 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeployability-Centric Infrastructure-as-Code Generation: An LLM-based Iterative Framework
Jun 05, 2025Infrastructure-as-Code (IaC) generation holds significant promise for automating cloud infrastructure provisioning. Recent advances in Large Language Models (LLMs) present a promising opportunity to democratize IaC development by generating deployable infrastructure templates from natural language descriptions, but current evaluation focuses on syntactic correctness while ignoring deployability, the fatal measure of IaC template utility. We address this gap through two contributions: (1) IaCGen, an LLM-based deployability-centric framework that uses iterative feedback mechanism to generate IaC templates, and (2) DPIaC-Eval, a deployability-centric IaC template benchmark consists of 153 real-world scenarios that can evaluate syntax, deployment, user intent, and security. Our evaluation reveals that state-of-the-art LLMs initially performed poorly, with Claude-3.5 and Claude-3.7 achieving only 30.2% and 26.8% deployment success on the first attempt respectively. However, IaCGen transforms this performance dramatically: all evaluated models reach over 90% passItr@25, with Claude-3.5 and Claude-3.7 achieving 98% success rate. Despite these improvements, critical challenges remain in user intent alignment (25.2% accuracy) and security compliance (8.4% pass rate), highlighting areas requiring continued research. Our work provides the first comprehensive assessment of deployability-centric IaC template generation and establishes a foundation for future research.
Align and Surpass Human Camouflaged Perception: Visual Refocus Reinforcement Fine-Tuning
May 26, 2025

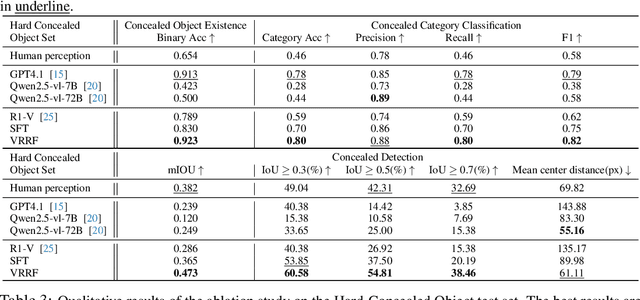

Current multi-modal models exhibit a notable misalignment with the human visual system when identifying objects that are visually assimilated into the background. Our observations reveal that these multi-modal models cannot distinguish concealed objects, demonstrating an inability to emulate human cognitive processes which effectively utilize foreground-background similarity principles for visual analysis. To analyze this hidden human-model visual thinking discrepancy, we build a visual system that mimicks human visual camouflaged perception to progressively and iteratively `refocus' visual concealed content. The refocus is a progressive guidance mechanism enabling models to logically localize objects in visual images through stepwise reasoning. The localization process of concealed objects requires hierarchical attention shifting with dynamic adjustment and refinement of prior cognitive knowledge. In this paper, we propose a visual refocus reinforcement framework via the policy optimization algorithm to encourage multi-modal models to think and refocus more before answering, and achieve excellent reasoning abilities to align and even surpass human camouflaged perception systems. Our extensive experiments on camouflaged perception successfully demonstrate the emergence of refocus visual phenomena, characterized by multiple reasoning tokens and dynamic adjustment of the detection box. Besides, experimental results on both camouflaged object classification and detection tasks exhibit significantly superior performance compared to Supervised Fine-Tuning (SFT) baselines.
Skip-Thinking: Chunk-wise Chain-of-Thought Distillation Enable Smaller Language Models to Reason Better and Faster
May 24, 2025Chain-of-thought (CoT) distillation allows a large language model (LLM) to guide a small language model (SLM) in reasoning tasks. Existing methods train the SLM to learn the long rationale in one iteration, resulting in two issues: 1) Long rationales lead to a large token-level batch size during training, making gradients of core reasoning tokens (i.e., the token will directly affect the correctness of subsequent reasoning) over-smoothed as they contribute a tiny fraction of the rationale. As a result, the SLM converges to sharp minima where it fails to grasp the reasoning logic. 2) The response is slow, as the SLM must generate a long rationale before reaching the answer. Therefore, we propose chunk-wise training (CWT), which uses a heuristic search to divide the rationale into internal semantically coherent chunks and focuses SLM on learning from only one chunk per iteration. In this way, CWT naturally isolates non-reasoning chunks that do not involve the core reasoning token (e.g., summary and transitional chunks) from the SLM learning for reasoning chunks, making the fraction of the core reasoning token increase in the corresponding iteration. Based on CWT, skip-thinking training (STT) is proposed. STT makes the SLM automatically skip non-reasoning medium chunks to reach the answer, improving reasoning speed while maintaining accuracy. We validate our approach on a variety of SLMs and multiple reasoning tasks.
