 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAVEDIT: Joint Audio-Visual Instruction-Guided Video Editing with Agentic Data Curation
Jun 02, 2026While instruction-based video editing has seen significant progress, joint audio-visual editing remains constrained by the absence of dedicated datasets and benchmarks. To bridge this gap, we present JAVEdit-100k, the first large-scale, high-quality dataset tailored for instruction-guided joint audio-visual editing. Focusing on human-centric videos, JAVEdit-100k comprises approximately 100K editing triplets spanning five distinct categories, including subject editing and speech editing. This dataset is rigorously constructed via four meticulously designed generation pipelines, seamlessly paired with an agent-in-the-loop quality control mechanism. Furthermore, to address the lack of standardized evaluation within the field, we introduce JAVEditBench, a comprehensive benchmark featuring curated source videos and human-aligned instructions across all editing categories. Finally, we propose JAVEdit, a pioneering baseline model for instruction-guided joint audio-visual editing. Experiments show that \model\ outperforms all baselines on five of six evaluation metrics.
FFP-300K: Scaling First-Frame Propagation for Generalizable Video Editing
Jan 06, 2026First-Frame Propagation (FFP) offers a promising paradigm for controllable video editing, but existing methods are hampered by a reliance on cumbersome run-time guidance. We identify the root cause of this limitation as the inadequacy of current training datasets, which are often too short, low-resolution, and lack the task diversity required to teach robust temporal priors. To address this foundational data gap, we first introduce FFP-300K, a new large-scale dataset comprising 300K high-fidelity video pairs at 720p resolution and 81 frames in length, constructed via a principled two-track pipeline for diverse local and global edits. Building on this dataset, we propose a novel framework designed for true guidance-free FFP that resolves the critical tension between maintaining first-frame appearance and preserving source video motion. Architecturally, we introduce Adaptive Spatio-Temporal RoPE (AST-RoPE), which dynamically remaps positional encodings to disentangle appearance and motion references. At the objective level, we employ a self-distillation strategy where an identity propagation task acts as a powerful regularizer, ensuring long-term temporal stability and preventing semantic drift. Comprehensive experiments on the EditVerseBench benchmark demonstrate that our method significantly outperforming existing academic and commercial models by receiving about 0.2 PickScore and 0.3 VLM score improvement against these competitors.
Transform Trained Transformer: Accelerating Naive 4K Video Generation Over 10$\times$
Dec 15, 2025Native 4K (2160$\times$3840) video generation remains a critical challenge due to the quadratic computational explosion of full-attention as spatiotemporal resolution increases, making it difficult for models to strike a balance between efficiency and quality. This paper proposes a novel Transformer retrofit strategy termed $\textbf{T3}$ ($\textbf{T}$ransform $\textbf{T}$rained $\textbf{T}$ransformer) that, without altering the core architecture of full-attention pretrained models, significantly reduces compute requirements by optimizing their forward logic. Specifically, $\textbf{T3-Video}$ introduces a multi-scale weight-sharing window attention mechanism and, via hierarchical blocking together with an axis-preserving full-attention design, can effect an "attention pattern" transformation of a pretrained model using only modest compute and data. Results on 4K-VBench show that $\textbf{T3-Video}$ substantially outperforms existing approaches: while delivering performance improvements (+4.29$\uparrow$ VQA and +0.08$\uparrow$ VTC), it accelerates native 4K video generation by more than 10$\times$. Project page at https://zhangzjn.github.io/projects/T3-Video
