 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-TPrune: Zero-Shot Token Pruning through Leveraging of the Attention Graph in Pre-Trained Transformers
May 27, 2023



Deployment of Transformer models on the edge is increasingly challenging due to the exponentially growing model size and inference cost that scales quadratically with the number of tokens in the input sequence. Token pruning is an emerging solution to address this challenge due to its ease of deployment on various Transformer backbones. However, most token pruning methods require a computationally-expensive fine-tuning process after or during pruning, which is not desirable in many cases. Some recent works explore pruning of off-the-shelf pre-trained Transformers without fine-tuning. However, they only take the importance of tokens into consideration. In this work, we propose Zero-TPrune, the first zero-shot method that considers both the importance and similarity of tokens in performing token pruning. Zero-TPrune leverages the attention graph of pre-trained Transformer models to produce an importance rank for tokens and removes the less informative tokens. The attention matrix can be thought of as an adjacency matrix of a directed graph, to which a graph shift operator can be applied iteratively to obtain the importance score distribution. This distribution guides the partition of tokens into two groups and measures similarity between them. Due to the elimination of the fine-tuning overhead, Zero-TPrune can easily prune large models and perform hyperparameter tuning efficiently. We evaluate the performance of Zero-TPrune on vision tasks by applying it to various vision Transformer backbones. Compared with state-of-the-art pruning methods that require fine-tuning, Zero-TPrune not only eliminates the need for fine-tuning after pruning, but does so with only around 0.3% accuracy loss. Compared with state-of-the-art fine-tuning-free pruning methods, Zero-TPrune reduces accuracy loss by up to 45% on medium-sized models.
Im-Promptu: In-Context Composition from Image Prompts
May 26, 2023



Large language models are few-shot learners that can solve diverse tasks from a handful of demonstrations. This implicit understanding of tasks suggests that the attention mechanisms over word tokens may play a role in analogical reasoning. In this work, we investigate whether analogical reasoning can enable in-context composition over composable elements of visual stimuli. First, we introduce a suite of three benchmarks to test the generalization properties of a visual in-context learner. We formalize the notion of an analogy-based in-context learner and use it to design a meta-learning framework called Im-Promptu. Whereas the requisite token granularity for language is well established, the appropriate compositional granularity for enabling in-context generalization in visual stimuli is usually unspecified. To this end, we use Im-Promptu to train multiple agents with different levels of compositionality, including vector representations, patch representations, and object slots. Our experiments reveal tradeoffs between extrapolation abilities and the degree of compositionality, with non-compositional representations extending learned composition rules to unseen domains but performing poorly on combinatorial tasks. Patch-based representations require patches to contain entire objects for robust extrapolation. At the same time, object-centric tokenizers coupled with a cross-attention module generate consistent and high-fidelity solutions, with these inductive biases being particularly crucial for compositional generalization. Lastly, we demonstrate a use case of Im-Promptu as an intuitive programming interface for image generation.
SCouT: Synthetic Counterfactuals via Spatiotemporal Transformers for Actionable Healthcare
Jul 09, 2022



The Synthetic Control method has pioneered a class of powerful data-driven techniques to estimate the counterfactual reality of a unit from donor units. At its core, the technique involves a linear model fitted on the pre-intervention period that combines donor outcomes to yield the counterfactual. However, linearly combining spatial information at each time instance using time-agnostic weights fails to capture important inter-unit and intra-unit temporal contexts and complex nonlinear dynamics of real data. We instead propose an approach to use local spatiotemporal information before the onset of the intervention as a promising way to estimate the counterfactual sequence. To this end, we suggest a Transformer model that leverages particular positional embeddings, a modified decoder attention mask, and a novel pre-training task to perform spatiotemporal sequence-to-sequence modeling. Our experiments on synthetic data demonstrate the efficacy of our method in the typical small donor pool setting and its robustness against noise. We also generate actionable healthcare insights at the population and patient levels by simulating a state-wide public health policy to evaluate its effectiveness, an in silico trial for asthma medications to support randomized controlled trials, and a medical intervention for patients with Friedreich's ataxia to improve clinical decision-making and promote personalized therapy.
FlexiBERT: Are Current Transformer Architectures too Homogeneous and Rigid?