On Quantum Perceptron Learning via Quantum Search
Mar 21, 2025With the growing interest in quantum machine learning, the perceptron -- a fundamental building block in traditional machine learning -- has emerged as a valuable model for exploring quantum advantages. Two quantum perceptron algorithms based on Grover's search, were developed in arXiv:1602.04799 to accelerate training and improve statistical efficiency in perceptron learning. This paper points out and corrects a mistake in the proof of Theorem 2 in arXiv:1602.04799. Specifically, we show that the probability of sampling from a normal distribution for a $D$-dimensional hyperplane that perfectly classifies the data scales as $\Omega(\gamma^{D})$ instead of $\Theta({\gamma})$, where $\gamma$ is the margin. We then revisit two well-established linear programming algorithms -- the ellipsoid method and the cutting plane random walk algorithm -- in the context of perceptron learning, and show how quantum search algorithms can be leveraged to enhance the overall complexity. Specifically, both algorithms gain a sub-linear speed-up $O(\sqrt{N})$ in the number of data points $N$ as a result of Grover's algorithm and an additional $O(D^{1.5})$ speed-up is possible for cutting plane random walk algorithm employing quantum walk search.
Neural Architecture Search of Hybrid Models for NPU-CIM Heterogeneous AR/VR Devices
Oct 10, 2024
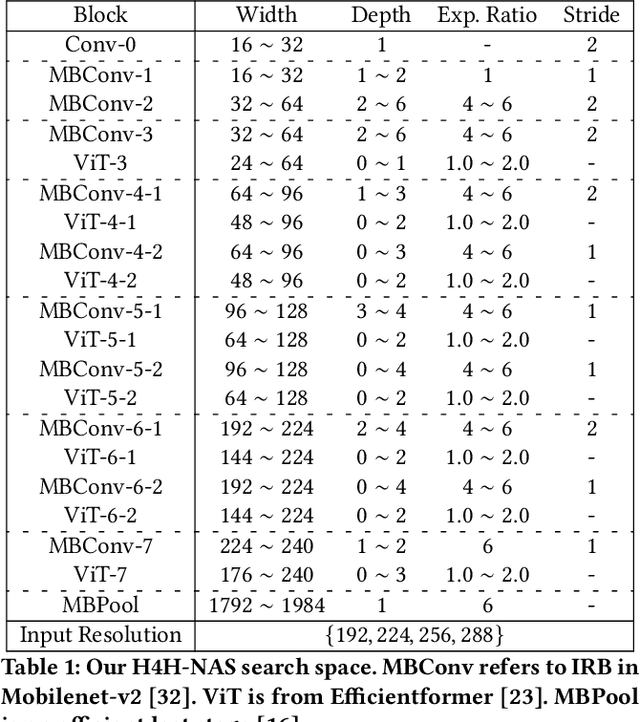
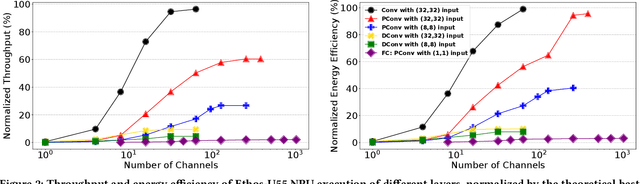
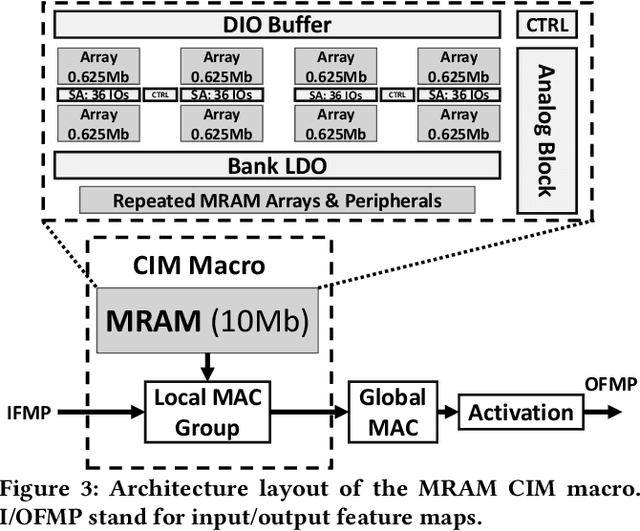
Low-Latency and Low-Power Edge AI is essential for Virtual Reality and Augmented Reality applications. Recent advances show that hybrid models, combining convolution layers (CNN) and transformers (ViT), often achieve superior accuracy/performance tradeoff on various computer vision and machine learning (ML) tasks. However, hybrid ML models can pose system challenges for latency and energy-efficiency due to their diverse nature in dataflow and memory access patterns. In this work, we leverage the architecture heterogeneity from Neural Processing Units (NPU) and Compute-In-Memory (CIM) and perform diverse execution schemas to efficiently execute these hybrid models. We also introduce H4H-NAS, a Neural Architecture Search framework to design efficient hybrid CNN/ViT models for heterogeneous edge systems with both NPU and CIM. Our H4H-NAS approach is powered by a performance estimator built with NPU performance results measured on real silicon, and CIM performance based on industry IPs. H4H-NAS searches hybrid CNN/ViT models with fine granularity and achieves significant (up to 1.34%) top-1 accuracy improvement on ImageNet dataset. Moreover, results from our Algo/HW co-design reveal up to 56.08% overall latency and 41.72% energy improvements by introducing such heterogeneous computing over baseline solutions. The framework guides the design of hybrid network architectures and system architectures of NPU+CIM heterogeneous systems.
