 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Personalized Conversational Information Retrieval
Aug 12, 2025Personalized conversational information retrieval (CIR) systems aim to satisfy users' complex information needs through multi-turn interactions by considering user profiles. However, not all search queries require personalization. The challenge lies in appropriately incorporating personalization elements into search when needed. Most existing studies implicitly incorporate users' personal information and conversational context using large language models without distinguishing the specific requirements for each query turn. Such a ``one-size-fits-all'' personalization strategy might lead to sub-optimal results. In this paper, we propose an adaptive personalization method, in which we first identify the required personalization level for a query and integrate personalized queries with other query reformulations to produce various enhanced queries. Then, we design a personalization-aware ranking fusion approach to assign fusion weights dynamically to different reformulated queries, depending on the required personalization level. The proposed adaptive personalized conversational information retrieval framework APCIR is evaluated on two TREC iKAT datasets. The results confirm the effectiveness of adaptive personalization of APCIR by outperforming state-of-the-art methods.
Latent Conditional Diffusion-based Data Augmentation for Continuous-Time Dynamic Graph Mode
Jul 11, 2024
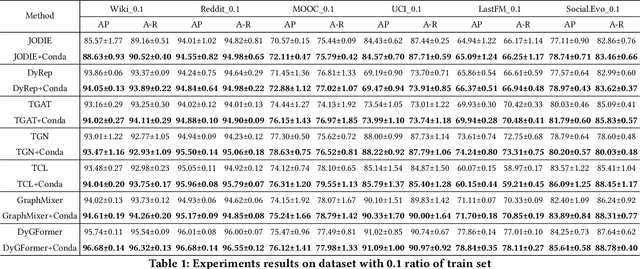
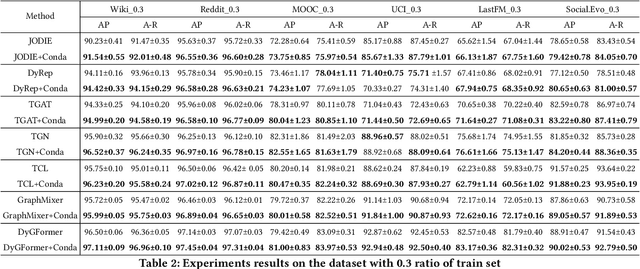

Continuous-Time Dynamic Graph (CTDG) precisely models evolving real-world relationships, drawing heightened interest in dynamic graph learning across academia and industry. However, existing CTDG models encounter challenges stemming from noise and limited historical data. Graph Data Augmentation (GDA) emerges as a critical solution, yet current approaches primarily focus on static graphs and struggle to effectively address the dynamics inherent in CTDGs. Moreover, these methods often demand substantial domain expertise for parameter tuning and lack theoretical guarantees for augmentation efficacy. To address these issues, we propose Conda, a novel latent diffusion-based GDA method tailored for CTDGs. Conda features a sandwich-like architecture, incorporating a Variational Auto-Encoder (VAE) and a conditional diffusion model, aimed at generating enhanced historical neighbor embeddings for target nodes. Unlike conventional diffusion models trained on entire graphs via pre-training, Conda requires historical neighbor sequence embeddings of target nodes for training, thus facilitating more targeted augmentation. We integrate Conda into the CTDG model and adopt an alternating training strategy to optimize performance. Extensive experimentation across six widely used real-world datasets showcases the consistent performance improvement of our approach, particularly in scenarios with limited historical data.
A Survey on Large Language Model Hallucination via a Creativity Perspective
Feb 02, 2024Hallucinations in large language models (LLMs) are always seen as limitations. However, could they also be a source of creativity? This survey explores this possibility, suggesting that hallucinations may contribute to LLM application by fostering creativity. This survey begins with a review of the taxonomy of hallucinations and their negative impact on LLM reliability in critical applications. Then, through historical examples and recent relevant theories, the survey explores the potential creative benefits of hallucinations in LLMs. To elucidate the value and evaluation criteria of this connection, we delve into the definitions and assessment methods of creativity. Following the framework of divergent and convergent thinking phases, the survey systematically reviews the literature on transforming and harnessing hallucinations for creativity in LLMs. Finally, the survey discusses future research directions, emphasizing the need to further explore and refine the application of hallucinations in creative processes within LLMs.
Natural Language Interfaces for Tabular Data Querying and Visualization: A Survey
Oct 27, 2023



