 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Transformers: Conformal Prediction for Language Models
Apr 10, 2026Transformers have had a profound impact on the field of artificial intelligence, especially on large language models and their variants. However, as was the case with neural networks, their black-box nature limits trust and deployment in high-stakes settings. For models to be genuinely useful and trustworthy in critical applications, they must provide more than just predictions: they must supply users with a clear understanding of the reasoning that underpins their decisions. This article presents an uncertainty quantification framework for transformer-based language models. This framework, called CONFIDE (CONformal prediction for FIne-tuned DEep language models), applies conformal prediction to the internal embeddings of encoder-only architectures, like BERT and RoBERTa, while enabling hyperparameter tuning. CONFIDE uses either [CLS] token embeddings or flattened hidden states to construct class-conditional nonconformity scores, enabling statistically valid prediction sets with instance-level explanations. Empirically, CONFIDE improves test accuracy by up to 4.09% on BERT-tiny and achieves greater correct efficiency (i.e., the expected size of the prediction set conditioned on it containing the true label) compared to prior methods, including NM2 and VanillaNN. We show that early and intermediate transformer layers often yield better-calibrated and more semantically meaningful representations for conformal prediction. In resource-constrained models and high-stakes tasks with ambiguous labels, CONFIDE offers robustness and interpretability where softmax-based uncertainty fails. We position CONFIDE as a framework for practical diagnostic and efficiency/robustness improvement over prior conformal baselines.
An Alternative Trajectory for Generative AI
Mar 14, 2026The generative artificial intelligence (AI) ecosystem is undergoing rapid transformations that threaten its sustainability. As models transition from research prototypes to high-traffic products, the energetic burden has shifted from one-time training to recurring, unbounded inference. This is exacerbated by reasoning models that inflate compute costs by orders of magnitude per query. The prevailing pursuit of artificial general intelligence through scaling of monolithic models is colliding with hard physical constraints: grid failures, water consumption, and diminishing returns on data scaling. This trajectory yields models with impressive factual recall but struggles in domains requiring in-depth reasoning, possibly due to insufficient abstractions in training data. Current large language models (LLMs) exhibit genuine reasoning depth only in domains like mathematics and coding, where rigorous, pre-existing abstractions provide structural grounding. In other fields, the current approach fails to generalize well. We propose an alternative trajectory based on domain-specific superintelligence (DSS). We argue for first constructing explicit symbolic abstractions (knowledge graphs, ontologies, and formal logic) to underpin synthetic curricula enabling small language models to master domain-specific reasoning without the model collapse problem typical of LLM-based synthetic data methods. Rather than a single generalist giant model, we envision "societies of DSS models": dynamic ecosystems where orchestration agents route tasks to distinct DSS back-ends. This paradigm shift decouples capability from size, enabling intelligence to migrate from energy-intensive data centers to secure, on-device experts. By aligning algorithmic progress with physical constraints, DSS societies move generative AI from an environmental liability to a sustainable force for economic empowerment.
Knowledge Graphs are Implicit Reward Models: Path-Derived Signals Enable Compositional Reasoning
Jan 21, 2026Large language models have achieved near-expert performance in structured reasoning domains like mathematics and programming, yet their ability to perform compositional multi-hop reasoning in specialized scientific fields remains limited. We propose a bottom-up learning paradigm in which models are grounded in axiomatic domain facts and compose them to solve complex, unseen tasks. To this end, we present a post-training pipeline, based on a combination of supervised fine-tuning and reinforcement learning (RL), in which knowledge graphs act as implicit reward models. By deriving novel reward signals from knowledge graph paths, we provide verifiable, scalable, and grounded supervision that encourages models to compose intermediate axioms rather than optimize only final answers during RL. We validate this approach in the medical domain, training a 14B model on short-hop reasoning paths (1-3 hops) and evaluating its zero-shot generalization to complex multi-hop queries (4-5 hops). Our experiments show that path-derived rewards act as a "compositional bridge", enabling our model to significantly outperform much larger models and frontier systems like GPT-5.2 and Gemini 3 Pro, on the most difficult reasoning tasks. Furthermore, we demonstrate the robustness of our approach to adversarial perturbations against option-shuffling stress tests. This work suggests that grounding the reasoning process in structured knowledge is a scalable and efficient path toward intelligent reasoning.
