 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input
Jan 06, 2025



We introduce FACTS Grounding, an online leaderboard and associated benchmark that evaluates language models' ability to generate text that is factually accurate with respect to given context in the user prompt. In our benchmark, each prompt includes a user request and a full document, with a maximum length of 32k tokens, requiring long-form responses. The long-form responses are required to be fully grounded in the provided context document while fulfilling the user request. Models are evaluated using automated judge models in two phases: (1) responses are disqualified if they do not fulfill the user request; (2) they are judged as accurate if the response is fully grounded in the provided document. The automated judge models were comprehensively evaluated against a held-out test-set to pick the best prompt template, and the final factuality score is an aggregate of multiple judge models to mitigate evaluation bias. The FACTS Grounding leaderboard will be actively maintained over time, and contains both public and private splits to allow for external participation while guarding the integrity of the leaderboard. It can be found at https://www.kaggle.com/facts-leaderboard.
RAGChecker: A Fine-grained Framework for Diagnosing Retrieval-Augmented Generation
Aug 15, 2024



Despite Retrieval-Augmented Generation (RAG) has shown promising capability in leveraging external knowledge, a comprehensive evaluation of RAG systems is still challenging due to the modular nature of RAG, evaluation of long-form responses and reliability of measurements. In this paper, we propose a fine-grained evaluation framework, RAGChecker, that incorporates a suite of diagnostic metrics for both the retrieval and generation modules. Meta evaluation verifies that RAGChecker has significantly better correlations with human judgments than other evaluation metrics. Using RAGChecker, we evaluate 8 RAG systems and conduct an in-depth analysis of their performance, revealing insightful patterns and trade-offs in the design choices of RAG architectures. The metrics of RAGChecker can guide researchers and practitioners in developing more effective RAG systems.
OpenResearcher: Unleashing AI for Accelerated Scientific Research
Aug 13, 2024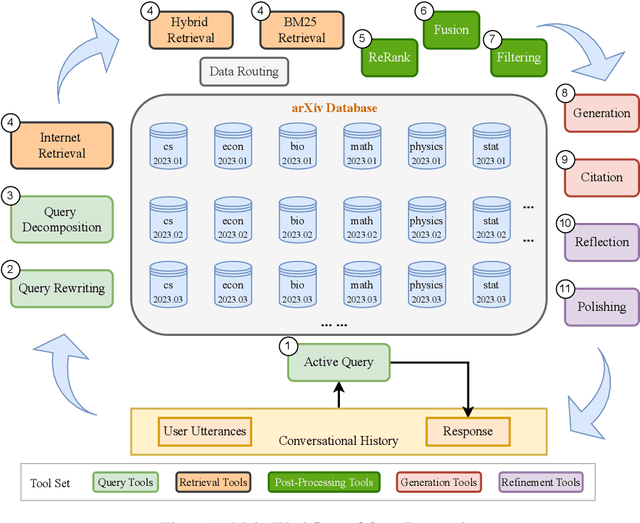
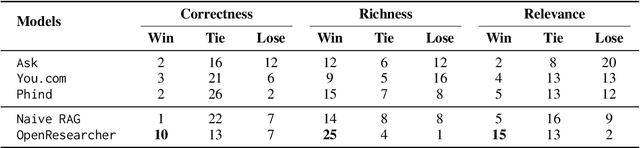
