 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinMU: Multimodal Understanding Made Linear
Jan 04, 2026Modern Vision-Language Models (VLMs) achieve impressive performance but are limited by the quadratic complexity of self-attention, which prevents their deployment on edge devices and makes their understanding of high-resolution images and long-context videos prohibitively expensive. To address this challenge, we introduce LinMU (Linear-complexity Multimodal Understanding), a VLM design that achieves linear complexity without using any quadratic-complexity modules while maintaining the performance of global-attention-based VLMs. LinMU replaces every self-attention layer in the VLM with the M-MATE block: a dual-branch module that combines a bidirectional state-space model for global context (Flex-MA branch) with localized Swin-style window attention (Local-Swin branch) for adjacent correlations. To transform a pre-trained VLM into the LinMU architecture, we propose a three-stage distillation framework that (i) initializes both branches with self-attention weights and trains the Flex-MA branch alone, (ii) unfreezes the Local-Swin branch and fine-tunes it jointly with the Flex-MA branch, and (iii) unfreezes the remaining blocks and fine-tunes them using LoRA adapters, while regressing on hidden states and token-level logits of the frozen VLM teacher. On MMMU, TextVQA, LongVideoBench, Video-MME, and other benchmarks, LinMU matches the performance of teacher models, yet reduces Time-To-First-Token (TTFT) by up to 2.7$\times$ and improves token throughput by up to 9.0$\times$ on minute-length videos. Ablations confirm the importance of each distillation stage and the necessity of the two branches of the M-MATE block. The proposed framework demonstrates that state-of-the-art multimodal reasoning can be achieved without quadratic attention, thus opening up avenues for long-context VLMs that can deal with high-resolution images and long videos.
LinGen: Towards High-Resolution Minute-Length Text-to-Video Generation with Linear Computational Complexity
Dec 13, 2024



Text-to-video generation enhances content creation but is highly computationally intensive: The computational cost of Diffusion Transformers (DiTs) scales quadratically in the number of pixels. This makes minute-length video generation extremely expensive, limiting most existing models to generating videos of only 10-20 seconds length. We propose a Linear-complexity text-to-video Generation (LinGen) framework whose cost scales linearly in the number of pixels. For the first time, LinGen enables high-resolution minute-length video generation on a single GPU without compromising quality. It replaces the computationally-dominant and quadratic-complexity block, self-attention, with a linear-complexity block called MATE, which consists of an MA-branch and a TE-branch. The MA-branch targets short-to-long-range correlations, combining a bidirectional Mamba2 block with our token rearrangement method, Rotary Major Scan, and our review tokens developed for long video generation. The TE-branch is a novel TEmporal Swin Attention block that focuses on temporal correlations between adjacent tokens and medium-range tokens. The MATE block addresses the adjacency preservation issue of Mamba and improves the consistency of generated videos significantly. Experimental results show that LinGen outperforms DiT (with a 75.6% win rate) in video quality with up to 15$\times$ (11.5$\times$) FLOPs (latency) reduction. Furthermore, both automatic metrics and human evaluation demonstrate our LinGen-4B yields comparable video quality to state-of-the-art models (with a 50.5%, 52.1%, 49.1% win rate with respect to Gen-3, LumaLabs, and Kling, respectively). This paves the way to hour-length movie generation and real-time interactive video generation. We provide 68s video generation results and more examples in our project website: https://lineargen.github.io/.