Soul: Breathe Life into Digital Human for High-fidelity Long-term Multimodal Animation
Dec 15, 2025We propose a multimodal-driven framework for high-fidelity long-term digital human animation termed $\textbf{Soul}$, which generates semantically coherent videos from a single-frame portrait image, text prompts, and audio, achieving precise lip synchronization, vivid facial expressions, and robust identity preservation. We construct Soul-1M, containing 1 million finely annotated samples with a precise automated annotation pipeline (covering portrait, upper-body, full-body, and multi-person scenes) to mitigate data scarcity, and we carefully curate Soul-Bench for comprehensive and fair evaluation of audio-/text-guided animation methods. The model is built on the Wan2.2-5B backbone, integrating audio-injection layers and multiple training strategies together with threshold-aware codebook replacement to ensure long-term generation consistency. Meanwhile, step/CFG distillation and a lightweight VAE are used to optimize inference efficiency, achieving an 11.4$\times$ speedup with negligible quality loss. Extensive experiments show that Soul significantly outperforms current leading open-source and commercial models on video quality, video-text alignment, identity preservation, and lip-synchronization accuracy, demonstrating broad applicability in real-world scenarios such as virtual anchors and film production. Project page at https://zhangzjn.github.io/projects/Soul/
OracleAgent: A Multimodal Reasoning Agent for Oracle Bone Script Research
Oct 30, 2025As one of the earliest writing systems, Oracle Bone Script (OBS) preserves the cultural and intellectual heritage of ancient civilizations. However, current OBS research faces two major challenges: (1) the interpretation of OBS involves a complex workflow comprising multiple serial and parallel sub-tasks, and (2) the efficiency of OBS information organization and retrieval remains a critical bottleneck, as scholars often spend substantial effort searching for, compiling, and managing relevant resources. To address these challenges, we present OracleAgent, the first agent system designed for the structured management and retrieval of OBS-related information. OracleAgent seamlessly integrates multiple OBS analysis tools, empowered by large language models (LLMs), and can flexibly orchestrate these components. Additionally, we construct a comprehensive domain-specific multimodal knowledge base for OBS, which is built through a rigorous multi-year process of data collection, cleaning, and expert annotation. The knowledge base comprises over 1.4M single-character rubbing images and 80K interpretation texts. OracleAgent leverages this resource through its multimodal tools to assist experts in retrieval tasks of character, document, interpretation text, and rubbing image. Extensive experiments demonstrate that OracleAgent achieves superior performance across a range of multimodal reasoning and generation tasks, surpassing leading mainstream multimodal large language models (MLLMs) (e.g., GPT-4o). Furthermore, our case study illustrates that OracleAgent can effectively assist domain experts, significantly reducing the time cost of OBS research. These results highlight OracleAgent as a significant step toward the practical deployment of OBS-assisted research and automated interpretation systems.
SwiftVideo: A Unified Framework for Few-Step Video Generation through Trajectory-Distribution Alignment