May 23, 2022
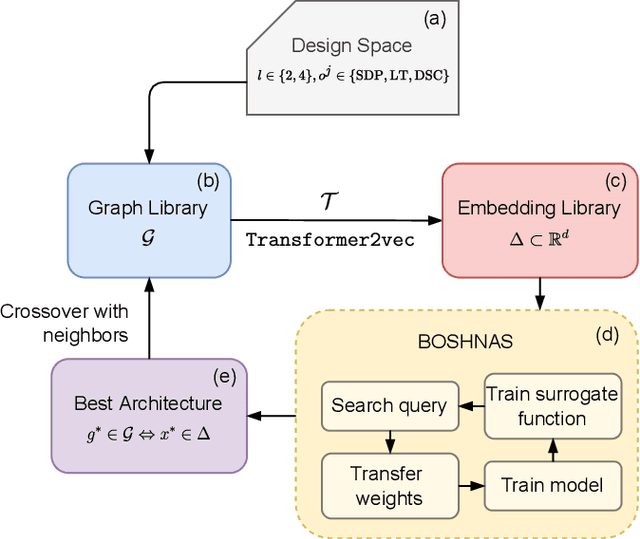
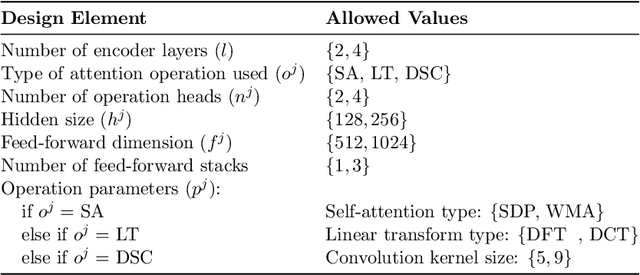
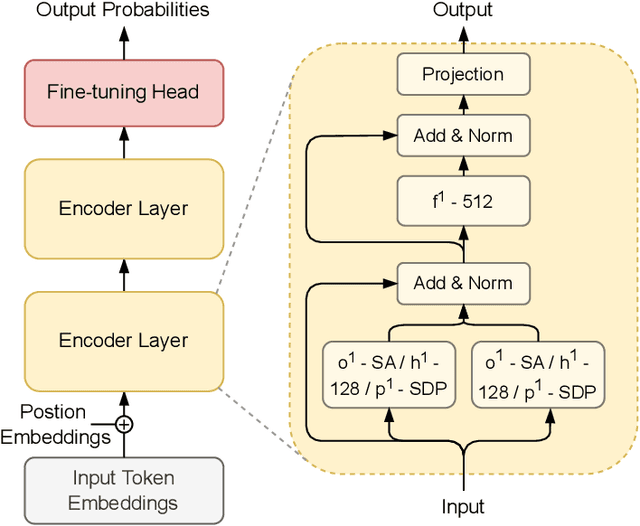
The existence of a plethora of language models makes the problem of selecting the best one for a custom task challenging. Most state-of-the-art methods leverage transformer-based models (e.g., BERT) or their variants. Training such models and exploring their hyperparameter space, however, is computationally expensive. Prior work proposes several neural architecture search (NAS) methods that employ performance predictors (e.g., surrogate models) to address this issue; however, analysis has been limited to homogeneous models that use fixed dimensionality throughout the network. This leads to sub-optimal architectures. To address this limitation, we propose a suite of heterogeneous and flexible models, namely FlexiBERT, that have varied encoder layers with a diverse set of possible operations and different hidden dimensions. For better-posed surrogate modeling in this expanded design space, we propose a new graph-similarity-based embedding scheme. We also propose a novel NAS policy, called BOSHNAS, that leverages this new scheme, Bayesian modeling, and second-order optimization, to quickly train and use a neural surrogate model to converge to the optimal architecture. A comprehensive set of experiments shows that the proposed policy, when applied to the FlexiBERT design space, pushes the performance frontier upwards compared to traditional models. FlexiBERT-Mini, one of our proposed models, has 3% fewer parameters than BERT-Mini and achieves 8.9% higher GLUE score. A FlexiBERT model with equivalent performance as the best homogeneous model achieves 2.6x smaller size. FlexiBERT-Large, another proposed model, achieves state-of-the-art results, outperforming the baseline models by at least 5.7% on the GLUE benchmark.
Lower Bounds for Policy Iteration on Multi-action MDPs
Sep 16, 2020
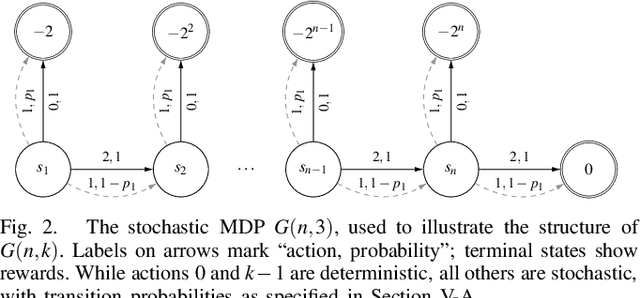

Policy Iteration (PI) is a classical family of algorithms to compute an optimal policy for any given Markov Decision Problem (MDP). The basic idea in PI is to begin with some initial policy and to repeatedly update the policy to one from an improving set, until an optimal policy is reached. Different variants of PI result from the (switching) rule used for improvement. An important theoretical question is how many iterations a specified PI variant will take to terminate as a function of the number of states $n$ and the number of actions $k$ in the input MDP. While there has been considerable progress towards upper-bounding this number, there are fewer results on lower bounds. In particular, existing lower bounds primarily focus on the special case of $k = 2$ actions. We devise lower bounds for $k \geq 3$. Our main result is that a particular variant of PI can take $\Omega(k^{n/2})$ iterations to terminate. We also generalise existing constructions on $2$-action MDPs to scale lower bounds by a factor of $k$ for some common deterministic variants of PI, and by $\log(k)$ for corresponding randomised variants.
