing methods are still struggling with simultaneous detail preservation and foreground pose/view adjustment. To address this issue, we extend the existing generative composition model to multi-reference version, which allows using arbitrary number of foreground reference images. Furthermore, we propose to calibrate the global and local features of foreground reference images to make them compatible with the background information. The calibrated reference features can supplement the original reference features with useful global and local information of proper pose/view. Extensive experiments on MVImgNet and MureCom demonstrate that the generative model can greatly benefit from the calibrated reference features.
Towards Fine-Grained Vision-Language Alignment for Few-Shot Anomaly Detection
Oct 30, 2025



Few-shot anomaly detection (FSAD) methods identify anomalous regions with few known normal samples. Most existing methods rely on the generalization ability of pre-trained vision-language models (VLMs) to recognize potentially anomalous regions through feature similarity between text descriptions and images. However, due to the lack of detailed textual descriptions, these methods can only pre-define image-level descriptions to match each visual patch token to identify potential anomalous regions, which leads to the semantic misalignment between image descriptions and patch-level visual anomalies, achieving sub-optimal localization performance. To address the above issues, we propose the Multi-Level Fine-Grained Semantic Caption (MFSC) to provide multi-level and fine-grained textual descriptions for existing anomaly detection datasets with automatic construction pipeline. Based on the MFSC, we propose a novel framework named FineGrainedAD to improve anomaly localization performance, which consists of two components: Multi-Level Learnable Prompt (MLLP) and Multi-Level Semantic Alignment (MLSA). MLLP introduces fine-grained semantics into multi-level learnable prompts through automatic replacement and concatenation mechanism, while MLSA designs region aggregation strategy and multi-level alignment training to facilitate learnable prompts better align with corresponding visual regions. Experiments demonstrate that the proposed FineGrainedAD achieves superior overall performance in few-shot settings on MVTec-AD and VisA datasets.
Swin DiT: Diffusion Transformer using Pseudo Shifted Windows
May 19, 2025Diffusion Transformers (DiTs) achieve remarkable performance within the domain of image generation through the incorporation of the transformer architecture. Conventionally, DiTs are constructed by stacking serial isotropic global information modeling transformers, which face significant computational cost when processing high-resolution images. We empirically analyze that latent space image generation does not exhibit a strong dependence on global information as traditionally assumed. Most of the layers in the model demonstrate redundancy in global computation. In addition, conventional attention mechanisms exhibit low-frequency inertia issues. To address these issues, we propose \textbf{P}seudo \textbf{S}hifted \textbf{W}indow \textbf{A}ttention (PSWA), which fundamentally mitigates global model redundancy. PSWA achieves intermediate global-local information interaction through window attention, while employing a high-frequency bridging branch to simulate shifted window operations, supplementing appropriate global and high-frequency information. Furthermore, we propose the Progressive Coverage Channel Allocation(PCCA) strategy that captures high-order attention similarity without additional computational cost. Building upon all of them, we propose a series of Pseudo \textbf{S}hifted \textbf{Win}dow DiTs (\textbf{Swin DiT}), accompanied by extensive experiments demonstrating their superior performance. For example, our proposed Swin-DiT-L achieves a 54%$\uparrow$ FID improvement over DiT-XL/2 while requiring less computational. https://github.com/wujiafu007/Swin-DiT
VITA-Audio: Fast Interleaved Cross-Modal Token Generation for Efficient Large Speech-Language Model
May 06, 2025With the growing requirement for natural human-computer interaction, speech-based systems receive increasing attention as speech is one of the most common forms of daily communication. However, the existing speech models still experience high latency when generating the first audio token during streaming, which poses a significant bottleneck for deployment. To address this issue, we propose VITA-Audio, an end-to-end large speech model with fast audio-text token generation. Specifically, we introduce a lightweight Multiple Cross-modal Token Prediction (MCTP) module that efficiently generates multiple audio tokens within a single model forward pass, which not only accelerates the inference but also significantly reduces the latency for generating the first audio in streaming scenarios. In addition, a four-stage progressive training strategy is explored to achieve model acceleration with minimal loss of speech quality. To our knowledge, VITA-Audio is the first multi-modal large language model capable of generating audio output during the first forward pass, enabling real-time conversational capabilities with minimal latency. VITA-Audio is fully reproducible and is trained on open-source data only. Experimental results demonstrate that our model achieves an inference speedup of 3~5x at the 7B parameter scale, but also significantly outperforms open-source models of similar model size on multiple benchmarks for automatic speech recognition (ASR), text-to-speech (TTS), and spoken question answering (SQA) tasks.
UniCombine: Unified Multi-Conditional Combination with Diffusion Transformer
Mar 12, 2025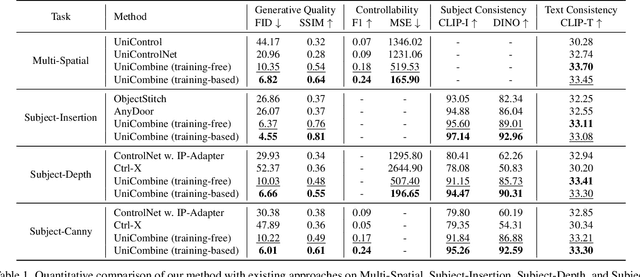
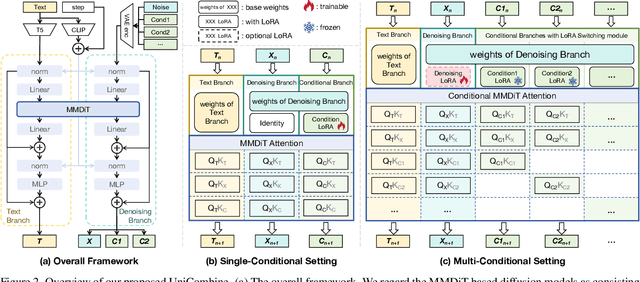
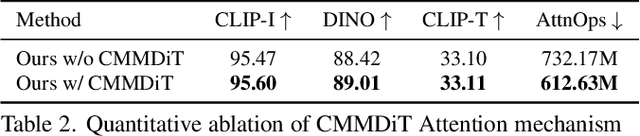
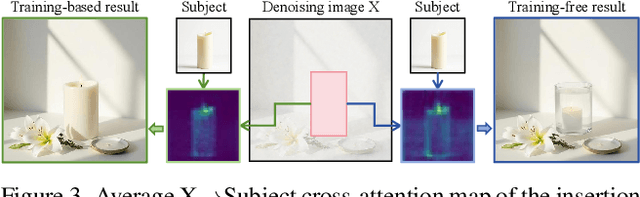
With the rapid development of diffusion models in image generation, the demand for more powerful and flexible controllable frameworks is increasing. Although existing methods can guide generation beyond text prompts, the challenge of effectively combining multiple conditional inputs while maintaining consistency with all of them remains unsolved. To address this, we introduce UniCombine, a DiT-based multi-conditional controllable generative framework capable of handling any combination of conditions, including but not limited to text prompts, spatial maps, and subject images. Specifically, we introduce a novel Conditional MMDiT Attention mechanism and incorporate a trainable LoRA module to build both the training-free and training-based versions. Additionally, we propose a new pipeline to construct SubjectSpatial200K, the first dataset designed for multi-conditional generative tasks covering both the subject-driven and spatially-aligned conditions. Extensive experimental results on multi-conditional generation demonstrate the outstanding universality and powerful capability of our approach with state-of-the-art performance.
PixelPonder: Dynamic Patch Adaptation for Enhanced Multi-Conditional Text-to-Image Generation
Mar 09, 2025Recent advances in diffusion-based text-to-image generation have demonstrated promising results through visual condition control. However, existing ControlNet-like methods struggle with compositional visual conditioning - simultaneously preserving semantic fidelity across multiple heterogeneous control signals while maintaining high visual quality, where they employ separate control branches that often introduce conflicting guidance during the denoising process, leading to structural distortions and artifacts in generated images. To address this issue, we present PixelPonder, a novel unified control framework, which allows for effective control of multiple visual conditions under a single control structure. Specifically, we design a patch-level adaptive condition selection mechanism that dynamically prioritizes spatially relevant control signals at the sub-region level, enabling precise local guidance without global interference. Additionally, a time-aware control injection scheme is deployed to modulate condition influence according to denoising timesteps, progressively transitioning from structural preservation to texture refinement and fully utilizing the control information from different categories to promote more harmonious image generation. Extensive experiments demonstrate that PixelPonder surpasses previous methods across different benchmark datasets, showing superior improvement in spatial alignment accuracy while maintaining high textual semantic consistency.
DynamicControl: Adaptive Condition Selection for Improved Text-to-Image Generation
Dec 04, 2024