Aug 08, 2025Diffusion-based or flow-based models have achieved significant progress in video synthesis but require multiple iterative sampling steps, which incurs substantial computational overhead. While many distillation methods that are solely based on trajectory-preserving or distribution-matching have been developed to accelerate video generation models, these approaches often suffer from performance breakdown or increased artifacts under few-step settings. To address these limitations, we propose \textbf{\emph{SwiftVideo}}, a unified and stable distillation framework that combines the advantages of trajectory-preserving and distribution-matching strategies. Our approach introduces continuous-time consistency distillation to ensure precise preservation of ODE trajectories. Subsequently, we propose a dual-perspective alignment that includes distribution alignment between synthetic and real data along with trajectory alignment across different inference steps. Our method maintains high-quality video generation while substantially reducing the number of inference steps. Quantitative evaluations on the OpenVid-1M benchmark demonstrate that our method significantly outperforms existing approaches in few-step video generation.
DVHGNN: Multi-Scale Dilated Vision HGNN for Efficient Vision Recognition
Mar 19, 2025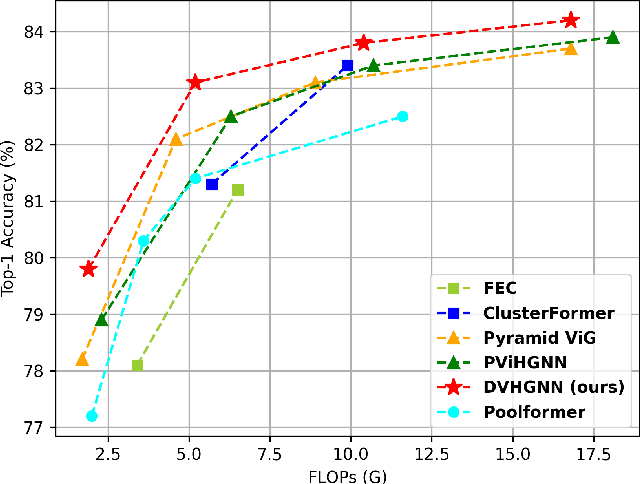

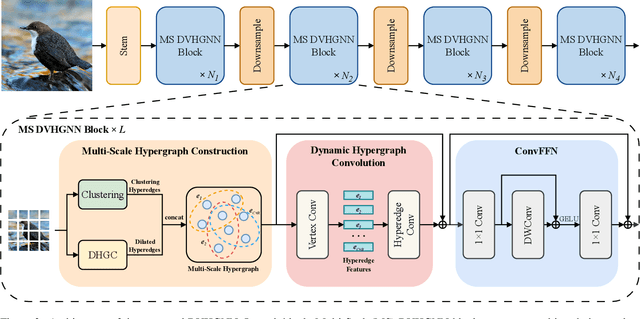
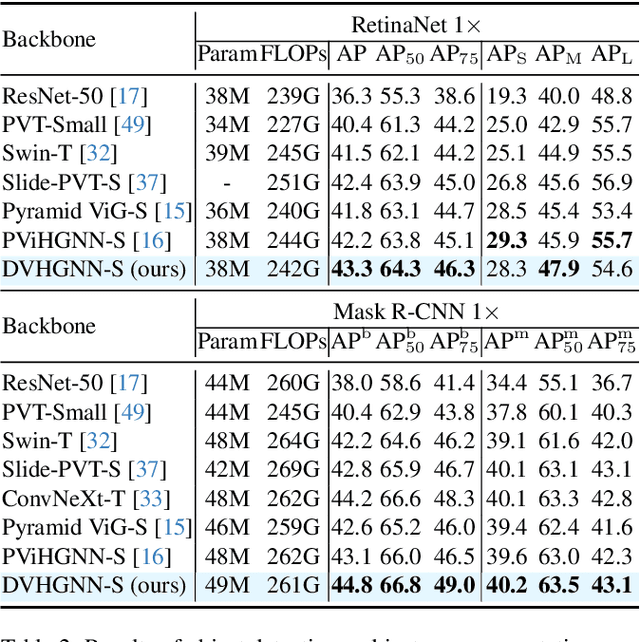
Recently, Vision Graph Neural Network (ViG) has gained considerable attention in computer vision. Despite its groundbreaking innovation, Vision Graph Neural Network encounters key issues including the quadratic computational complexity caused by its K-Nearest Neighbor (KNN) graph construction and the limitation of pairwise relations of normal graphs. To address the aforementioned challenges, we propose a novel vision architecture, termed Dilated Vision HyperGraph Neural Network (DVHGNN), which is designed to leverage multi-scale hypergraph to efficiently capture high-order correlations among objects. Specifically, the proposed method tailors Clustering and Dilated HyperGraph Construction (DHGC) to adaptively capture multi-scale dependencies among the data samples. Furthermore, a dynamic hypergraph convolution mechanism is proposed to facilitate adaptive feature exchange and fusion at the hypergraph level. Extensive qualitative and quantitative evaluations of the benchmark image datasets demonstrate that the proposed DVHGNN significantly outperforms the state-of-the-art vision backbones. For instance, our DVHGNN-S achieves an impressive top-1 accuracy of 83.1% on ImageNet-1K, surpassing ViG-S by +1.0% and ViHGNN-S by +0.6%.
CrossVTON: Mimicking the Logic Reasoning on Cross-category Virtual Try-on guided by Tri-zone Priors
Feb 20, 2025



Despite remarkable progress in image-based virtual try-on systems, generating realistic and robust fitting images for cross-category virtual try-on remains a challenging task. The primary difficulty arises from the absence of human-like reasoning, which involves addressing size mismatches between garments and models while recognizing and leveraging the distinct functionalities of various regions within the model images. To address this issue, we draw inspiration from human cognitive processes and disentangle the complex reasoning required for cross-category try-on into a structured framework. This framework systematically decomposes the model image into three distinct regions: try-on, reconstruction, and imagination zones. Each zone plays a specific role in accommodating the garment and facilitating realistic synthesis. To endow the model with robust reasoning capabilities for cross-category scenarios, we propose an iterative data constructor. This constructor encompasses diverse scenarios, including intra-category try-on, any-to-dress transformations (replacing any garment category with a dress), and dress-to-any transformations (replacing a dress with another garment category). Utilizing the generated dataset, we introduce a tri-zone priors generator that intelligently predicts the try-on, reconstruction, and imagination zones by analyzing how the input garment is expected to align with the model image. Guided by these tri-zone priors, our proposed method, CrossVTON, achieves state-of-the-art performance, surpassing existing baselines in both qualitative and quantitative evaluations. Notably, it demonstrates superior capability in handling cross-category virtual try-on, meeting the complex demands of real-world applications.
