 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReTool-Video: Recursive Tool-Using Video Agents with Meta-Augmented Tool Grounding
May 13, 2026Video understanding requires active evidence seeking, motivating tool-augmented video agents for temporal reasoning, cross-modal understanding, and complex question answering. Existing video agents have improved video reasoning with retrieval, memory, frame inspection, and verifier tools, but they still face two limitations: (1) a coarse tool space that lacks fine-grained operations for compositional reasoning; and (2) a flat action space that forces high-level video intents into primitive executable tool calls. In this paper, we address these challenges with two complementary designs. First, we construct a MetaAug-Video Tool Library (MVTL), an extensible tool library with 134 registered tools, including 26 base tools for general multimodal signal processing and 108 meta tools for filtering, aggregation, reranking, formatting, and other intermediate-result operations. MVTL supports dual-level access to both structured video information and raw modal evidence, enabling diverse video reasoning scenarios. Second, we propose ReTool-Video, a recursive tool-using method that grounds high-level video intents into executable tool chains. In ReTool-Video, matched actions are executed directly, while unmatched intents are delegated to a resolver for parameter repair, tool substitution, or decomposition. This allows abstract actions such as temporal merging, cross-modal verification, or repeated-event aggregation to be progressively translated into concrete multimodal operations at runtime. Experiments on MVBench, MLVU, and Video-MME w/o sub. show that ReTool-Video consistently outperforms strong baselines. Further analysis demonstrates that recursive grounding and fine-grained meta tools improve the stability and effectiveness of complex video understanding.
CoMMET: To What Extent Can LLMs Perform Theory of Mind Tasks?
Mar 12, 2026Theory of Mind (ToM)-the ability to reason about the mental states of oneself and others-is a cornerstone of human social intelligence. As Large Language Models (LLMs) become ubiquitous in real-world applications, validating their capacity for this level of social reasoning is essential for effective and natural interactions. However, existing benchmarks for assessing ToM in LLMs are limited; most rely solely on text inputs and focus narrowly on belief-related tasks. In this paper, we propose a new multimodal benchmark dataset, CoMMET, a Comprehensive Mental states and Moral Evaluation Task inspired by the Theory of Mind Booklet Task. CoMMET expands the scope of evaluation by covering a broader range of mental states and introducing multi-turn testing. To the best of our knowledge, this is the first multimodal dataset to evaluate ToM in a multi-turn conversational setting. Through a comprehensive assessment of LLMs across different families and sizes, we analyze the strengths and limitations of current models and identify directions for future improvement. Our work offers a deeper understanding of the social cognitive capabilities of modern LLMs.
MELLA: Bridging Linguistic Capability and Cultural Groundedness for Low-Resource Language MLLMs
Aug 07, 2025Multimodal Large Language Models (MLLMs) have shown remarkable performance in high-resource languages. However, their effectiveness diminishes significantly in the contexts of low-resource languages. Current multilingual enhancement methods are often limited to text modality or rely solely on machine translation. While such approaches help models acquire basic linguistic capabilities and produce "thin descriptions", they neglect the importance of multimodal informativeness and cultural groundedness, both of which are crucial for serving low-resource language users effectively. To bridge this gap, in this study, we identify two significant objectives for a truly effective MLLM in low-resource language settings, namely 1) linguistic capability and 2) cultural groundedness, placing special emphasis on cultural awareness. To achieve these dual objectives, we propose a dual-source strategy that guides the collection of data tailored to each goal, sourcing native web alt-text for culture and MLLM-generated captions for linguistics. As a concrete implementation, we introduce MELLA, a multimodal, multilingual dataset. Experiment results show that after fine-tuning on MELLA, there is a general performance improvement for the eight languages on various MLLM backbones, with models producing "thick descriptions". We verify that the performance gains are from both cultural knowledge enhancement and linguistic capability enhancement. Our dataset can be found at https://opendatalab.com/applyMultilingualCorpus.
From Grounding to Manipulation: Case Studies of Foundation Model Integration in Embodied Robotic Systems
May 21, 2025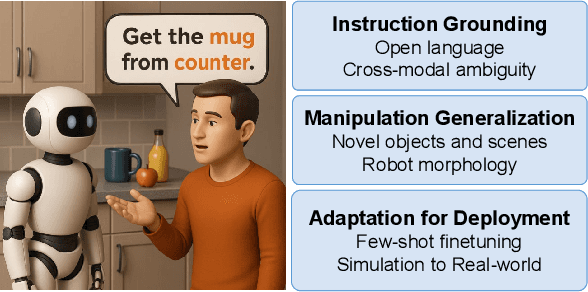