To enhance the controllability of text-to-image diffusion models, current ControlNet-like models have explored various control signals to dictate image attributes. However, existing methods either handle conditions inefficiently or use a fixed number of conditions, which does not fully address the complexity of multiple conditions and their potential conflicts. This underscores the need for innovative approaches to manage multiple conditions effectively for more reliable and detailed image synthesis. To address this issue, we propose a novel framework, DynamicControl, which supports dynamic combinations of diverse control signals, allowing adaptive selection of different numbers and types of conditions. Our approach begins with a double-cycle controller that generates an initial real score sorting for all input conditions by leveraging pre-trained conditional generation models and discriminative models. This controller evaluates the similarity between extracted conditions and input conditions, as well as the pixel-level similarity with the source image. Then, we integrate a Multimodal Large Language Model (MLLM) to build an efficient condition evaluator. This evaluator optimizes the ordering of conditions based on the double-cycle controller's score ranking. Our method jointly optimizes MLLMs and diffusion models, utilizing MLLMs' reasoning capabilities to facilitate multi-condition text-to-image (T2I) tasks. The final sorted conditions are fed into a parallel multi-control adapter, which learns feature maps from dynamic visual conditions and integrates them to modulate ControlNet, thereby enhancing control over generated images. Through both quantitative and qualitative comparisons, DynamicControl demonstrates its superiority over existing methods in terms of controllability, generation quality and composability under various conditional controls.
FitDiT: Advancing the Authentic Garment Details for High-fidelity Virtual Try-on
Nov 22, 2024



Although image-based virtual try-on has made considerable progress, emerging approaches still encounter challenges in producing high-fidelity and robust fitting images across diverse scenarios. These methods often struggle with issues such as texture-aware maintenance and size-aware fitting, which hinder their overall effectiveness. To address these limitations, we propose a novel garment perception enhancement technique, termed FitDiT, designed for high-fidelity virtual try-on using Diffusion Transformers (DiT) allocating more parameters and attention to high-resolution features. First, to further improve texture-aware maintenance, we introduce a garment texture extractor that incorporates garment priors evolution to fine-tune garment feature, facilitating to better capture rich details such as stripes, patterns, and text. Additionally, we introduce frequency-domain learning by customizing a frequency distance loss to enhance high-frequency garment details. To tackle the size-aware fitting issue, we employ a dilated-relaxed mask strategy that adapts to the correct length of garments, preventing the generation of garments that fill the entire mask area during cross-category try-on. Equipped with the above design, FitDiT surpasses all baselines in both qualitative and quantitative evaluations. It excels in producing well-fitting garments with photorealistic and intricate details, while also achieving competitive inference times of 4.57 seconds for a single 1024x768 image after DiT structure slimming, outperforming existing methods.