Attention-Driven Training-Free Efficiency Enhancement of Diffusion Models
May 08, 2024
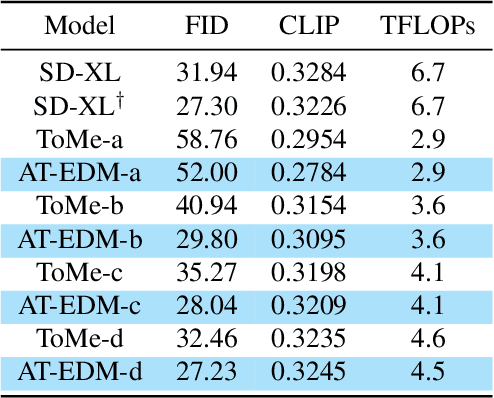


Diffusion Models (DMs) have exhibited superior performance in generating high-quality and diverse images. However, this exceptional performance comes at the cost of expensive architectural design, particularly due to the attention module heavily used in leading models. Existing works mainly adopt a retraining process to enhance DM efficiency. This is computationally expensive and not very scalable. To this end, we introduce the Attention-driven Training-free Efficient Diffusion Model (AT-EDM) framework that leverages attention maps to perform run-time pruning of redundant tokens, without the need for any retraining. Specifically, for single-denoising-step pruning, we develop a novel ranking algorithm, Generalized Weighted Page Rank (G-WPR), to identify redundant tokens, and a similarity-based recovery method to restore tokens for the convolution operation. In addition, we propose a Denoising-Steps-Aware Pruning (DSAP) approach to adjust the pruning budget across different denoising timesteps for better generation quality. Extensive evaluations show that AT-EDM performs favorably against prior art in terms of efficiency (e.g., 38.8% FLOPs saving and up to 1.53x speed-up over Stable Diffusion XL) while maintaining nearly the same FID and CLIP scores as the full model. Project webpage: https://atedm.github.io.
Exploring Communication Technologies, Standards, and Challenges in Electrified Vehicle Charging
Mar 25, 2024

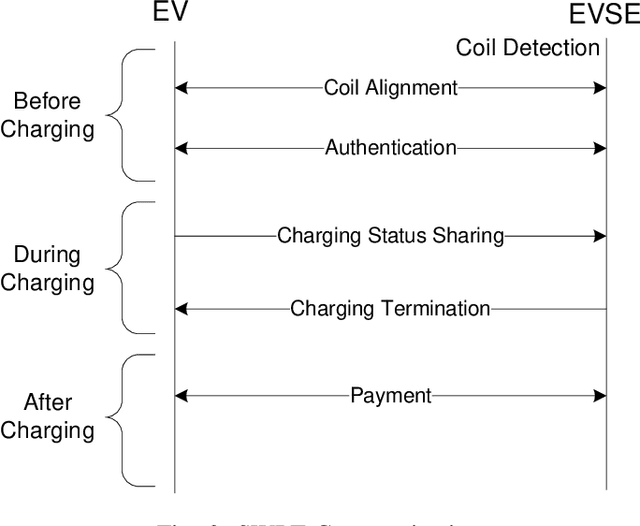
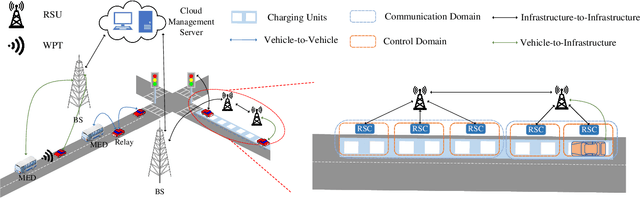
As public awareness of environmental protection continues to grow, the trend of integrating more electric vehicles (EVs) into the transportation sector is rising. Unlike conventional internal combustion engine (ICE) vehicles, EVs can minimize carbon emissions and potentially achieve autonomous driving. However, several obstacles hinder the widespread adoption of EVs, such as their constrained driving range and the extended time required for charging. One alternative solution to address these challenges is implementing dynamic wireless power transfer (DWPT), charging EVs in motion on the road. Moreover, charging stations with static wireless power transfer (SWPT) infrastructure can replace existing gas stations, enabling users to charge EVs in parking lots or at home. This paper surveys the communication infrastructure for static and dynamic wireless charging in electric vehicles. It encompasses all communication aspects involved in the wireless charging process. The architecture and communication requirements for static and dynamic wireless charging are presented separately. Additionally, a comprehensive comparison of existing communication standards is provided. The communication with the grid is also explored in detail. The survey gives attention to security and privacy issues arising during communications. In summary, the paper addresses the challenges and outlines upcoming trends in communication for EV wireless charging.