Analysis of Lower Bounds for Simple Policy Iteration
Nov 28, 2019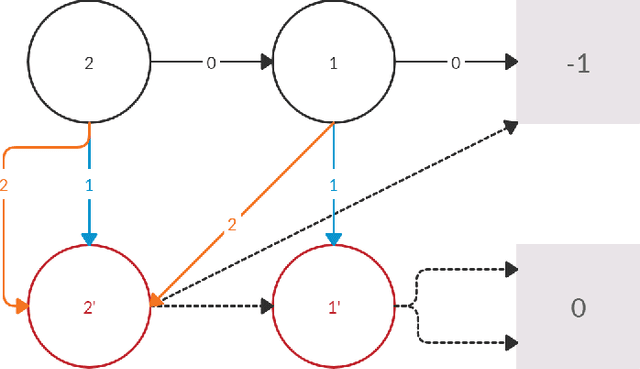
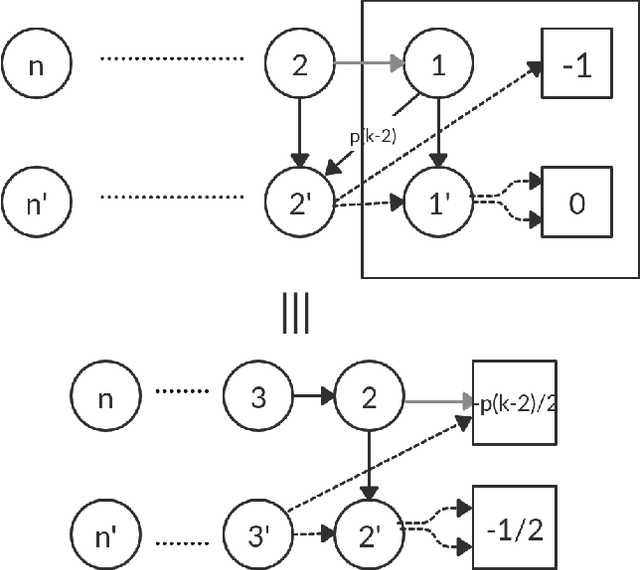
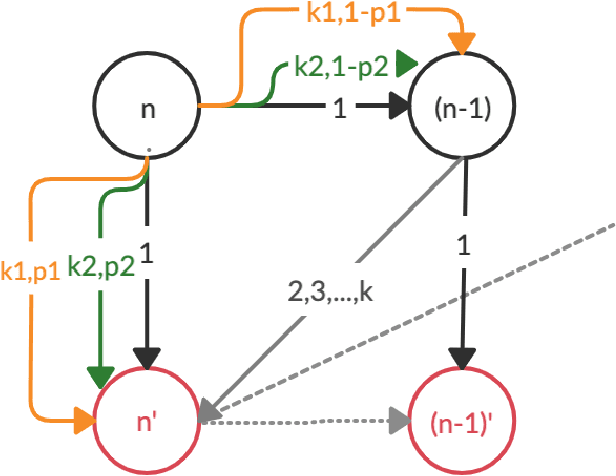
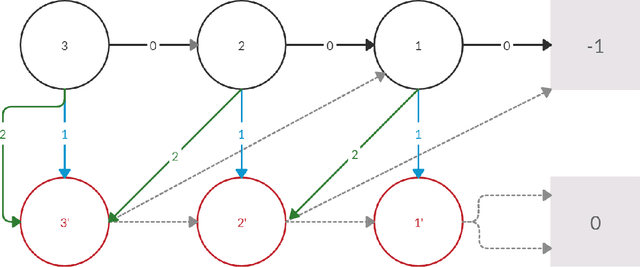
Policy iteration is a family of algorithms that are used to find an optimal policy for a given Markov Decision Problem (MDP). Simple Policy iteration (SPI) is a type of policy iteration where the strategy is to change the policy at exactly one improvable state at every step. Melekopoglou and Condon [1990] showed an exponential lower bound on the number of iterations taken by SPI for a 2 action MDP. The results have not been generalized to $k-$action MDP since. In this paper, we revisit the algorithm and the analysis done by Melekopoglou and Condon. We generalize the previous result and prove a novel exponential lower bound on the number of iterations taken by policy iteration for $N-$state, $k-$action MDPs. We construct a family of MDPs and give an index-based switching rule that yields a strong lower bound of $\mathcal{O}\big((3+k)2^{N/2-3}\big)$.