Foundation models (FMs) are increasingly used to bridge language and action in embodied agents, yet the operational characteristics of different FM integration strategies remain under-explored -- particularly for complex instruction following and versatile action generation in changing environments. This paper examines three paradigms for building robotic systems: end-to-end vision-language-action (VLA) models that implicitly integrate perception and planning, and modular pipelines incorporating either vision-language models (VLMs) or multimodal large language models (LLMs). We evaluate these paradigms through two focused case studies: a complex instruction grounding task assessing fine-grained instruction understanding and cross-modal disambiguation, and an object manipulation task targeting skill transfer via VLA finetuning. Our experiments in zero-shot and few-shot settings reveal trade-offs in generalization and data efficiency. By exploring performance limits, we distill design implications for developing language-driven physical agents and outline emerging challenges and opportunities for FM-powered robotics in real-world conditions.
LLM-Based Multi-Hop Question Answering with Knowledge Graph Integration in Evolving Environments
Aug 28, 2024



The rapid obsolescence of information in Large Language Models (LLMs) has driven the development of various techniques to incorporate new facts. However, existing methods for knowledge editing still face difficulties with multi-hop questions that require accurate fact identification and sequential logical reasoning, particularly among numerous fact updates. To tackle these challenges, this paper introduces Graph Memory-based Editing for Large Language Models (GMeLLo), a straitforward and effective method that merges the explicit knowledge representation of Knowledge Graphs (KGs) with the linguistic flexibility of LLMs. Beyond merely leveraging LLMs for question answering, GMeLLo employs these models to convert free-form language into structured queries and fact triples, facilitating seamless interaction with KGs for rapid updates and precise multi-hop reasoning. Our results show that GMeLLo significantly surpasses current state-of-the-art knowledge editing methods in the multi-hop question answering benchmark, MQuAKE, especially in scenarios with extensive knowledge edits.
Precoding Based Downlink OAM-MIMO Communications with Rate Splitting
Jul 31, 2024



Orbital angular momentum (OAM) and rate splitting (RS) are the potential key techniques for the future wireless communications. As a new orthogonal resource, OAM can achieve the multifold increase of spectrum efficiency to relieve the scarcity of the spectrum resource, but how to enhance the privacy performance imposes crucial challenge for OAM communications. RS technique divides the information into private and common parts, which can guarantee the privacies for all users. In this paper, we integrate the RS technique into downlink OAM-MIMO communications, and study the precoding optimization to maximize the sum capacity. First, the concentric uniform circular arrays (UCAs) are utilized to construct the downlink transmission framework of OAM-MIMO communications with RS. Particularly, users in the same user pair utilize RS technique to obtain the information and different user pairs use different OAM modes. Then, we derive the OAM-MIMO channel model, and formulate the sum capacity maximization problem. Finally, based on the fractional programming, the optimal precoding matrix is obtained to maximize the sum capacity by using quadratic transformation. Extensive simulation results show that by using the proposed precoding optimization algorithm, OAM-MIMO communications with RS can achieve higher sum capacity than the traditional communication schemes.
Air-to-Ground Cooperative OAM Communications
Jul 31, 2024For users in hotspot region, orbital angular momentum (OAM) can realize multifold increase of spectrum efficiency (SE), and the flying base station (FBS) can rapidly support the real-time communication demand. However, the hollow divergence and alignment requirement impose crucial challenges for users to achieve air-to-ground OAM communications, where there exists the line-of-sight path. Therefore, we propose the air-to-ground cooperative OAM communication (ACOC) scheme, which can realize OAM communications for users with size-limited devices. The waist radius is adjusted to guarantee the maximum intensity at the cooperative users (CUs). We derive the closed-form expression of the optimal FBS position, which satisfies the antenna alignment for two cooperative user groups (CUGs). Furthermore, the selection constraint is given to choose two CUGs composed of four CUs. Simulation results are provided to validate the optimal FBS position and the SE superiority of the proposed ACOC scheme.
Cooperative Orbital Angular Momentum Wireless Communications
Jul 31, 2024
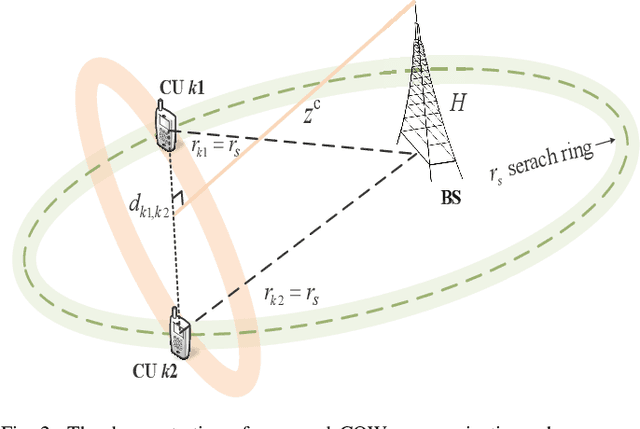