Zero-TPrune: Zero-Shot Token Pruning through Leveraging of the Attention Graph in Pre-Trained Transformers
May 27, 2023



Deployment of Transformer models on the edge is increasingly challenging due to the exponentially growing model size and inference cost that scales quadratically with the number of tokens in the input sequence. Token pruning is an emerging solution to address this challenge due to its ease of deployment on various Transformer backbones. However, most token pruning methods require a computationally-expensive fine-tuning process after or during pruning, which is not desirable in many cases. Some recent works explore pruning of off-the-shelf pre-trained Transformers without fine-tuning. However, they only take the importance of tokens into consideration. In this work, we propose Zero-TPrune, the first zero-shot method that considers both the importance and similarity of tokens in performing token pruning. Zero-TPrune leverages the attention graph of pre-trained Transformer models to produce an importance rank for tokens and removes the less informative tokens. The attention matrix can be thought of as an adjacency matrix of a directed graph, to which a graph shift operator can be applied iteratively to obtain the importance score distribution. This distribution guides the partition of tokens into two groups and measures similarity between them. Due to the elimination of the fine-tuning overhead, Zero-TPrune can easily prune large models and perform hyperparameter tuning efficiently. We evaluate the performance of Zero-TPrune on vision tasks by applying it to various vision Transformer backbones. Compared with state-of-the-art pruning methods that require fine-tuning, Zero-TPrune not only eliminates the need for fine-tuning after pruning, but does so with only around 0.3% accuracy loss. Compared with state-of-the-art fine-tuning-free pruning methods, Zero-TPrune reduces accuracy loss by up to 45% on medium-sized models.
A New MRAM-based Process In-Memory Accelerator for Efficient Neural Network Training with Floating Point Precision
Mar 02, 2020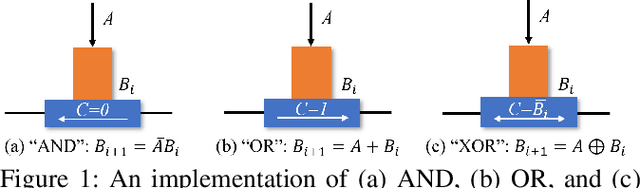
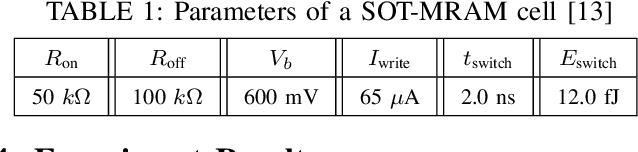
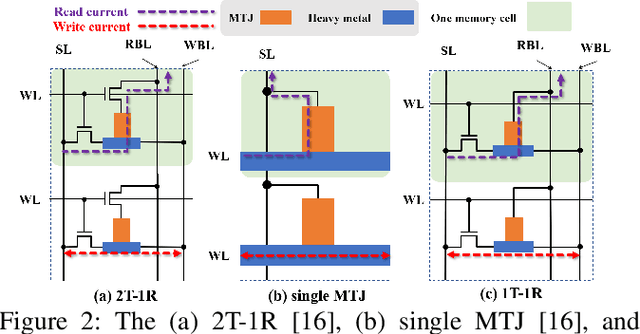
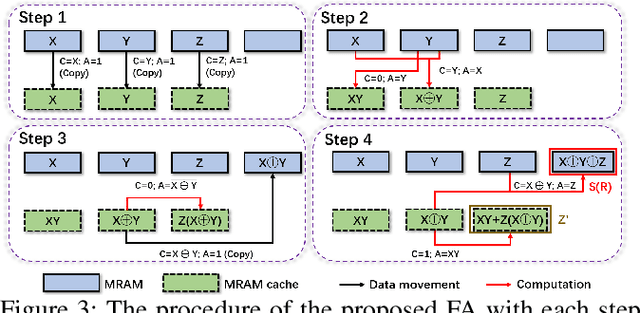
The excellent performance of modern deep neural networks (DNNs) comes at an often prohibitive training cost, limiting the rapid development of DNN innovations and raising various environmental concerns. To reduce the dominant data movement cost of training, process in-memory (PIM) has emerged as a promising solution as it alleviates the need to access DNN weights. However, state-of-the-art PIM DNN training accelerators employ either analog/mixed signal computing which has limited precision or digital computing based on a memory technology that supports limited logic functions and thus requires complicated procedure to realize floating point computation. In this paper, we propose a spin orbit torque magnetic random access memory (SOT-MRAM) based digital PIM accelerator that supports floating point precision. Specifically, this new accelerator features an innovative (1) SOT-MRAM cell, (2) full addition design, and (3) floating point computation. Experiment results show that the proposed SOT-MRAM PIM based DNN training accelerator can achieve 3.3x, 1.8x, and 2.5x improvement in terms of energy, latency, and area, respectively, compared with a state-of-the-art PIM based DNN training accelerator.