 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Surprising Effectiveness of Masking Updates in Adaptive Optimizers
Feb 17, 2026Training large language models (LLMs) relies almost exclusively on dense adaptive optimizers with increasingly sophisticated preconditioners. We challenge this by showing that randomly masking parameter updates can be highly effective, with a masked variant of RMSProp consistently outperforming recent state-of-the-art optimizers. Our analysis reveals that the random masking induces a curvature-dependent geometric regularization that smooths the optimization trajectory. Motivated by this finding, we introduce Momentum-aligned gradient masking (Magma), which modulates the masked updates using momentum-gradient alignment. Extensive LLM pre-training experiments show that Magma is a simple drop-in replacement for adaptive optimizers with consistent gains and negligible computational overhead. Notably, for the 1B model size, Magma reduces perplexity by over 19\% and 9\% compared to Adam and Muon, respectively.
Relevant or Random: Can LLMs Truly Perform Analogical Reasoning?
Apr 19, 2024
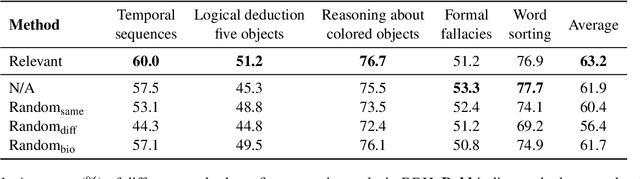
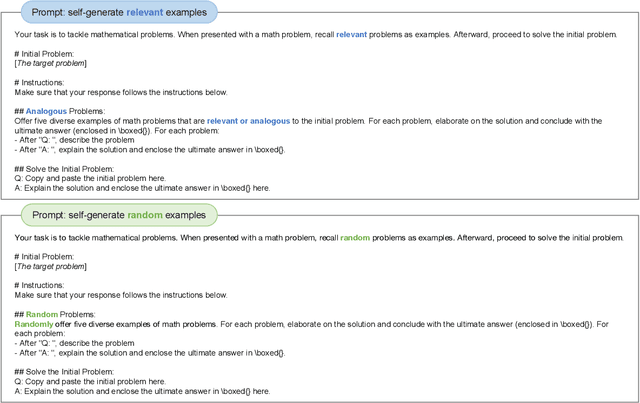
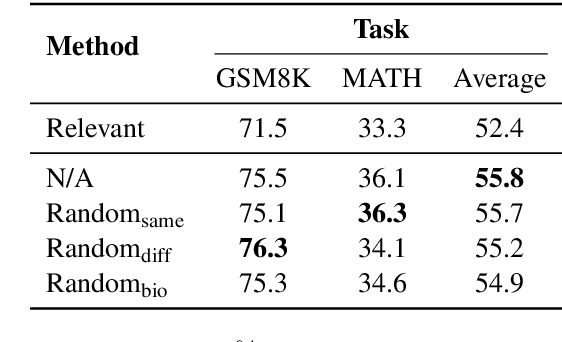
Analogical reasoning is a unique ability of humans to address unfamiliar challenges by transferring strategies from relevant past experiences. One key finding in psychology is that compared with irrelevant past experiences, recalling relevant ones can help humans better handle new tasks. Coincidentally, the NLP community has also recently found that self-generating relevant examples in the context can help large language models (LLMs) better solve a given problem than hand-crafted prompts. However, it is yet not clear whether relevance is the key factor eliciting such capability, i.e., can LLMs benefit more from self-generated relevant examples than irrelevant ones? In this work, we systematically explore whether LLMs can truly perform analogical reasoning on a diverse set of reasoning tasks. With extensive experiments and analysis, we show that self-generated random examples can surprisingly achieve comparable or even better performance, e.g., 4% performance boost on GSM8K with random biological examples. We find that the accuracy of self-generated examples is the key factor and subsequently design two improved methods with significantly reduced inference costs. Overall, we aim to advance a deeper understanding of LLM analogical reasoning and hope this work stimulates further research in the design of self-generated contexts.
Lifelong Event Detection with Embedding Space Separation and Compaction
Apr 03, 2024



To mitigate forgetting, existing lifelong event detection methods typically maintain a memory module and replay the stored memory data during the learning of a new task. However, the simple combination of memory data and new-task samples can still result in substantial forgetting of previously acquired knowledge, which may occur due to the potential overlap between the feature distribution of new data and the previously learned embedding space. Moreover, the model suffers from overfitting on the few memory samples rather than effectively remembering learned patterns. To address the challenges of forgetting and overfitting, we propose a novel method based on embedding space separation and compaction. Our method alleviates forgetting of previously learned tasks by forcing the feature distribution of new data away from the previous embedding space. It also mitigates overfitting by a memory calibration mechanism that encourages memory data to be close to its prototype to enhance intra-class compactness. In addition, the learnable parameters of the new task are initialized by drawing upon acquired knowledge from the previously learned task to facilitate forward knowledge transfer. With extensive experiments, we demonstrate that our method can significantly outperform previous state-of-the-art approaches.