CD4LM: Consistency Distillation and aDaptive Decoding for Diffusion Language Models
Jan 05, 2026Autoregressive large language models achieve strong results on many benchmarks, but decoding remains fundamentally latency-limited by sequential dependence on previously generated tokens. Diffusion language models (DLMs) promise parallel generation but suffer from a fundamental static-to-dynamic misalignment: Training optimizes local transitions under fixed schedules, whereas efficient inference requires adaptive "long-jump" refinements through unseen states. Our goal is to enable highly parallel decoding for DLMs with low number of function evaluations while preserving generation quality. To achieve this, we propose CD4LM, a framework that decouples training from inference via Discrete-Space Consistency Distillation (DSCD) and Confidence-Adaptive Decoding (CAD). Unlike standard objectives, DSCD trains a student to be trajectory-invariant, mapping diverse noisy states directly to the clean distribution. This intrinsic robustness enables CAD to dynamically allocate compute resources based on token confidence, aggressively skipping steps without the quality collapse typical of heuristic acceleration. On GSM8K, CD4LM matches the LLaDA baseline with a 5.18x wall-clock speedup; across code and math benchmarks, it strictly dominates the accuracy-efficiency Pareto frontier, achieving a 3.62x mean speedup while improving average accuracy. Code is available at https://github.com/yihao-liang/CDLM
LinMU: Multimodal Understanding Made Linear
Jan 04, 2026Modern Vision-Language Models (VLMs) achieve impressive performance but are limited by the quadratic complexity of self-attention, which prevents their deployment on edge devices and makes their understanding of high-resolution images and long-context videos prohibitively expensive. To address this challenge, we introduce LinMU (Linear-complexity Multimodal Understanding), a VLM design that achieves linear complexity without using any quadratic-complexity modules while maintaining the performance of global-attention-based VLMs. LinMU replaces every self-attention layer in the VLM with the M-MATE block: a dual-branch module that combines a bidirectional state-space model for global context (Flex-MA branch) with localized Swin-style window attention (Local-Swin branch) for adjacent correlations. To transform a pre-trained VLM into the LinMU architecture, we propose a three-stage distillation framework that (i) initializes both branches with self-attention weights and trains the Flex-MA branch alone, (ii) unfreezes the Local-Swin branch and fine-tunes it jointly with the Flex-MA branch, and (iii) unfreezes the remaining blocks and fine-tunes them using LoRA adapters, while regressing on hidden states and token-level logits of the frozen VLM teacher. On MMMU, TextVQA, LongVideoBench, Video-MME, and other benchmarks, LinMU matches the performance of teacher models, yet reduces Time-To-First-Token (TTFT) by up to 2.7$\times$ and improves token throughput by up to 9.0$\times$ on minute-length videos. Ablations confirm the importance of each distillation stage and the necessity of the two branches of the M-MATE block. The proposed framework demonstrates that state-of-the-art multimodal reasoning can be achieved without quadratic attention, thus opening up avenues for long-context VLMs that can deal with high-resolution images and long videos.
GraphMERT: Efficient and Scalable Distillation of Reliable Knowledge Graphs from Unstructured Data
Oct 10, 2025

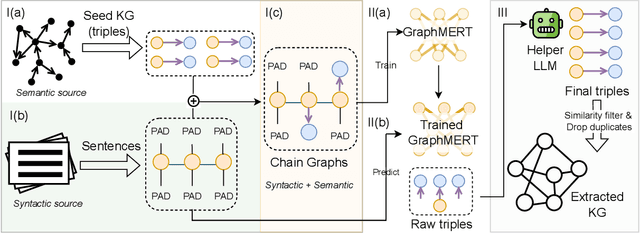

Researchers have pursued neurosymbolic artificial intelligence (AI) applications for nearly three decades because symbolic components provide abstraction while neural components provide generalization. Thus, a marriage of the two components can lead to rapid advancements in AI. Yet, the field has not realized this promise since most neurosymbolic AI frameworks fail to scale. In addition, the implicit representations and approximate reasoning of neural approaches limit interpretability and trust. Knowledge graphs (KGs), a gold-standard representation of explicit semantic knowledge, can address the symbolic side. However, automatically deriving reliable KGs from text corpora has remained an open problem. We address these challenges by introducing GraphMERT, a tiny graphical encoder-only model that distills high-quality KGs from unstructured text corpora and its own internal representations. GraphMERT and its equivalent KG form a modular neurosymbolic stack: neural learning of abstractions; symbolic KGs for verifiable reasoning. GraphMERT + KG is the first efficient and scalable neurosymbolic model to achieve state-of-the-art benchmark accuracy along with superior symbolic representations relative to baselines. Concretely, we target reliable domain-specific KGs that are both (1) factual (with provenance) and (2) valid (ontology-consistent relations with domain-appropriate semantics). When a large language model (LLM), e.g., Qwen3-32B, generates domain-specific KGs, it falls short on reliability due to prompt sensitivity, shallow domain expertise, and hallucinated relations. On text obtained from PubMed papers on diabetes, our 80M-parameter GraphMERT yields a KG with a 69.8% FActScore; a 32B-parameter baseline LLM yields a KG that achieves only 40.2% FActScore. The GraphMERT KG also attains a higher ValidityScore of 68.8%, versus 43.0% for the LLM baseline.
LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity
Dec 13, 2024



Text-to-video generation enhances content creation but is highly computationally intensive: The computational cost of Diffusion Transformers (DiTs) scales quadratically in the number of pixels. This makes minute-length video generation extremely expensive, limiting most existing models to generating videos of only 10-20 seconds length. We propose a Linear-complexity text-to-video Generation (LinGen) framework whose cost scales linearly in the number of pixels. For the first time, LinGen enables high-resolution minute-length video generation on a single GPU without compromising quality. It replaces the computationally-dominant and quadratic-complexity block, self-attention, with a linear-complexity block called MATE, which consists of an MA-branch and a TE-branch. The MA-branch targets short-to-long-range correlations, combining a bidirectional Mamba2 block with our token rearrangement method, Rotary Major Scan, and our review tokens developed for long video generation. The TE-branch is a novel TEmporal Swin Attention block that focuses on temporal correlations between adjacent tokens and medium-range tokens. The MATE block addresses the adjacency preservation issue of Mamba and improves the consistency of generated videos significantly. Experimental results show that LinGen outperforms DiT (with a 75.6% win rate) in video quality with up to 15$\times$ (11.5$\times$) FLOPs (latency) reduction. Furthermore, both automatic metrics and human evaluation demonstrate our LinGen-4B yields comparable video quality to state-of-the-art models (with a 50.5%, 52.1%, 49.1% win rate with respect to Gen-3, LumaLabs, and Kling, respectively). This paves the way to hour-length movie generation and real-time interactive video generation. We provide 68s video generation results and more examples in our project website: https://lineargen.github.io/.
COMFORT: A Continual Fine-Tuning Framework for Foundation Models Targeted at Consumer Healthcare
Sep 14, 2024



Wearable medical sensors (WMSs) are revolutionizing smart healthcare by enabling continuous, real-time monitoring of user physiological signals, especially in the field of consumer healthcare. The integration of WMSs and modern machine learning (ML) enables unprecedented solutions to efficient early-stage disease detection. Despite the success of Transformers in various fields, their application to sensitive domains, such as smart healthcare, remains underexplored due to limited data accessibility and privacy concerns. To bridge the gap between Transformer-based foundation models and WMS-based disease detection, we propose COMFORT, a continual fine-tuning framework for foundation models targeted at consumer healthcare. COMFORT introduces a novel approach for pre-training a Transformer-based foundation model on a large dataset of physiological signals exclusively collected from healthy individuals with commercially available WMSs. We adopt a masked data modeling (MDM) objective to pre-train this health foundation model. We then fine-tune the model using various parameter-efficient fine-tuning (PEFT) methods, such as low-rank adaptation (LoRA) and its variants, to adapt it to various downstream disease detection tasks that rely on WMS data. In addition, COMFORT continually stores the low-rank decomposition matrices obtained from the PEFT algorithms to construct a library for multi-disease detection. The COMFORT library enables scalable and memory-efficient disease detection on edge devices. Our experimental results demonstrate that COMFORT achieves highly competitive performance while reducing memory overhead by up to 52% relative to conventional methods. Thus, COMFORT paves the way for personalized and proactive solutions to efficient and effective early-stage disease detection for consumer healthcare.
