 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilDeep: Learning Large Deformations of Elastic-Plastic Solids with Multi-Fidelity Data
Jan 15, 2026The scientific computation of large deformations in elastic-plastic solids is crucial in various manufacturing applications. Traditional numerical methods exhibit several inherent limitations, prompting Deep Learning (DL) as a promising alternative. The effectiveness of current DL techniques typically depends on the availability of high-quantity and high-accuracy datasets, which are yet difficult to obtain in large deformation problems. During the dataset construction process, a dilemma stands between data quantity and data accuracy, leading to suboptimal performance in the DL models. To address this challenge, we focus on a representative application of large deformations, the stretch bending problem, and propose FilDeep, a Fidelity-based Deep Learning framework for large Deformation of elastic-plastic solids. Our FilDeep aims to resolve the quantity-accuracy dilemma by simultaneously training with both low-fidelity and high-fidelity data, where the former provides greater quantity but lower accuracy, while the latter offers higher accuracy but in less quantity. In FilDeep, we provide meticulous designs for the practical large deformation problem. Particularly, we propose attention-enabled cross-fidelity modules to effectively capture long-range physical interactions across MF data. To the best of our knowledge, our FilDeep presents the first DL framework for large deformation problems using MF data. Extensive experiments demonstrate that our FilDeep consistently achieves state-of-the-art performance and can be efficiently deployed in manufacturing.
BDD2Seq: Enabling Scalable Reversible-Circuit Synthesis via Graph-to-Sequence Learning
Nov 11, 2025Binary Decision Diagrams (BDDs) are instrumental in many electronic design automation (EDA) tasks thanks to their compact representation of Boolean functions. In BDD-based reversible-circuit synthesis, which is critical for quantum computing, the chosen variable ordering governs the number of BDD nodes and thus the key metrics of resource consumption, such as Quantum Cost. Because finding an optimal variable ordering for BDDs is an NP-complete problem, existing heuristics often degrade as circuit complexity grows. We introduce BDD2Seq, a graph-to-sequence framework that couples a Graph Neural Network encoder with a Pointer-Network decoder and Diverse Beam Search to predict high-quality orderings. By treating the circuit netlist as a graph, BDD2Seq learns structural dependencies that conventional heuristics overlooked, yielding smaller BDDs and faster synthesis. Extensive experiments on three public benchmarks show that BDD2Seq achieves around 1.4 times lower Quantum Cost and 3.7 times faster synthesis than modern heuristic algorithms. To the best of our knowledge, this is the first work to tackle the variable-ordering problem in BDD-based reversible-circuit synthesis with a graph-based generative model and diversity-promoting decoding.
How does Misinformation Affect Large Language Model Behaviors and Preferences?
May 27, 2025Large Language Models (LLMs) have shown remarkable capabilities in knowledge-intensive tasks, while they remain vulnerable when encountering misinformation. Existing studies have explored the role of LLMs in combating misinformation, but there is still a lack of fine-grained analysis on the specific aspects and extent to which LLMs are influenced by misinformation. To bridge this gap, we present MisBench, the current largest and most comprehensive benchmark for evaluating LLMs' behavior and knowledge preference toward misinformation. MisBench consists of 10,346,712 pieces of misinformation, which uniquely considers both knowledge-based conflicts and stylistic variations in misinformation. Empirical results reveal that while LLMs demonstrate comparable abilities in discerning misinformation, they still remain susceptible to knowledge conflicts and stylistic variations. Based on these findings, we further propose a novel approach called Reconstruct to Discriminate (RtD) to strengthen LLMs' ability to detect misinformation. Our study provides valuable insights into LLMs' interactions with misinformation, and we believe MisBench can serve as an effective benchmark for evaluating LLM-based detectors and enhancing their reliability in real-world applications. Codes and data are available at https://github.com/GKNL/MisBench.
ACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
May 18, 2025The development of artificial intelligence demands that models incrementally update knowledge by Continual Learning (CL) to adapt to open-world environments. To meet privacy and security requirements, Continual Unlearning (CU) emerges as an important problem, aiming to sequentially forget particular knowledge acquired during the CL phase. However, existing unlearning methods primarily focus on single-shot joint forgetting and face significant limitations when applied to CU. First, most existing methods require access to the retained dataset for re-training or fine-tuning, violating the inherent constraint in CL that historical data cannot be revisited. Second, these methods often suffer from a poor trade-off between system efficiency and model fidelity, making them vulnerable to being overwhelmed or degraded by adversaries through deliberately frequent requests. In this paper, we identify that the limitations of existing unlearning methods stem fundamentally from their reliance on gradient-based updates. To bridge the research gap at its root, we propose a novel gradient-free method for CU, named Analytic Continual Unlearning (ACU), for efficient and exact forgetting with historical data privacy preservation. In response to each unlearning request, our ACU recursively derives an analytical (i.e., closed-form) solution in an interpretable manner using the least squares method. Theoretical and experimental evaluations validate the superiority of our ACU on unlearning effectiveness, model fidelity, and system efficiency.