The emergence of natural language processing has revolutionized the way users interact with tabular data, enabling a shift from traditional query languages and manual plotting to more intuitive, language-based interfaces. The rise of large language models (LLMs) such as ChatGPT and its successors has further advanced this field, opening new avenues for natural language processing techniques. This survey presents a comprehensive overview of natural language interfaces for tabular data querying and visualization, which allow users to interact with data using natural language queries. We introduce the fundamental concepts and techniques underlying these interfaces with a particular emphasis on semantic parsing, the key technology facilitating the translation from natural language to SQL queries or data visualization commands. We then delve into the recent advancements in Text-to-SQL and Text-to-Vis problems from the perspectives of datasets, methodologies, metrics, and system designs. This includes a deep dive into the influence of LLMs, highlighting their strengths, limitations, and potential for future improvements. Through this survey, we aim to provide a roadmap for researchers and practitioners interested in developing and applying natural language interfaces for data interaction in the era of large language models.
Boosting long-term forecasting performance for continuous-time dynamic graph networks via data augmentation
Apr 12, 2023



This study focuses on long-term forecasting (LTF) on continuous-time dynamic graph networks (CTDGNs), which is important for real-world modeling. Existing CTDGNs are effective for modeling temporal graph data due to their ability to capture complex temporal dependencies but perform poorly on LTF due to the substantial requirement for historical data, which is not practical in most cases. To relieve this problem, a most intuitive way is data augmentation. In this study, we propose \textbf{\underline{U}ncertainty \underline{M}asked \underline{M}ix\underline{U}p (UmmU)}: a plug-and-play module that conducts uncertainty estimation to introduce uncertainty into the embedding of intermediate layer of CTDGNs, and perform masked mixup to further enhance the uncertainty of the embedding to make it generalize to more situations. UmmU can be easily inserted into arbitrary CTDGNs without increasing the number of parameters. We conduct comprehensive experiments on three real-world dynamic graph datasets, the results demonstrate that UmmU can effectively improve the long-term forecasting performance for CTDGNs.
M3FGM:a node masking and multi-granularity message passing-based federated graph model for spatial-temporal data prediction
Oct 27, 2022
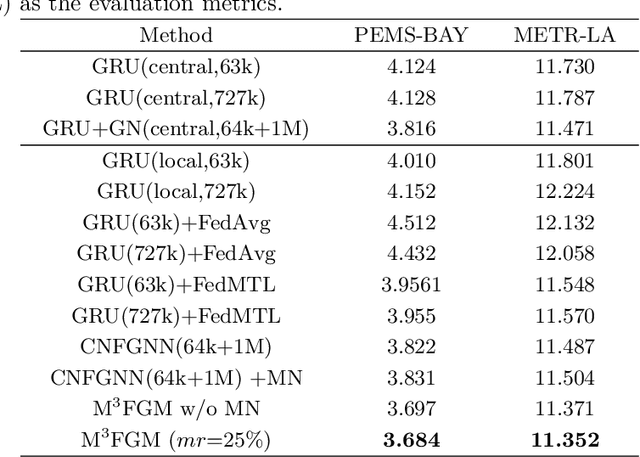
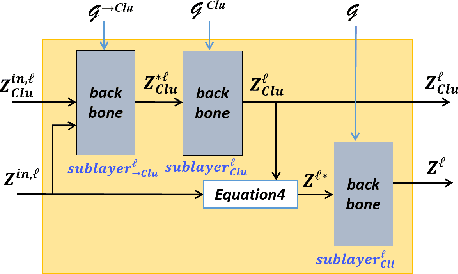
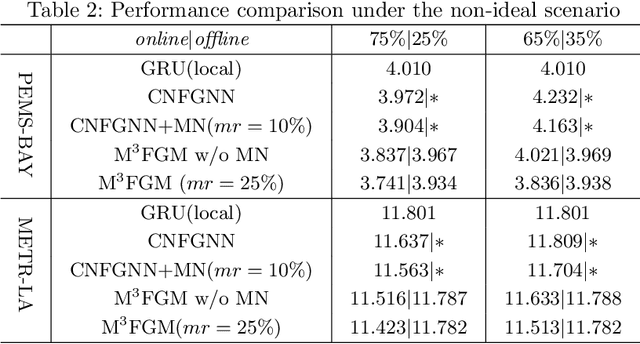
Researchers are solving the challenges of spatial-temporal prediction by combining Federated Learning (FL) and graph models with respect to the constrain of privacy and security. However, there are still several issues left unattended: 1) Clients might not be able to access the server during inference phase; 2) The graph of clients designed manually in the server model may not reveal the proper relationship between clients. This paper proposes a new embeddings aggregation structured FL approach named node Masking and Multi-granularity Message passing-based Federated Graph Model (M3FGM) for the above issues. The server model of M3FGM employs a MaskNode layer to simulate the case of offline clients. We also redesign the decoder of the client model using a dual-sub-decoders structure so that each client model can use its local data to predict independently when offline. As for the second issue, A new GNN layer named Multi-Granularity Message Passing (MGMP) allows each client node to perceive global and local information.We conducted extensive experiments in two different scenarios on two real traffic datasets. Results show that the proposed model outperforms the baselines and variant models, achieves the best results in both scenarios.