Data Augmentation using LLMs: Data Perspectives, Learning Paradigms and Challenges
Mar 05, 2024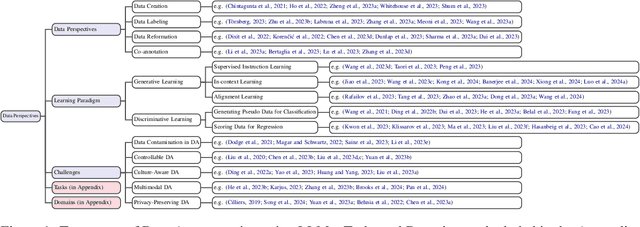
In the rapidly evolving field of machine learning (ML), data augmentation (DA) has emerged as a pivotal technique for enhancing model performance by diversifying training examples without the need for additional data collection. This survey explores the transformative impact of Large Language Models (LLMs) on DA, particularly addressing the unique challenges and opportunities they present in the context of natural language processing (NLP) and beyond. From a data perspective and a learning perspective, we examine various strategies that utilize Large Language Models for data augmentation, including a novel exploration of learning paradigms where LLM-generated data is used for further training. Additionally, this paper delineates the primary challenges faced in this domain, ranging from controllable data augmentation to multi modal data augmentation. This survey highlights the paradigm shift introduced by LLMs in DA, aims to serve as a foundational guide for researchers and practitioners in this field.
Chain of LoRA: Efficient Fine-tuning of Language Models via Residual Learning
Jan 08, 2024



Fine-tuning is the primary methodology for tailoring pre-trained large language models to specific tasks. As the model's scale and the diversity of tasks expand, parameter-efficient fine-tuning methods are of paramount importance. One of the most widely used family of methods is low-rank adaptation (LoRA) and its variants. LoRA encodes weight update as the product of two low-rank matrices. Despite its advantages, LoRA falls short of full-parameter fine-tuning in terms of generalization error for certain tasks. We introduce Chain of LoRA (COLA), an iterative optimization framework inspired by the Frank-Wolfe algorithm, to bridge the gap between LoRA and full parameter fine-tuning, without incurring additional computational costs or memory overheads. COLA employs a residual learning procedure where it merges learned LoRA modules into the pre-trained language model parameters and re-initilize optimization for new born LoRA modules. We provide theoretical convergence guarantees as well as empirical results to validate the effectiveness of our algorithm. Across various models (OPT and llama-2) and seven benchmarking tasks, we demonstrate that COLA can consistently outperform LoRA without additional computational or memory costs.
Improving In-context Learning via Bidirectional Alignment
Dec 28, 2023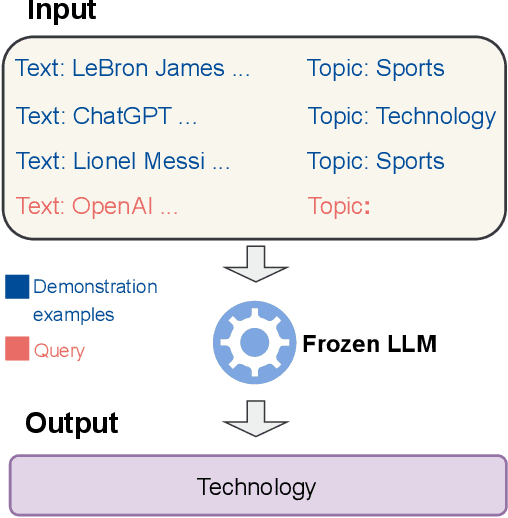

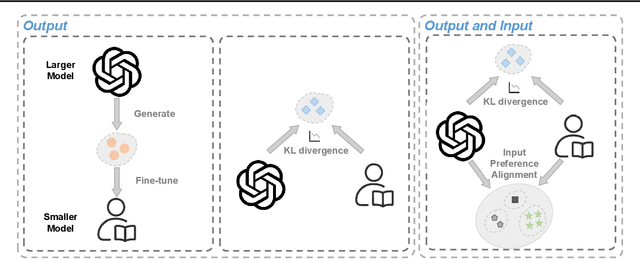
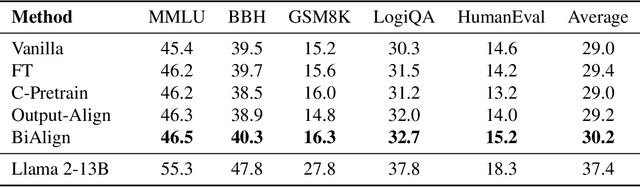
Large language models (LLMs) have shown impressive few-shot generalization on many tasks via in-context learning (ICL). Despite their success in showing such emergent abilities, the scale and complexity of larger models also lead to unprecedentedly high computational demands and deployment challenges. In reaction, researchers explore transferring the powerful capabilities of larger models to more efficient and compact models by typically aligning the output of smaller models with that of larger models. Existing methods either train smaller models on the generated outputs