AFCL: Analytic Federated Continual Learning for Spatio-Temporal Invariance of Non-IID Data
May 18, 2025Federated Continual Learning (FCL) enables distributed clients to collaboratively train a global model from online task streams in dynamic real-world scenarios. However, existing FCL methods face challenges of both spatial data heterogeneity among distributed clients and temporal data heterogeneity across online tasks. Such data heterogeneity significantly degrades the model performance with severe spatial-temporal catastrophic forgetting of local and past knowledge. In this paper, we identify that the root cause of this issue lies in the inherent vulnerability and sensitivity of gradients to non-IID data. To fundamentally address this issue, we propose a gradient-free method, named Analytic Federated Continual Learning (AFCL), by deriving analytical (i.e., closed-form) solutions from frozen extracted features. In local training, our AFCL enables single-epoch learning with only a lightweight forward-propagation process for each client. In global aggregation, the server can recursively and efficiently update the global model with single-round aggregation. Theoretical analyses validate that our AFCL achieves spatio-temporal invariance of non-IID data. This ideal property implies that, regardless of how heterogeneous the data are distributed across local clients and online tasks, the aggregated model of our AFCL remains invariant and identical to that of centralized joint learning. Extensive experiments show the consistent superiority of our AFCL over state-of-the-art baselines across various benchmark datasets and settings.
ZeroTuning: Unlocking the Initial Token's Power to Enhance Large Language Models Without Training
May 16, 2025Recently, training-free methods for improving large language models (LLMs) have attracted growing interest, with token-level attention tuning emerging as a promising and interpretable direction. However, existing methods typically rely on auxiliary mechanisms to identify important or irrelevant task-specific tokens, introducing potential bias and limiting applicability. In this paper, we uncover a surprising and elegant alternative: the semantically empty initial token is a powerful and underexplored control point for optimizing model behavior. Through theoretical analysis, we show that tuning the initial token's attention sharpens or flattens the attention distribution over subsequent tokens, and its role as an attention sink amplifies this effect. Empirically, we find that: (1) tuning its attention improves LLM performance more effectively than tuning other task-specific tokens; (2) the effect follows a consistent trend across layers, with earlier layers having greater impact, but varies across attention heads, with different heads showing distinct preferences in how they attend to this token. Based on these findings, we propose ZeroTuning, a training-free approach that improves LLM performance by applying head-specific attention adjustments to this special token. Despite tuning only one token, ZeroTuning achieves higher performance on text classification, multiple-choice, and multi-turn conversation tasks across models such as Llama, Qwen, and DeepSeek. For example, ZeroTuning improves Llama-3.1-8B by 11.71% on classification, 2.64% on QA tasks, and raises its multi-turn score from 7.804 to 7.966. The method is also robust to limited resources, few-shot settings, long contexts, quantization, decoding strategies, and prompt variations. Our work sheds light on a previously overlooked control point in LLMs, offering new insights into both inference-time tuning and model interpretability.
Can LLMs handle WebShell detection? Overcoming Detection Challenges with Behavioral Function-Aware Framework
Apr 14, 2025WebShell attacks, in which malicious scripts are injected into web servers, are a major cybersecurity threat. Traditional machine learning and deep learning methods are hampered by issues such as the need for extensive training data, catastrophic forgetting, and poor generalization. Recently, Large Language Models (LLMs) have gained attention for code-related tasks, but their potential in WebShell detection remains underexplored. In this paper, we make two major contributions: (1) a comprehensive evaluation of seven LLMs, including GPT-4, LLaMA 3.1 70B, and Qwen 2.5 variants, benchmarked against traditional sequence- and graph-based methods using a dataset of 26.59K PHP scripts, and (2) the Behavioral Function-Aware Detection (BFAD) framework, designed to address the specific challenges of applying LLMs to this domain. Our framework integrates three components: a Critical Function Filter that isolates malicious PHP function calls, a Context-Aware Code Extraction strategy that captures the most behaviorally indicative code segments, and Weighted Behavioral Function Profiling (WBFP) that enhances in-context learning by prioritizing the most relevant demonstrations based on discriminative function-level profiles. Our results show that larger LLMs achieve near-perfect precision but lower recall, while smaller models exhibit the opposite trade-off. However, all models lag behind previous State-Of-The-Art (SOTA) methods. With BFAD, the performance of all LLMs improved, with an average F1 score increase of 13.82%. Larger models such as GPT-4, LLaMA 3.1 70B, and Qwen 2.5 14B outperform SOTA methods, while smaller models such as Qwen 2.5 3B achieve performance competitive with traditional methods. This work is the first to explore the feasibility and limitations of LLMs for WebShell detection, and provides solutions to address the challenges in this task.
