 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign and Surpass Human Camouflaged Perception: Visual Refocus Reinforcement Fine-Tuning
May 26, 2025

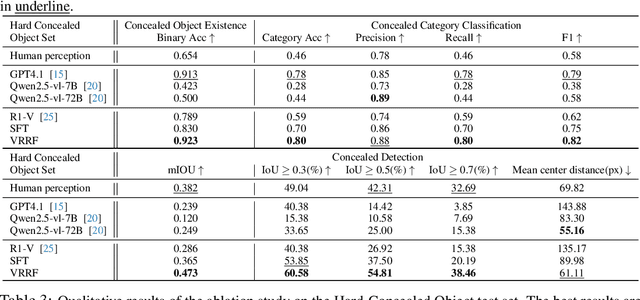

Current multi-modal models exhibit a notable misalignment with the human visual system when identifying objects that are visually assimilated into the background. Our observations reveal that these multi-modal models cannot distinguish concealed objects, demonstrating an inability to emulate human cognitive processes which effectively utilize foreground-background similarity principles for visual analysis. To analyze this hidden human-model visual thinking discrepancy, we build a visual system that mimicks human visual camouflaged perception to progressively and iteratively `refocus' visual concealed content. The refocus is a progressive guidance mechanism enabling models to logically localize objects in visual images through stepwise reasoning. The localization process of concealed objects requires hierarchical attention shifting with dynamic adjustment and refinement of prior cognitive knowledge. In this paper, we propose a visual refocus reinforcement framework via the policy optimization algorithm to encourage multi-modal models to think and refocus more before answering, and achieve excellent reasoning abilities to align and even surpass human camouflaged perception systems. Our extensive experiments on camouflaged perception successfully demonstrate the emergence of refocus visual phenomena, characterized by multiple reasoning tokens and dynamic adjustment of the detection box. Besides, experimental results on both camouflaged object classification and detection tasks exhibit significantly superior performance compared to Supervised Fine-Tuning (SFT) baselines.
Can video generation replace cinematographers? Research on the cinematic language of generated video
Dec 16, 2024



Recent advancements in text-to-video (T2V) generation have leveraged diffusion models to enhance the visual coherence of videos generated from textual descriptions. However, most research has primarily focused on object motion, with limited attention given to cinematic language in videos, which is crucial for cinematographers to convey emotion and narrative pacing. To address this limitation, we propose a threefold approach to enhance the ability of T2V models to generate controllable cinematic language. Specifically, we introduce a cinematic language dataset that encompasses shot framing, angle, and camera movement, enabling models to learn diverse cinematic styles. Building on this, to facilitate robust cinematic alignment evaluation, we present CameraCLIP, a model fine-tuned on the proposed dataset that excels in understanding complex cinematic language in generated videos and can further provide valuable guidance in the multi-shot composition process. Finally, we propose CLIPLoRA, a cost-guided dynamic LoRA composition method that facilitates smooth transitions and realistic blending of cinematic language by dynamically fusing multiple pre-trained cinematic LoRAs within a single video. Our experiments demonstrate that CameraCLIP outperforms existing models in assessing the alignment between cinematic language and video, achieving an R@1 score of 0.81. Additionally, CLIPLoRA improves the ability for multi-shot composition, potentially bridging the gap between automatically generated videos and those shot by professional cinematographers.
VTON-HandFit: Virtual Try-on for Arbitrary Hand Pose Guided by Hand Priors Embedding
Aug 27, 2024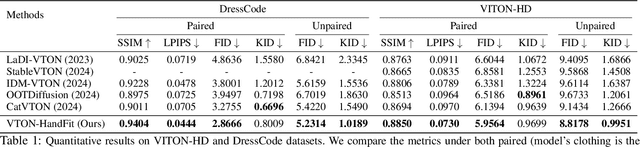
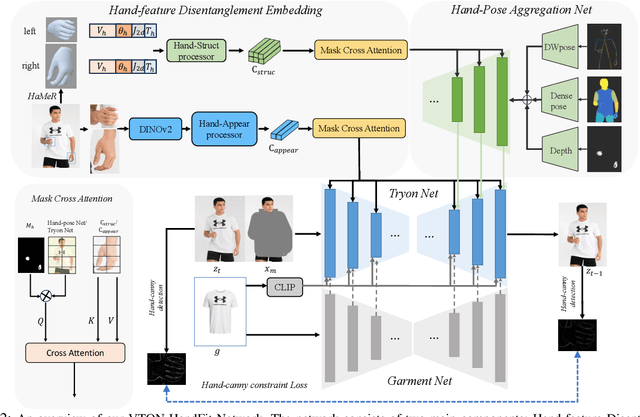


Although diffusion-based image virtual try-on has made considerable progress, emerging approaches still struggle to effectively address the issue of hand occlusion (i.e., clothing regions occluded by the hand part), leading to a notable degradation of the try-on performance. To tackle this issue widely existing in real-world scenarios, we propose VTON-HandFit, leveraging the power of hand priors to reconstruct the appearance and structure for hand occlusion cases. Firstly, we tailor a Handpose Aggregation Net using the ControlNet-based structure explicitly and adaptively encoding the global hand and pose priors. Besides, to fully exploit the hand-related structure and appearance information, we propose Hand-feature Disentanglement Embedding module to disentangle the hand priors into the hand structure-parametric and visual-appearance features, and customize a masked cross attention for further decoupled feature embedding. Lastly, we customize a hand-canny constraint loss to better learn the structure edge knowledge from the hand template of model image. VTON-HandFit outperforms the baselines in qualitative and quantitative evaluations on the public dataset and our self-collected hand-occlusion Handfit-3K dataset particularly for the arbitrary hand pose occlusion cases in real-world scenarios. The Code and dataset will be available at \url{https://github.com/VTON-HandFit/VTON-HandFit}.