of larger models or to imitate their token-level probability distributions. However, these distillation methods pay little to no attention to the input part, which also plays a crucial role in ICL. Based on the finding that the performance of ICL is highly sensitive to the selection of demonstration examples, we propose Bidirectional Alignment (BiAlign) to fully leverage the models' preferences for ICL examples to improve the ICL abilities of smaller models. Specifically, we introduce the alignment of input preferences between smaller and larger models by incorporating a novel ranking loss, in addition to aligning the token-level output distribution. With extensive experiments and analysis, we demonstrate that BiAlign can consistently outperform existing baselines on a variety of tasks including language understanding, reasoning, and coding.
Online Learning for Obstacle Avoidance
Jun 14, 2023



We approach the fundamental problem of obstacle avoidance for robotic systems via the lens of online learning. In contrast to prior work that either assumes worst-case realizations of uncertainty in the environment or a stationary stochastic model of uncertainty, we propose a method that is efficient to implement and provably grants instance-optimality with respect to perturbations of trajectories generated from an open-loop planner (in the sense of minimizing worst-case regret). The resulting policy adapts online to realizations of uncertainty and provably compares well with the best obstacle avoidance policy in hindsight from a rich class of policies. The method is validated in simulation on a dynamical system environment and compared to baseline open-loop planning and robust Hamilton- Jacobi reachability techniques. Further, it is implemented on a hardware example where a quadruped robot traverses a dense obstacle field and encounters input disturbances due to time delays, model uncertainty, and dynamics nonlinearities.
Online Nonstochastic Model-Free Reinforcement Learning
May 27, 2023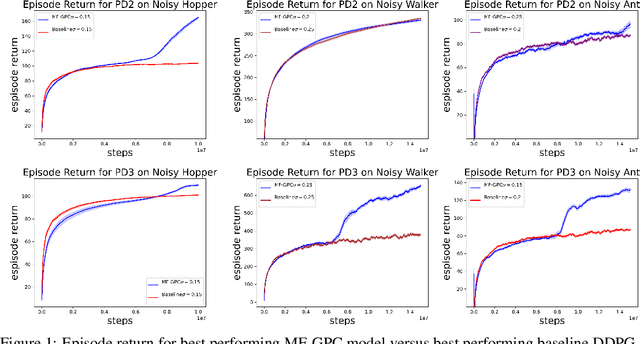
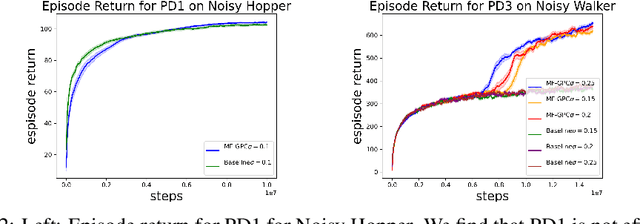

In this work, we explore robust model-free reinforcement learning algorithms for environments that may be dynamic or even adversarial. Conventional state-based policies fail to accommodate the challenge imposed by the presence of unmodeled disturbances in such settings. Additionally, optimizing linear state-based policies pose obstacle for efficient optimization, leading to nonconvex objectives even in benign environments like linear dynamical systems. Drawing inspiration from recent advancements in model-based control, we introduce a novel class of policies centered on disturbance signals. We define several categories of these signals, referred to as pseudo-disturbances, and corresponding policy classes based on them. We provide efficient and practical algorithms for optimizing these policies. Next, we examine the task of online adaptation of reinforcement learning agents to adversarial disturbances. Our methods can be integrated with any black-box model-free approach, resulting in provable regret guarantees if the underlying dynamics is linear. We evaluate our method over different standard RL benchmarks and demonstrate improved robustness.