SegACIL: Solving the Stability-Plasticity Dilemma in Class-Incremental Semantic Segmentation
Dec 14, 2024While deep learning has made remarkable progress in recent years, models continue to struggle with catastrophic forgetting when processing continuously incoming data. This issue is particularly critical in continual learning, where the balance between retaining prior knowledge and adapting to new information-known as the stability-plasticity dilemma-remains a significant challenge. In this paper, we propose SegACIL, a novel continual learning method for semantic segmentation based on a linear closed-form solution. Unlike traditional methods that require multiple epochs for training, SegACIL only requires a single epoch, significantly reducing computational costs. Furthermore, we provide a theoretical analysis demonstrating that SegACIL achieves performance on par with joint learning, effectively retaining knowledge from previous data which makes it to keep both stability and plasticity at the same time. Extensive experiments on the Pascal VOC2012 dataset show that SegACIL achieves superior performance in the sequential, disjoint, and overlap settings, offering a robust solution to the challenges of class-incremental semantic segmentation. Code is available at https://github.com/qwrawq/SegACIL.
UniGAD: Unifying Multi-level Graph Anomaly Detection
Nov 10, 2024



Graph Anomaly Detection (GAD) aims to identify uncommon, deviated, or suspicious objects within graph-structured data. Existing methods generally focus on a single graph object type (node, edge, graph, etc.) and often overlook the inherent connections among different object types of graph anomalies. For instance, a money laundering transaction might involve an abnormal account and the broader community it interacts with. To address this, we present UniGAD, the first unified framework for detecting anomalies at node, edge, and graph levels jointly. Specifically, we develop the Maximum Rayleigh Quotient Subgraph Sampler (MRQSampler) that unifies multi-level formats by transferring objects at each level into graph-level tasks on subgraphs. We theoretically prove that MRQSampler maximizes the accumulated spectral energy of subgraphs (i.e., the Rayleigh quotient) to preserve the most significant anomaly information. To further unify multi-level training, we introduce a novel GraphStitch Network to integrate information across different levels, adjust the amount of sharing required at each level, and harmonize conflicting training goals. Comprehensive experiments show that UniGAD outperforms both existing GAD methods specialized for a single task and graph prompt-based approaches for multiple tasks, while also providing robust zero-shot task transferability. All codes can be found at https://github.com/lllyyq1121/UniGAD.
GCoder: Improving Large Language Model for Generalized Graph Problem Solving
Oct 24, 2024
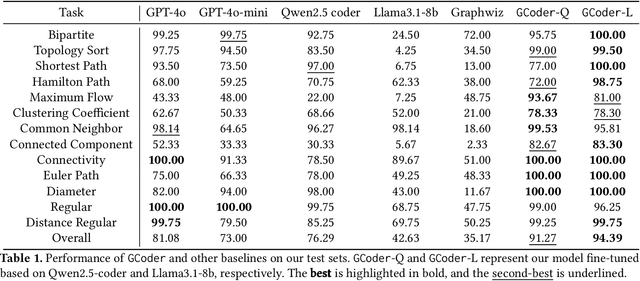


Large Language Models (LLMs) have demonstrated strong reasoning abilities, making them suitable for complex tasks such as graph computation. Traditional reasoning steps paradigm for graph problems is hindered by unverifiable steps, limited long-term reasoning, and poor generalization to graph variations. To overcome these limitations, we introduce GCoder, a code-based LLM designed to enhance problem-solving in generalized graph computation problems. Our method involves constructing an extensive training dataset, GraphWild, featuring diverse graph formats and algorithms. We employ a multi-stage training process, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Compiler Feedback (RLCF), to refine model capabilities. For unseen tasks, a hybrid retrieval technique is used to augment performance. Experiments demonstrate that GCoder outperforms GPT-4o, with an average accuracy improvement of 16.42% across various graph computational problems. Furthermore, GCoder efficiently manages large-scale graphs with millions of nodes and diverse input formats, overcoming the limitations of previous models focused on the reasoning steps paradigm. This advancement paves the way for more intuitive and effective graph problem-solving using LLMs. Code and data are available at here: https://github.com/Bklight999/WWW25-GCoder/tree/master.