LMDX: Language Model-based Document Information Extraction and Localization
Sep 19, 2023


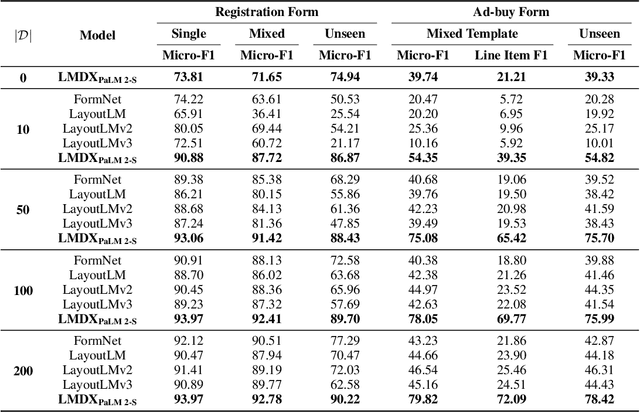
Large Language Models (LLM) have revolutionized Natural Language Processing (NLP), improving state-of-the-art on many existing tasks and exhibiting emergent capabilities. However, LLMs have not yet been successfully applied on semi-structured document information extraction, which is at the core of many document processing workflows and consists of extracting key entities from a visually rich document (VRD) given a predefined target schema. The main obstacles to LLM adoption in that task have been the absence of layout encoding within LLMs, critical for a high quality extraction, and the lack of a grounding mechanism ensuring the answer is not hallucinated. In this paper, we introduce Language Model-based Document Information Extraction and Localization (LMDX), a methodology to adapt arbitrary LLMs for document information extraction. LMDX can do extraction of singular, repeated, and hierarchical entities, both with and without training data, while providing grounding guarantees and localizing the entities within the document. In particular, we apply LMDX to the PaLM 2-S LLM and evaluate it on VRDU and CORD benchmarks, setting a new state-of-the-art and showing how LMDX enables the creation of high quality, data-efficient parsers.
Document Entity Retrieval with Massive and Noisy Pre-training
Jun 15, 2023



Visually-Rich Document Entity Retrieval (VDER) is a type of machine learning task that aims at recovering text spans in the documents for each of the entities in question. VDER has gained significant attention in recent years thanks to its broad applications in enterprise AI. Unfortunately, as document images often contain personally identifiable information (PII), publicly available data have been scarce, not only because of privacy constraints but also the costs of acquiring annotations. To make things worse, each dataset would often define its own sets of entities, and the non-overlapping entity spaces between datasets make it difficult to transfer knowledge between documents. In this paper, we propose a method to collect massive-scale, noisy, and weakly labeled data from the web to benefit the training of VDER models. Such a method will generate a huge amount of document image data to compensate for the lack of training data in many VDER settings. Moreover, the collected dataset named DocuNet would not need to be dependent on specific document types or entity sets, making it universally applicable to all VDER tasks. Empowered by DocuNet, we present a lightweight multimodal architecture named UniFormer, which can learn a unified representation from text, layout, and image crops without needing extra visual pertaining. We experiment with our methods on popular VDER models in various settings and show the improvements when this massive dataset is incorporated with UniFormer on both classic entity retrieval and few-shot learning settings.