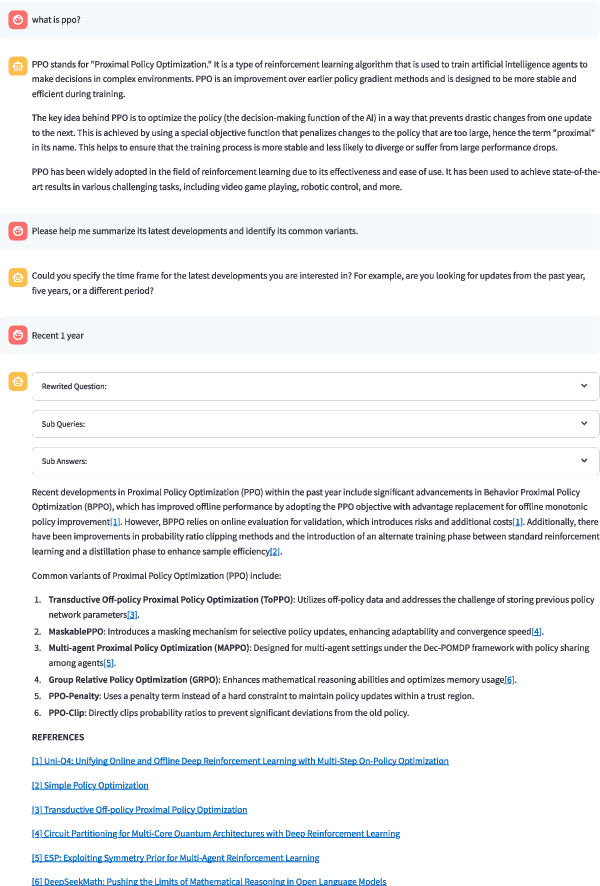
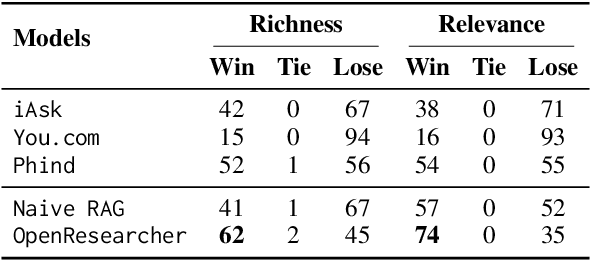
The rapid growth of scientific literature imposes significant challenges for researchers endeavoring to stay updated with the latest advancements in their fields and delve into new areas. We introduce OpenResearcher, an innovative platform that leverages Artificial Intelligence (AI) techniques to accelerate the research process by answering diverse questions from researchers. OpenResearcher is built based on Retrieval-Augmented Generation (RAG) to integrate Large Language Models (LLMs) with up-to-date, domain-specific knowledge. Moreover, we develop various tools for OpenResearcher to understand researchers' queries, search from the scientific literature, filter retrieved information, provide accurate and comprehensive answers, and self-refine these answers. OpenResearcher can flexibly use these tools to balance efficiency and effectiveness. As a result, OpenResearcher enables researchers to save time and increase their potential to discover new insights and drive scientific breakthroughs. Demo, video, and code are available at: https://github.com/GAIR-NLP/OpenResearcher.
4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs
Apr 28, 2024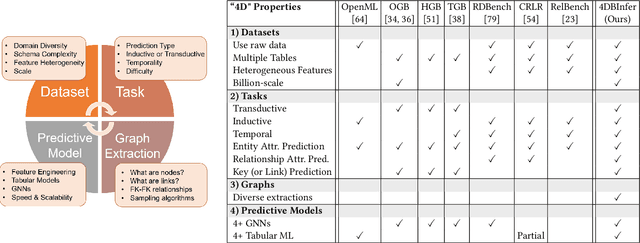
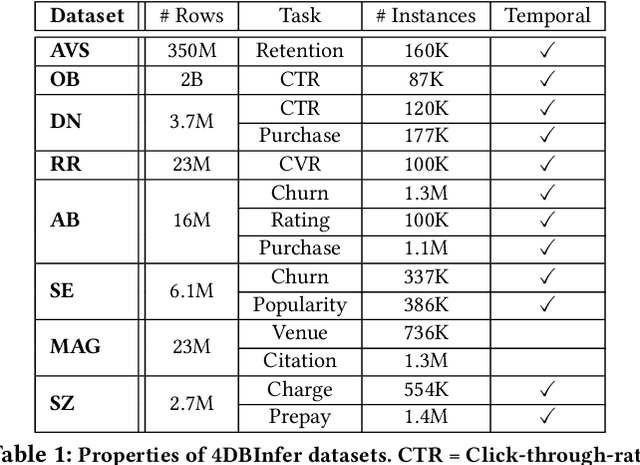
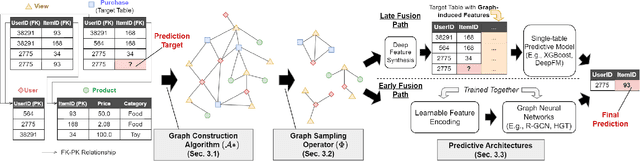
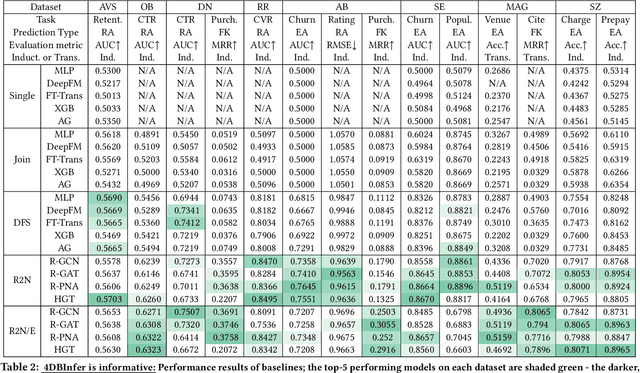
Although RDBs store vast amounts of rich, informative data spread across interconnected tables, the progress of predictive machine learning models as applied to such tasks arguably falls well behind advances in other domains such as computer vision or natural language processing. This deficit stems, at least in part, from the lack of established/public RDB benchmarks as needed for training and evaluation purposes. As a result, related model development thus far often defaults to tabular approaches trained on ubiquitous single-table benchmarks, or on the relational side, graph-based alternatives such as GNNs applied to a completely different set of graph datasets devoid of tabular characteristics. To more precisely target RDBs lying at the nexus of these two complementary regimes, we explore a broad class of baseline models predicated on: (i) converting multi-table datasets into graphs using various strategies equipped with efficient subsampling, while preserving tabular characteristics; and (ii) trainable