Adaptive Gradient Methods with Local Guarantees
Mar 05, 2022
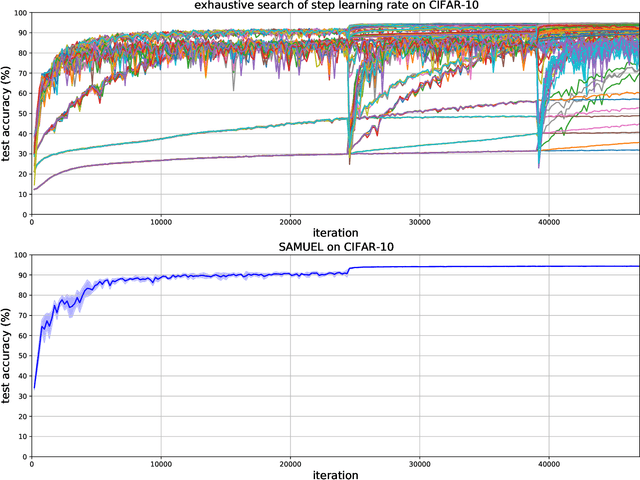
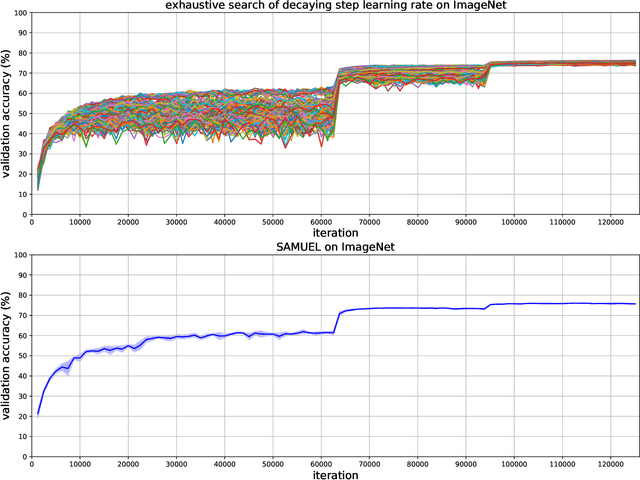
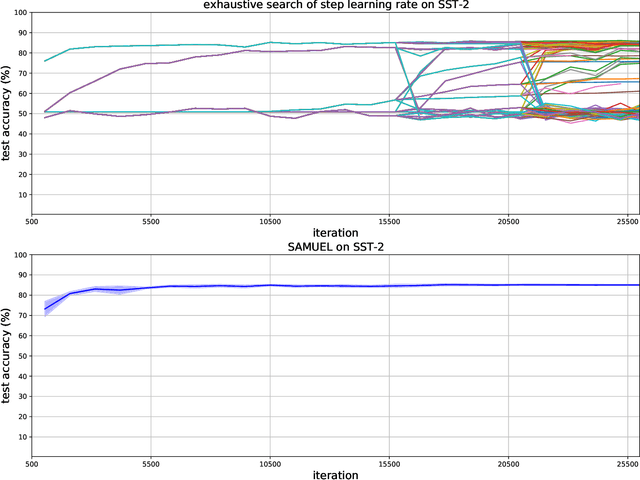
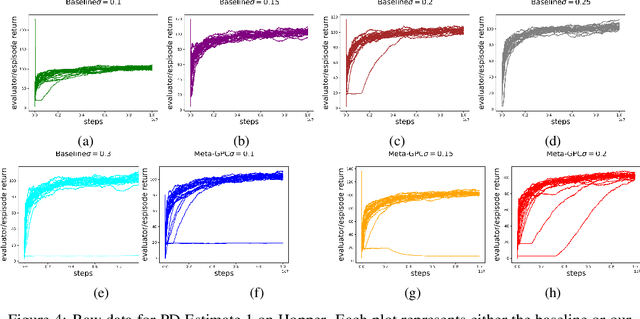
Adaptive gradient methods are the method of choice for optimization in machine learning and used to train the largest deep models. In this paper we study the problem of learning a local preconditioner, that can change as the data is changing along the optimization trajectory. We propose an adaptive gradient method that has provable adaptive regret guarantees vs. the best local preconditioner. To derive this guarantee, we prove a new adaptive regret bound in online learning that improves upon previous adaptive online learning methods. We demonstrate the robustness of our method in automatically choosing the optimal learning rate schedule for popular benchmarking tasks in vision and language domains. Without the need to manually tune a learning rate schedule, our method can, in a single run, achieve comparable and stable task accuracy as a fine-tuned optimizer.