Spectral Efficiency and Scalability Analysis for Multi-Level Cooperative Cell-Free Massive MIMO Systems
Feb 16, 2023


This paper proposes a multi-level cooperative architecture to balance the spectral efficiency and scalability of cell-free massive multiple-input multiple-output (MIMO) systems. In the proposed architecture, spatial expansion units (SEUs) are introduced to avoid a large amount of computation at the access points (APs) and increase the degree of cooperation among APs. We first derive the closed-form expressions of the uplink user achievable rates under multi-level cooperative architecture with maximal ratio combination (MRC) and zero-forcing (ZF) receivers. The accuracy of the closed-form expressions is verified. Moreover, numerical results have demonstrated that the proposed multi-level cooperative architecture achieves a better trade-off between spectral efficiency and scalability than other forms of cell-free massive MIMO architectures.
Recent Advances for Quantum Neural Networks in Generative Learning
Jun 07, 2022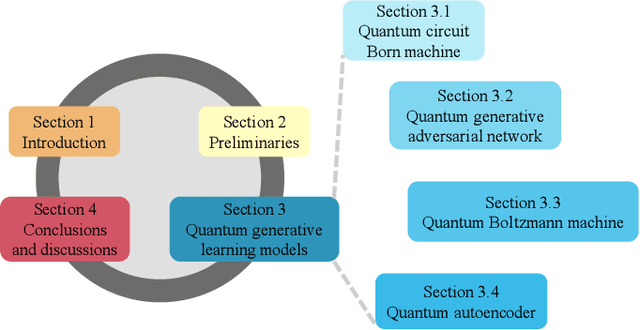

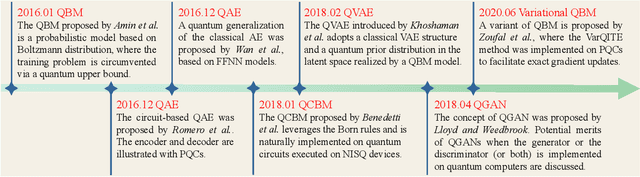
Quantum computers are next-generation devices that hold promise to perform calculations beyond the reach of classical computers. A leading method towards achieving this goal is through quantum machine learning, especially quantum generative learning. Due to the intrinsic probabilistic nature of quantum mechanics, it is reasonable to postulate that quantum generative learning models (QGLMs) may surpass their classical counterparts. As such, QGLMs are receiving growing attention from the quantum physics and computer science communities, where various QGLMs that can be efficiently implemented on near-term quantum machines with potential computational advantages are proposed. In this paper, we review the current progress of QGLMs from the perspective of machine learning. Particularly, we interpret these QGLMs, covering quantum circuit born machines, quantum generative adversarial networks, quantum Boltzmann machines, and quantum autoencoders, as the quantum extension of classical generative learning models. In this context, we explore their intrinsic relation and their fundamental differences. We further summarize the potential applications of QGLMs in both conventional machine learning tasks and quantum physics. Last, we discuss the challenges and further research directions for QGLMs.
ACED: Accelerated Computational Electrochemical systems Discovery
Nov 10, 2020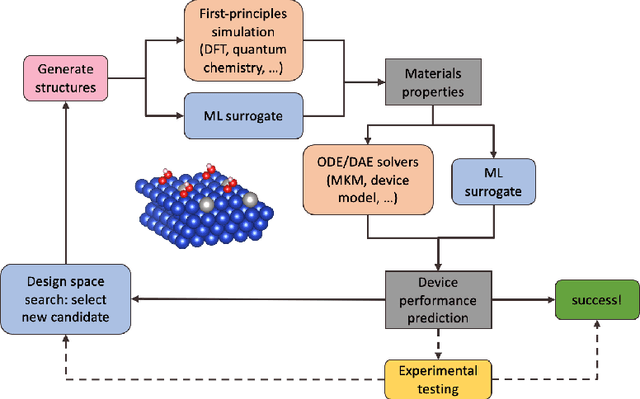
Large-scale electrification is vital to addressing the climate crisis, but many engineering challenges remain to fully electrifying both the chemical industry and transportation. In both of these areas, new electrochemical materials and systems will be critical, but developing these systems currently relies heavily on computationally expensive first-principles simulations as well as human-time-intensive experimental trial and error. We propose to develop an automated workflow that accelerates these computational steps by introducing both automated error handling in generating the first-principles training data as well as physics-informed machine learning surrogates to further reduce computational cost. It will also have the capacity to include automated experiments "in the loop" in order to dramatically accelerate the overall materials discovery pipeline.