models with well-matched inductive biases that output predictions based on these input subgraphs. Then, to address the dearth of suitable public benchmarks and reduce siloed comparisons, we assemble a diverse collection of (i) large-scale RDB datasets and (ii) coincident predictive tasks. From a delivery standpoint, we operationalize the above four dimensions (4D) of exploration within a unified, scalable open-source toolbox called 4DBInfer. We conclude by presenting evaluations using 4DBInfer, the results of which highlight the importance of considering each such dimension in the design of RDB predictive models, as well as the limitations of more naive approaches such as simply joining adjacent tables. Our source code is released at https://github.com/awslabs/multi-table-benchmark .
CodecLM: Aligning Language Models with Tailored Synthetic Data
Apr 08, 2024



Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
RDBench: ML Benchmark for Relational Databases
Oct 30, 2023Benefiting from high-quality datasets and standardized evaluation metrics, machine learning (ML) has achieved sustained progress and widespread applications. However, while applying machine learning to relational databases (RDBs), the absence of a well-established benchmark remains a significant obstacle to the development of ML. To address this issue, we introduce ML Benchmark For Relational Databases (RDBench), a standardized benchmark that aims to promote reproducible ML research on RDBs that include multiple tables. RDBench offers diverse RDB datasets of varying scales, domains, and relational structures, organized into 4 levels. Notably, to simplify the adoption of RDBench for diverse ML domains, for any given database, RDBench exposes three types of interfaces including tabular data, homogeneous graphs, and heterogeneous graphs, sharing the same underlying task definition. For the first time, RDBench enables meaningful comparisons between ML methods from diverse domains, ranging from XGBoost to Graph Neural Networks, under RDB prediction tasks. We design multiple classification and regression tasks for each RDB dataset and report averaged results over the same dataset, further enhancing the robustness of the experimental findings. RDBench is implemented with DBGym, a user-friendly platform for ML research and application on databases, enabling benchmarking new ML methods with RDBench at ease.
