 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of Spectral Descent for Non-smooth Optimization
May 26, 2026The Muon optimizer has recently demonstrated remarkable empirical success in training large language models. However, the theoretical understanding of its mechanisms remains limited. Current convergence guarantees for Muon rely heavily on smoothness assumptions, leaving its non-smooth convergence behavior largely unexplored. In this work, we take a step toward bridging this gap by investigating Spectral Descent (SD), a simplified variant of Muon, together with its truncated counterpart, Truncated Spectral Descent (TSD). Under convexity, Lipschitz continuity, and sharpness conditions, we establish global linear convergence for both SD and TSD in non-smooth convex formulations. We also study regularized variants equipped with decoupled weight decay and derive sublinear convergence guarantees through their connection with Frank-Wolfe methods. Finally, we apply our theoretical framework to robust low-rank matrix recovery under mixed sparse and dense noise regimes and provide rigorous recovery guarantees. Numerical experiments support the theoretical findings and demonstrate the effectiveness of Muon-type methods for non-smooth optimization.
PlantMarkerBench: A Multi-Species Benchmark for Evidence-Grounded Plant Marker Reasoning
May 11, 2026Cell-type-specific marker genes are fundamental to plant biology, yet existing resources primarily rely on curated databases or high-throughput studies without explicitly modeling the supporting evidence found in scientific literature. We introduce PlantMarkerBench, a multi-species benchmark for evaluating literature-grounded plant marker evidence interpretation from full-text biological papers. PlantMarkerBench is constructed using a modular curation pipeline integrating large-scale literature retrieval, hybrid search, species-aware biological grounding, structured evidence extraction, and targeted human review. The benchmark spans four plant species -- Arabidopsis, maize, rice, and tomato -- and contains 5,550 sentence-level evidence instances annotated for marker-evidence validity, evidence type, and support strength. We define two benchmark tasks: determining whether a candidate sentence provides valid marker evidence for a gene-cell-type pair, and classifying the evidence into expression, localization, function, indirect, or negative categories. We benchmark diverse open-weight and closed-source language models across species and prompting strategies. Although frontier models achieve relatively strong performance on direct expression evidence, performance drops substantially on functional, indirect, and weak-support evidence, with evidence-type confusion emerging as a dominant failure mode. Open-weight models additionally exhibit elevated false-positive rates under ambiguous biological contexts. PlantMarkerBench provides a challenging and reproducible evaluation framework for literature-grounded biological evidence attribution and supports future research on trustworthy scientific information extraction and AI-assisted plant biology.
How Label Imbalance Shapes Geometry: A General Spectral Analysis of Multi-Label Neural Collapse
May 03, 2026This work investigates the phenomenon of Neural Collapse (NC) in multi-label classification, extending its conceptual framework from multi-class learning to general correlated and imbalanced multi-label settings. Although recent studies have identified a ''tag-wise averaging'' structure for multi-label features, this view relies on implicit assumptions of label balance and combinatorial symmetry. Consequently, it fails to account for the geometrical distortions caused by intrinsic label correlations and data imbalance, which are common in practice. We resolve the multiplicity-one imbalance conjecture raised by Li et al. (2024), showing that higher-multiplicity prototypes obey a class-frequency-weighted synthesis rule rather than uniform averaging. To address this, we propose a rigorous spectral-control framework to analyze the terminal phase of multi-label learning under general imbalanced conditions. We introduce the label covariance spectrum $κ_m$, a scalar controlling the distribution-dependent lower-bound geometry, derived from the second-order moment matrix of the label distribution. Contrary to the averaging perspective, our analysis reveals that the centered label covariance spectrum controls the stability of terminal geometry by quantifying the weakest centered inter-class contrast directions. We prove that the classical Tag-wise Averaging emerges only as a special case under perfect orthogonality. Numerical experiments on synthetic distributions validate our theoretical bounds. This work resolves the scaled-average aspect of the imbalance conjecture and establishes a unifying theoretical framework that extends Neural Collapse to complex, imbalanced multi-label settings.
