 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodecLM: Aligning Language Models with Tailored Synthetic Data
Apr 08, 2024



Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Document Entity Retrieval with Massive and Noisy Pre-training
Jun 15, 2023



Visually-Rich Document Entity Retrieval (VDER) is a type of machine learning task that aims at recovering text spans in the documents for each of the entities in question. VDER has gained significant attention in recent years thanks to its broad applications in enterprise AI. Unfortunately, as document images often contain personally identifiable information (PII), publicly available data have been scarce, not only because of privacy constraints but also the costs of acquiring annotations. To make things worse, each dataset would often define its own sets of entities, and the non-overlapping entity spaces between datasets make it difficult to transfer knowledge between documents. In this paper, we propose a method to collect massive-scale, noisy, and weakly labeled data from the web to benefit the training of VDER models. Such a method will generate a huge amount of document image data to compensate for the lack of training data in many VDER settings. Moreover, the collected dataset named DocuNet would not need to be dependent on specific document types or entity sets, making it universally applicable to all VDER tasks. Empowered by DocuNet, we present a lightweight multimodal architecture named UniFormer, which can learn a unified representation from text, layout, and image crops without needing extra visual pertaining. We experiment with our methods on popular VDER models in various settings and show the improvements when this massive dataset is incorporated with UniFormer on both classic entity retrieval and few-shot learning settings.
Cross-layer Optimization for High Speed Adders: A Pareto Driven Machine Learning Approach
Oct 16, 2018
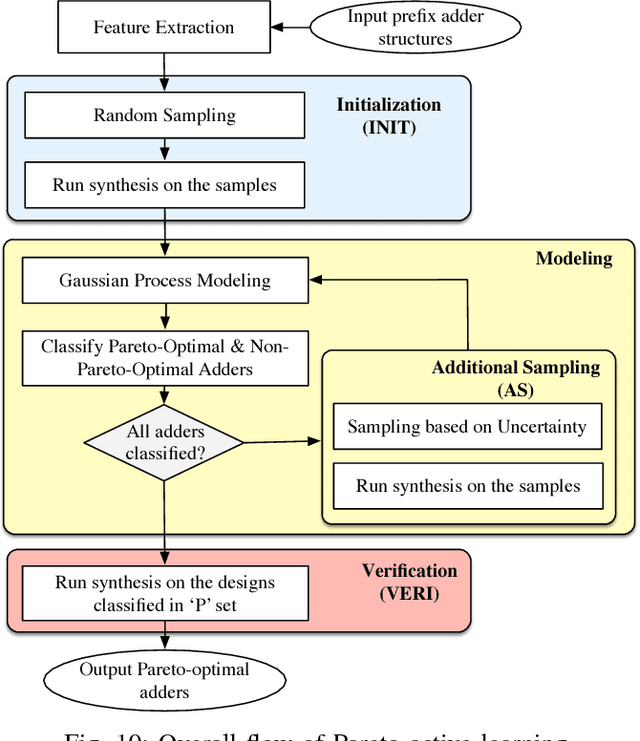
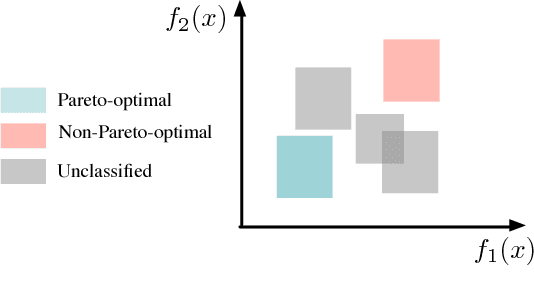
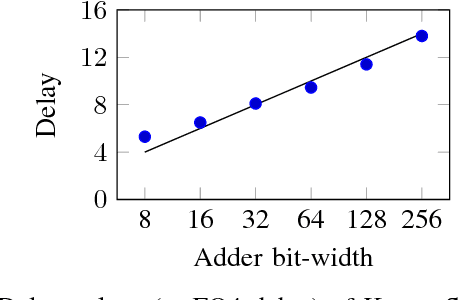
In spite of maturity to the modern electronic design automation (EDA) tools, optimized designs at architectural stage may become sub-optimal after going through physical design flow. Adder design has been such a long studied fundamental problem in VLSI industry yet designers cannot achieve optimal solutions by running EDA tools on the set of available prefix adder architectures. In this paper, we enhance a state-of-the-art prefix adder synthesis algorithm to obtain a much wider solution space in architectural domain. On top of that, a machine learning-based design space exploration methodology is applied to predict the Pareto frontier of the adders in physical domain, which is infeasible by exhaustively running EDA tools for innumerable architectural solutions. Considering the high cost of obtaining the true values for learning, an active learning algorithm is utilized to select the representative data during learning process, which uses less labeled data while achieving better quality of Pareto frontier. Experimental results demonstrate that our framework can achieve Pareto frontier of high quality over a wide design space, bridging the gap between architectural and physical designs.