ScalableMap: Scalable Map Learning for Online Long-Range Vectorized HD Map Construction
Oct 20, 2023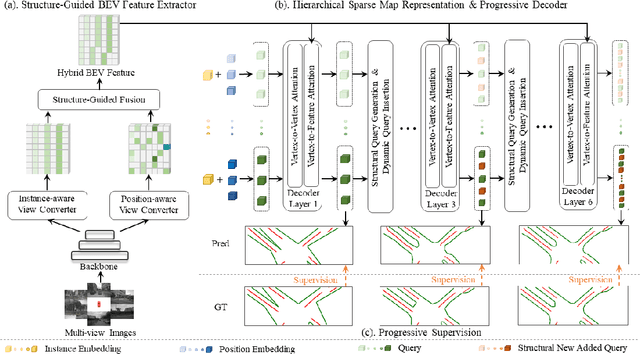
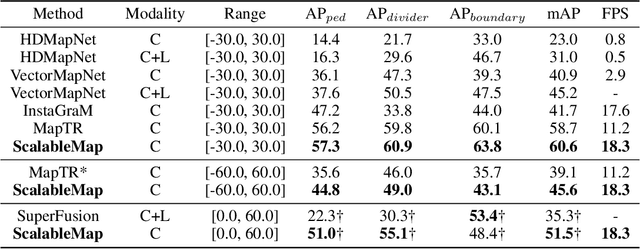
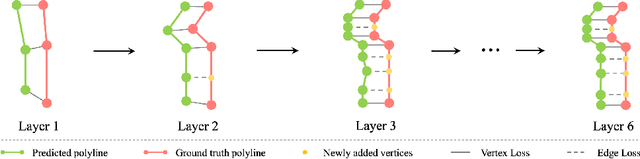

We propose a novel end-to-end pipeline for online long-range vectorized high-definition (HD) map construction using on-board camera sensors. The vectorized representation of HD maps, employing polylines and polygons to represent map elements, is widely used by downstream tasks. However, previous schemes designed with reference to dynamic object detection overlook the structural constraints within linear map elements, resulting in performance degradation in long-range scenarios. In this paper, we exploit the properties of map elements to improve the performance of map construction. We extract more accurate bird's eye view (BEV) features guided by their linear structure, and then propose a hierarchical sparse map representation to further leverage the scalability of vectorized map elements and design a progressive decoding mechanism and a supervision strategy based on this representation. Our approach, ScalableMap, demonstrates superior performance on the nuScenes dataset, especially in long-range scenarios, surpassing previous state-of-the-art model by 6.5 mAP while achieving 18.3 FPS. Code is available at https://github.com/jingy1yu/ScalableMap.
Metaheuristic Algorithms in Artificial Intelligence with Applications to Bioinformatics, Biostatistics, Ecology and, the Manufacturing Industries
Aug 08, 2023Nature-inspired metaheuristic algorithms are important components of artificial intelligence, and are increasingly used across disciplines to tackle various types of challenging optimization problems. We apply a newly proposed nature-inspired metaheuristic algorithm called competitive swarm optimizer with mutated agents (CSO-MA) and demonstrate its flexibility and out-performance relative to its competitors in a variety of optimization problems in the statistical sciences. In particular, we show the algorithm is efficient and can incorporate various cost structures or multiple user-specified nonlinear constraints. Our applications include (i) finding maximum likelihood estimates of parameters in a single cell generalized trend model to study pseudotime in bioinformatics, (ii) estimating parameters in a commonly used Rasch model in education research, (iii) finding M-estimates for a Cox regression in a Markov renewal model and (iv) matrix completion to impute missing values in a two compartment model. In addition we discuss applications to (v) select variables optimally in an ecology problem and (vi) design a car refueling experiment for the auto industry using a logistic model with multiple interacting factors.
Steering Prototype with Prompt-tuning for Rehearsal-free Continual Learning
Mar 16, 2023



Prototype, as a representation of class embeddings, has been explored to reduce memory footprint or mitigate forgetting for continual learning scenarios. However, prototype-based methods still suffer from abrupt performance deterioration due to semantic drift and prototype interference. In this study, we propose Contrastive Prototypical Prompt (CPP) and show that task-specific prompt-tuning, when optimized over a contrastive learning objective, can effectively address both obstacles and significantly improve the potency of prototypes. Our experiments demonstrate that CPP excels in four challenging class-incremental learning benchmarks, resulting in 4% to 6% absolute improvements over state-of-the-art methods. Moreover, CPP does not require a rehearsal buffer and it largely bridges the performance gap between continual learning and offline joint-learning, showcasing a promising design scheme for continual learning systems under a Transformer architecture.