CogMath: Assessing LLMs' Authentic Mathematical Ability from a Human Cognitive Perspective
Jun 04, 2025Although large language models (LLMs) show promise in solving complex mathematical tasks, existing evaluation paradigms rely solely on a coarse measure of overall answer accuracy, which are insufficient for assessing their authentic capabilities. In this paper, we propose \textbf{CogMath}, which comprehensively assesses LLMs' mathematical abilities through the lens of human cognition. Specifically, inspired by psychological theories, CogMath formalizes human reasoning process into 3 stages: \emph{problem comprehension}, \emph{problem solving}, and \emph{solution summarization}. Within these stages, we investigate perspectives such as numerical calculation, knowledge, and counterfactuals, and design a total of 9 fine-grained evaluation dimensions. In each dimension, we develop an ``\emph{Inquiry}-\emph{Judge}-\emph{Reference}'' multi-agent system to generate inquiries that assess LLMs' mastery from this dimension. An LLM is considered to truly master a problem only when excelling in all inquiries from the 9 dimensions. By applying CogMath on three benchmarks, we reveal that the mathematical capabilities of 7 mainstream LLMs are overestimated by 30\%-40\%. Moreover, we locate their strengths and weaknesses across specific stages/dimensions, offering in-depth insights to further enhance their reasoning abilities.
Audio Turing Test: Benchmarking the Human-likeness of Large Language Model-based Text-to-Speech Systems in Chinese
May 16, 2025Recent advances in large language models (LLMs) have significantly improved text-to-speech (TTS) systems, enhancing control over speech style, naturalness, and emotional expression, which brings TTS Systems closer to human-level performance. Although the Mean Opinion Score (MOS) remains the standard for TTS System evaluation, it suffers from subjectivity, environmental inconsistencies, and limited interpretability. Existing evaluation datasets also lack a multi-dimensional design, often neglecting factors such as speaking styles, context diversity, and trap utterances, which is particularly evident in Chinese TTS evaluation. To address these challenges, we introduce the Audio Turing Test (ATT), a multi-dimensional Chinese corpus dataset ATT-Corpus paired with a simple, Turing-Test-inspired evaluation protocol. Instead of relying on complex MOS scales or direct model comparisons, ATT asks evaluators to judge whether a voice sounds human. This simplification reduces rating bias and improves evaluation robustness. To further support rapid model development, we also finetune Qwen2-Audio-Instruct with human judgment data as Auto-ATT for automatic evaluation. Experimental results show that ATT effectively differentiates models across specific capability dimensions using its multi-dimensional design. Auto-ATT also demonstrates strong alignment with human evaluations, confirming its value as a fast and reliable assessment tool. The white-box ATT-Corpus and Auto-ATT can be found in ATT Hugging Face Collection (https://huggingface.co/collections/meituan/audio-turing-test-682446320368164faeaf38a4).
CT-UIO: Continuous-Time UWB-Inertial-Odometer Localization Using Non-Uniform B-spline with Fewer Anchors
Feb 10, 2025Ultra-wideband (UWB) based positioning with fewer anchors has attracted significant research interest in recent years, especially under energy-constrained conditions. However, most existing methods rely on discrete-time representations and smoothness priors to infer a robot's motion states, which often struggle with ensuring multi-sensor data synchronization. In this paper, we present an efficient UWB-Inertial-odometer localization system, utilizing a non-uniform B-spline framework with fewer anchors. Unlike traditional uniform B-spline-based continuous-time methods, we introduce an adaptive knot-span adjustment strategy for non-uniform continuous-time trajectory representation. This is accomplished by adjusting control points dynamically based on movement speed. To enable efficient fusion of IMU and odometer data, we propose an improved Extended Kalman Filter (EKF) with innovation-based adaptive estimation to provide short-term accurate motion prior. Furthermore, to address the challenge of achieving a fully observable UWB localization system under few-anchor conditions, the Virtual Anchor (VA) generation method based on multiple hypotheses is proposed. At the backend, we propose a CT-UIO factor graph with an adaptive sliding window for global trajectory estimation. Comprehensive experiments conducted on corridor and exhibition hall datasets validate the proposed system's high precision and robust performance. The codebase and datasets of this work will be open-sourced at https://github.com/JasonSun623/CT-UIO.