Exploring Real&Synthetic Dataset and Linear Attention in Image Restoration
Dec 05, 2024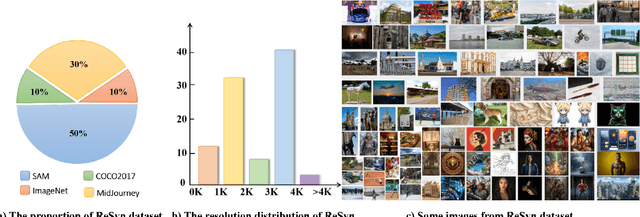
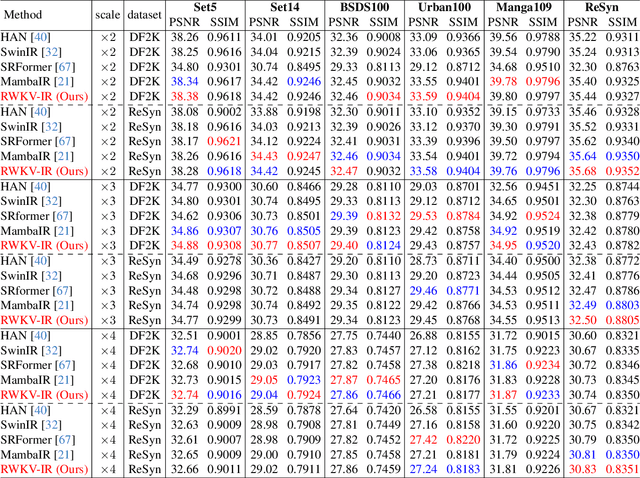
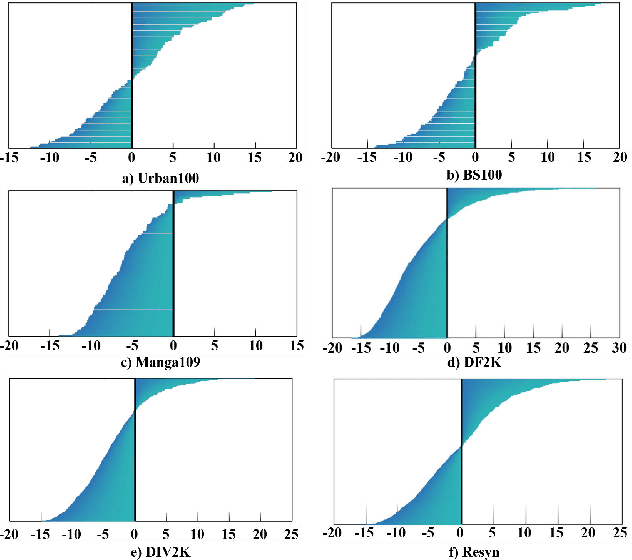

Image Restoration aims to restore degraded images, with deep learning, especially CNNs and Transformers, enhancing performance. However, there's a lack of a unified training benchmark for IR. We identified a bias in image complexity between training and testing datasets, affecting restoration quality. To address this, we created ReSyn, a large-scale IR dataset with balanced complexity, including real and synthetic images. We also established a unified training standard for IR models. Our RWKV-IR model integrates linear complexity RWKV into transformers for global and local receptive fields. It replaces Q-Shift with Depth-wise Convolution for local dependencies and combines Bi-directional attention for global-local awareness. The Cross-Bi-WKV module balances horizontal and vertical attention. Experiments show RWKV-IR's effectiveness in image restoration.
DynamicControl: Adaptive Condition Selection for Improved Text-to-Image Generation
Dec 04, 2024



To enhance the controllability of text-to-image diffusion models, current ControlNet-like models have explored various control signals to dictate image attributes. However, existing methods either handle conditions inefficiently or use a fixed number of conditions, which does not fully address the complexity of multiple conditions and their potential conflicts. This underscores the need for innovative approaches to manage multiple conditions effectively for more reliable and detailed image synthesis. To address this issue, we propose a novel framework, DynamicControl, which supports dynamic combinations of diverse control signals, allowing adaptive selection of different numbers and types of conditions. Our approach begins with a double-cycle controller that generates an initial real score sorting for all input conditions by leveraging pre-trained conditional generation models and discriminative models. This controller evaluates the similarity between extracted conditions and input conditions, as well as the pixel-level similarity with the source image. Then, we integrate a Multimodal Large Language Model (MLLM) to build an efficient condition evaluator. This evaluator optimizes the ordering of conditions based on the double-cycle controller's score ranking. Our method jointly optimizes MLLMs and diffusion models, utilizing MLLMs' reasoning capabilities to facilitate multi-condition text-to-image (T2I) tasks. The final sorted conditions are fed into a parallel multi-control adapter, which learns feature maps from dynamic visual conditions and integrates them to modulate ControlNet, thereby enhancing control over generated images. Through both quantitative and qualitative comparisons, DynamicControl demonstrates its superiority over existing methods in terms of controllability, generation quality and composability under various conditional controls.