Learning Interpretable Differentiable Logic Networks
Jul 04, 2024The ubiquity of neural networks (NNs) in real-world applications, from healthcare to natural language processing, underscores their immense utility in capturing complex relationships within high-dimensional data. However, NNs come with notable disadvantages, such as their "black-box" nature, which hampers interpretability, as well as their tendency to overfit the training data. We introduce a novel method for learning interpretable differentiable logic networks (DLNs) that are architectures that employ multiple layers of binary logic operators. We train these networks by softening and differentiating their discrete components, e.g., through binarization of inputs, binary logic operations, and connections between neurons. This approach enables the use of gradient-based learning methods. Experimental results on twenty classification tasks indicate that differentiable logic networks can achieve accuracies comparable to or exceeding that of traditional NNs. Equally importantly, these networks offer the advantage of interpretability. Moreover, their relatively simple structure results in the number of logic gate-level operations during inference being up to a thousand times smaller than NNs, making them suitable for deployment on edge devices.
METRIK: Measurement-Efficient Randomized Controlled Trials using Transformers with Input Masking
Jun 24, 2024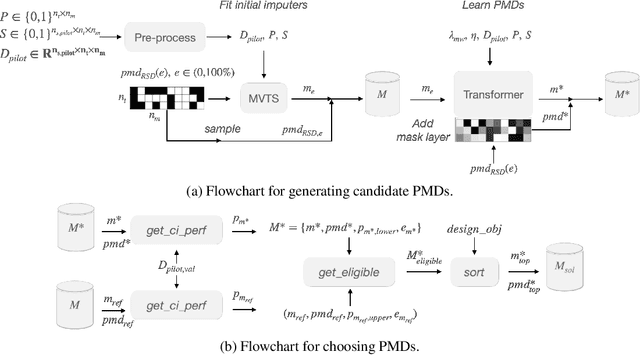

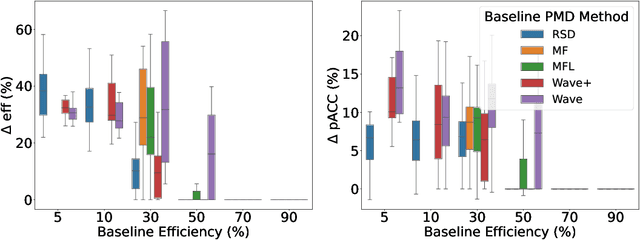
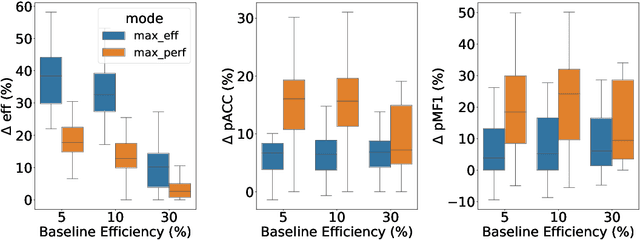
Clinical randomized controlled trials (RCTs) collect hundreds of measurements spanning various metric types (e.g., laboratory tests, cognitive/motor assessments, etc.) across 100s-1000s of subjects to evaluate the effect of a treatment, but do so at the cost of significant trial expense. To reduce the number of measurements, trial protocols can be revised to remove metrics extraneous to the study's objective, but doing so requires additional human labor and limits the set of hypotheses that can be studied with the collected data. In contrast, a planned missing design (PMD) can reduce the amount of data collected without removing any metric by imputing the unsampled data. Standard PMDs randomly sample data to leverage statistical properties of imputation algorithms, but are ad hoc, hence suboptimal. Methods that learn PMDs produce more sample-efficient PMDs, but are not suitable for RCTs because they require ample prior data (150+ subjects) to model the data distribution. Therefore, we introduce a framework called Measurement EfficienT Randomized Controlled Trials using Transformers with Input MasKing (METRIK), which, for the first time, calculates a PMD specific to the RCT from a modest amount of prior data (e.g., 60 subjects). Specifically, METRIK models the PMD as a learnable input masking layer that is optimized with a state-of-the-art imputer based on the Transformer architecture. METRIK implements a novel sampling and selection algorithm to generate a PMD that satisfies the trial designer's objective, i.e., whether to maximize sampling efficiency or imputation performance for a given sampling budget. Evaluated across five real-world clinical RCT datasets, METRIK increases the sampling efficiency of and imputation performance under the generated PMD by leveraging correlations over time and across metrics, thereby removing the need to manually remove metrics from the RCT.