Immunogenicity Prediction with Dual Attention Enables Vaccine Target Selection
Oct 03, 2024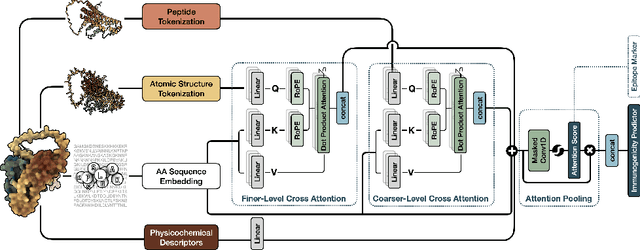
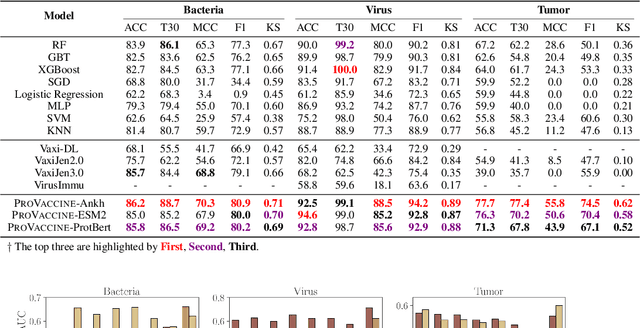
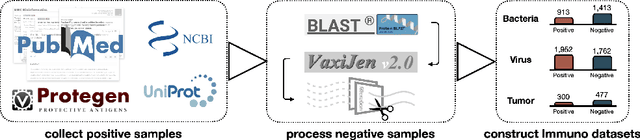

Immunogenicity prediction is a central topic in reverse vaccinology for finding candidate vaccines that can trigger protective immune responses. Existing approaches typically rely on highly compressed features and simple model architectures, leading to limited prediction accuracy and poor generalizability. To address these challenges, we introduce ProVaccine, a novel deep learning solution with a dual attention mechanism that integrates pre-trained latent vector representations of protein sequences and structures. We also compile the most comprehensive immunogenicity dataset to date, encompassing over 9,500 antigen sequences, structures, and immunogenicity labels from bacteria, viruses, and tumors. Extensive experiments demonstrate that ProVaccine outperforms existing methods across a wide range of evaluation metrics. Furthermore, we establish a post-hoc validation protocol to assess the practical significance of deep learning models in tackling vaccine design challenges. Our work provides an effective tool for vaccine design and sets valuable benchmarks for future research.
Air-to-Ground Cooperative OAM Communications
Jul 31, 2024For users in hotspot region, orbital angular momentum (OAM) can realize multifold increase of spectrum efficiency (SE), and the flying base station (FBS) can rapidly support the real-time communication demand. However, the hollow divergence and alignment requirement impose crucial challenges for users to achieve air-to-ground OAM communications, where there exists the line-of-sight path. Therefore, we propose the air-to-ground cooperative OAM communication (ACOC) scheme, which can realize OAM communications for users with size-limited devices. The waist radius is adjusted to guarantee the maximum intensity at the cooperative users (CUs). We derive the closed-form expression of the optimal FBS position, which satisfies the antenna alignment for two cooperative user groups (CUGs). Furthermore, the selection constraint is given to choose two CUGs composed of four CUs. Simulation results are provided to validate the optimal FBS position and the SE superiority of the proposed ACOC scheme.
MSR-86K: An Evolving, Multilingual Corpus with 86,300 Hours of Transcribed Audio for Speech Recognition Research
Jun 26, 2024
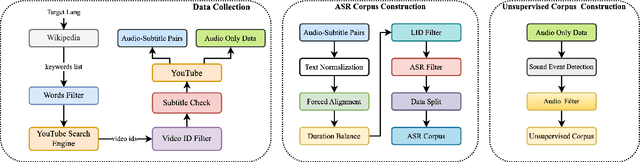


Recently, multilingual artificial intelligence assistants, exemplified by ChatGPT, have gained immense popularity. As a crucial gateway to human-computer interaction, multilingual automatic speech recognition (ASR) has also garnered significant attention, as evidenced by systems like Whisper. However, the proprietary nature of the training data has impeded researchers' efforts to study multilingual ASR. This paper introduces MSR-86K, an evolving, large-scale multilingual corpus for speech recognition research. The corpus is derived from publicly accessible videos on YouTube, comprising 15 languages and a total of 86,300 hours of transcribed ASR data. We also introduce how to use the MSR-86K corpus and other open-source corpora to train a robust multilingual ASR model that is competitive with Whisper. MSR-86K will be publicly released on HuggingFace, and we believe that such a large corpus will pave new avenues for research in multilingual ASR.
Enhancing Multilingual Speech Recognition through Language Prompt Tuning and Frame-Level Language Adapter
Sep 19, 2023

Multilingual intelligent assistants, such as ChatGPT, have recently gained popularity. To further expand the applications of multilingual artificial intelligence assistants and facilitate international communication, it is essential to enhance the performance of multilingual speech recognition, which is a crucial component of speech interaction. In this paper, we propose two simple and parameter-efficient methods: language prompt tuning and frame-level language adapter, to respectively enhance language-configurable and language-agnostic multilingual speech recognition. Additionally, we explore the feasibility of integrating these two approaches using parameter-efficient fine-tuning methods. Our experiments demonstrate significant performance improvements across seven languages using our proposed methods.