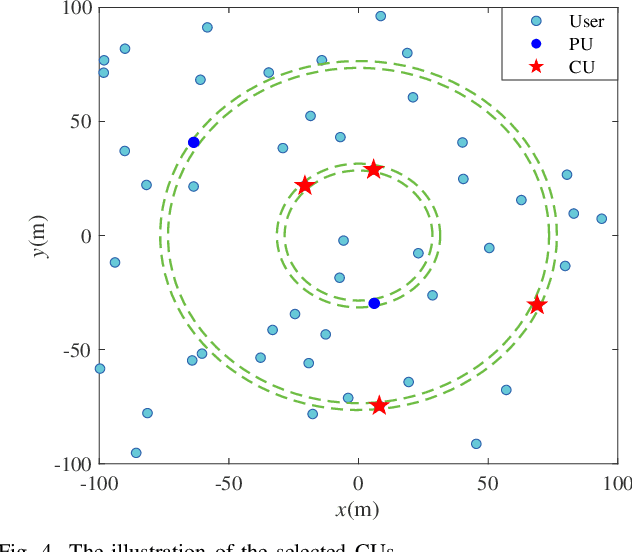
Orbital angular momentum (OAM) mode multiplexing has the potential to achieve high spectrum-efficiency communications at the same time and frequency by using orthogonal mode resource. However, the vortex wave hollow divergence characteristic results in the requirement of the large-scale receive antenna, which makes users hardly receive the OAM signal by size-limited equipment. To promote the OAM application in the next 6G communications, this paper proposes the cooperative OAM wireless (COW) communication scheme, which can select the cooperative users (CUs) to form the aligned antennas by size-limited user equipment. First, we derive the feasible radial radius and selective waist radius to choose the CUs in the same circle with the origin at the base station. Then, based on the locations of CUs, the waist radius is adjusted to form the receive antennas and ensure the maximum intensity for the CUs. Finally, the cooperative formation probability is derived in the closed-form solution, which can depict the feasibility of the proposed COW communication scheme. Furthermore, OAM beam steering is used to expand the feasible CU region, thus achieving higher cooperative formation probability. Simulation results demonstrate that the derived cooperative formation probability in mathematical analysis is very close to the statistical probability of cooperative formation, and the proposed COW communication scheme can obtain higher spectrum efficiency than the traditional scheme due to the effective reception of the OAM signal.
Relevant or Random: Can LLMs Truly Perform Analogical Reasoning?
Apr 19, 2024
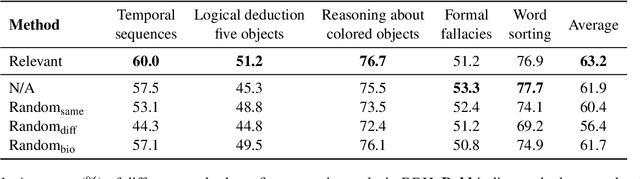
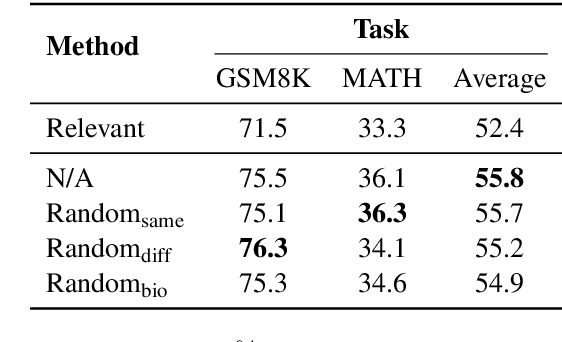
Analogical reasoning is a unique ability of humans to address unfamiliar challenges by transferring strategies from relevant past experiences. One key finding in psychology is that compared with irrelevant past experiences, recalling relevant ones can help humans better handle new tasks. Coincidentally, the NLP community has also recently found that self-generating relevant examples in the context can help large language models (LLMs) better solve a given problem than hand-crafted prompts. However, it is yet not clear whether relevance is the key factor eliciting such capability, i.e., can LLMs benefit more from self-generated relevant examples than irrelevant ones? In this work, we systematically explore whether LLMs can truly perform analogical reasoning on a diverse set of reasoning tasks. With extensive experiments and analysis, we show that self-generated random examples can surprisingly achieve comparable or even better performance, e.g., 4% performance boost on GSM8K with random biological examples. We find that the accuracy of self-generated examples is the key factor and subsequently design two improved methods with significantly reduced inference costs. Overall, we aim to advance a deeper understanding of LLM analogical reasoning and hope this work stimulates further research in the design of self-generated contexts.
Lifelong Event Detection with Embedding Space Separation and Compaction
Apr 03, 2024



To mitigate forgetting, existing lifelong event detection methods typically maintain a memory module and replay the stored memory data during the learning of a new task. However, the simple combination of memory data and new-task samples can still result in substantial forgetting of previously acquired knowledge, which may occur due to the potential overlap between the feature distribution of new data and the previously learned embedding space. Moreover, the model suffers from overfitting on the few memory samples rather than effectively remembering learned patterns. To address the challenges of forgetting and overfitting, we propose a novel method based on embedding space separation and compaction. Our method alleviates forgetting of previously learned tasks by forcing the feature distribution of new data away from the previous embedding space. It also mitigates overfitting by a memory calibration mechanism that encourages memory data to be close to its prototype to enhance intra-class compactness. In addition, the learnable parameters of the new task are initialized by drawing upon acquired knowledge from the previously learned task to facilitate forward knowledge transfer. With extensive experiments, we demonstrate that our method can significantly outperform previous state-of-the-art approaches.