 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantBench: Benchmarking AI Methods for Quantitative Investment
Apr 24, 2025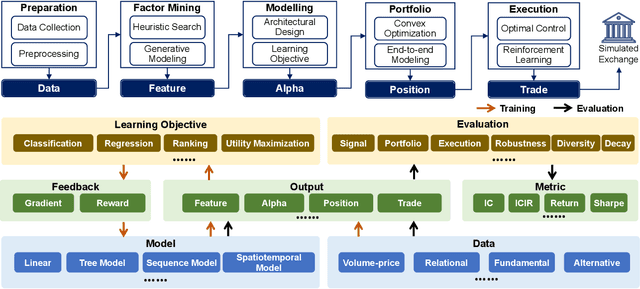



The field of artificial intelligence (AI) in quantitative investment has seen significant advancements, yet it lacks a standardized benchmark aligned with industry practices. This gap hinders research progress and limits the practical application of academic innovations. We present QuantBench, an industrial-grade benchmark platform designed to address this critical need. QuantBench offers three key strengths: (1) standardization that aligns with quantitative investment industry practices, (2) flexibility to integrate various AI algorithms, and (3) full-pipeline coverage of the entire quantitative investment process. Our empirical studies using QuantBench reveal some critical research directions, including the need for continual learning to address distribution shifts, improved methods for modeling relational financial data, and more robust approaches to mitigate overfitting in low signal-to-noise environments. By providing a common ground for evaluation and fostering collaboration between researchers and practitioners, QuantBench aims to accelerate progress in AI for quantitative investment, similar to the impact of benchmark platforms in computer vision and natural language processing.
Golden Touchstone: A Comprehensive Bilingual Benchmark for Evaluating Financial Large Language Models
Nov 09, 2024



As large language models become increasingly prevalent in the financial sector, there is a pressing need for a standardized method to comprehensively assess their performance. However, existing finance benchmarks often suffer from limited language and task coverage, as well as challenges such as low-quality datasets and inadequate adaptability for LLM evaluation. To address these limitations, we propose "Golden Touchstone", the first comprehensive bilingual benchmark for financial LLMs, which incorporates representative datasets from both Chinese and English across eight core financial NLP tasks. Developed from extensive open source data collection and industry-specific demands, this benchmark includes a variety of financial tasks aimed at thoroughly assessing models' language understanding and generation capabilities. Through comparative analysis of major models on the benchmark, such as GPT-4o Llama3, FinGPT and FinMA, we reveal their strengths and limitations in processing complex financial information. Additionally, we open-sourced Touchstone-GPT, a financial LLM trained through continual pre-training and financial instruction tuning, which demonstrates strong performance on the bilingual benchmark but still has limitations in specific tasks.This research not only provides the financial large language models with a practical evaluation tool but also guides the development and optimization of future research. The source code for Golden Touchstone and model weight of Touchstone-GPT have been made publicly available at \url{https://github.com/IDEA-FinAI/Golden-Touchstone}, contributing to the ongoing evolution of FinLLMs and fostering further research in this critical area.
A Survey on Large Language Model Hallucination via a Creativity Perspective
Feb 02, 2024



Hallucinations in large language models (LLMs) are always seen as limitations. However, could they also be a source of creativity? This survey explores this possibility, suggesting that hallucinations may contribute to LLM application by fostering creativity. This survey begins with a review of the taxonomy of hallucinations and their negative impact on LLM reliability in critical applications. Then, through historical examples and recent relevant theories, the survey explores the potential creative benefits of hallucinations in LLMs. To elucidate the value and evaluation criteria of this connection, we delve into the definitions and assessment methods of creativity. Following the framework of divergent and convergent thinking phases, the survey systematically reviews the literature on transforming and harnessing hallucinations for creativity in LLMs. Finally, the survey discusses future research directions, emphasizing the need to further explore and refine the application of hallucinations in creative processes within LLMs.
Unveiling the Potential of Sentiment: Can Large Language Models Predict Chinese Stock Price Movements?
Jun 25, 2023The rapid advancement of Large Language Models (LLMs) has led to extensive discourse regarding their potential to boost the return of quantitative stock trading strategies. This discourse primarily revolves around harnessing the remarkable comprehension capabilities of LLMs to extract sentiment factors which facilitate informed and high-frequency investment portfolio adjustments. To ensure successful implementations of these LLMs into the analysis of Chinese financial texts and the subsequent trading strategy development within the Chinese stock market, we provide a rigorous and encompassing benchmark as well as a standardized back-testing framework aiming at objectively assessing the efficacy of various types of LLMs in the specialized domain of sentiment factor extraction from Chinese news text data. To illustrate how our benchmark works, we reference three distinctive models: 1) the generative LLM (ChatGPT), 2) the Chinese language-specific pre-trained LLM (Erlangshen-RoBERTa), and 3) the financial domain-specific fine-tuned LLM classifier(Chinese FinBERT). We apply them directly to the task of sentiment factor extraction from large volumes of Chinese news summary texts. We then proceed to building quantitative trading strategies and running back-tests under realistic trading scenarios based on the derived sentiment factors and evaluate their performances with our benchmark. By constructing such a comparative analysis, we invoke the question of what constitutes the most important element for improving a LLM's performance on extracting sentiment factors. And by ensuring that the LLMs are evaluated on the same benchmark, following the same standardized experimental procedures that are designed with sufficient expertise in quantitative trading, we make the first stride toward answering such a question.
GADBench: Revisiting and Benchmarking Supervised Graph Anomaly Detection
Jun 21, 2023



With a long history of traditional Graph Anomaly Detection (GAD) algorithms and recently popular Graph Neural Networks (GNNs), it is still not clear (1) how they perform under a standard comprehensive setting, (2) whether GNNs outperform traditional algorithms such as tree ensembles, and (3) their efficiency on large-scale graphs. In response, we present GADBench -- a comprehensive benchmark for supervised anomalous node detection on static graphs. GADBench provides a thorough comparison across 23 distinct models on ten real-world GAD datasets ranging from thousands to millions of nodes ($\sim$6M). Our main finding is that tree ensembles with simple neighborhood aggregation outperform all other baselines, including the latest GNNs tailored for the GAD task. By making GADBench available as an open-source tool, we offer pivotal insights into the current advancements of GAD and establish a solid foundation for future research. Our code is available at https://github.com/squareRoot3/GADBench.