Fully Dynamic Inference with Deep Neural Networks
Jul 29, 2020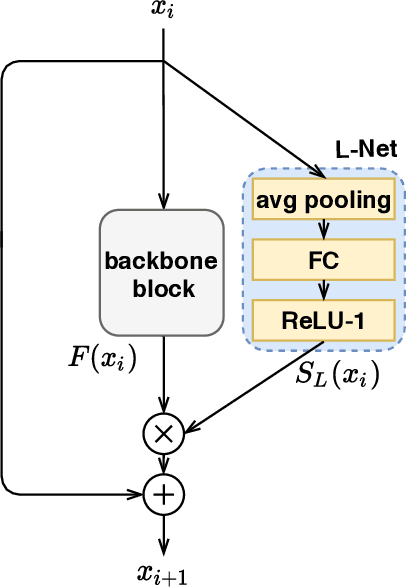
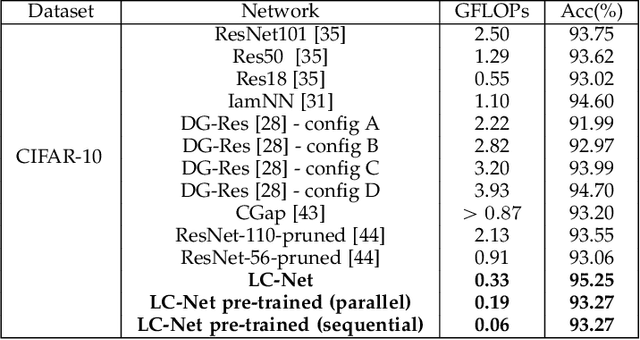
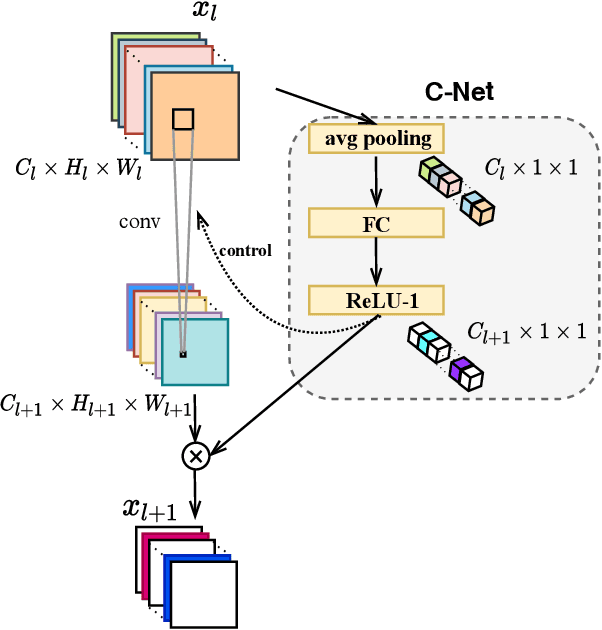

Modern deep neural networks are powerful and widely applicable models that extract task-relevant information through multi-level abstraction. Their cross-domain success, however, is often achieved at the expense of computational cost, high memory bandwidth, and long inference latency, which prevents their deployment in resource-constrained and time-sensitive scenarios, such as edge-side inference and self-driving cars. While recently developed methods for creating efficient deep neural networks are making their real-world deployment more feasible by reducing model size, they do not fully exploit input properties on a per-instance basis to maximize computational efficiency and task accuracy. In particular, most existing methods typically use a one-size-fits-all approach that identically processes all inputs. Motivated by the fact that different images require different feature embeddings to be accurately classified, we propose a fully dynamic paradigm that imparts deep convolutional neural networks with hierarchical inference dynamics at the level of layers and individual convolutional filters/channels. Two compact networks, called Layer-Net (L-Net) and Channel-Net (C-Net), predict on a per-instance basis which layers or filters/channels are redundant and therefore should be skipped. L-Net and C-Net also learn how to scale retained computation outputs to maximize task accuracy. By integrating L-Net and C-Net into a joint design framework, called LC-Net, we consistently outperform state-of-the-art dynamic frameworks with respect to both efficiency and classification accuracy. On the CIFAR-10 dataset, LC-Net results in up to 11.9$\times$ fewer floating-point operations (FLOPs) and up to 3.3% higher accuracy compared to other dynamic inference methods. On the ImageNet dataset, LC-Net achieves up to 1.4$\times$ fewer FLOPs and up to 4.6% higher Top-1 accuracy than the other methods.