 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAGMol: Target-Aware Gradient-guided Molecule Generation
Jun 03, 2024



3D generative models have shown significant promise in structure-based drug design (SBDD), particularly in discovering ligands tailored to specific target binding sites. Existing algorithms often focus primarily on ligand-target binding, characterized by binding affinity. Moreover, models trained solely on target-ligand distribution may fall short in addressing the broader objectives of drug discovery, such as the development of novel ligands with desired properties like drug-likeness, and synthesizability, underscoring the multifaceted nature of the drug design process. To overcome these challenges, we decouple the problem into molecular generation and property prediction. The latter synergistically guides the diffusion sampling process, facilitating guided diffusion and resulting in the creation of meaningful molecules with the desired properties. We call this guided molecular generation process as TAGMol. Through experiments on benchmark datasets, TAGMol demonstrates superior performance compared to state-of-the-art baselines, achieving a 22% improvement in average Vina Score and yielding favorable outcomes in essential auxiliary properties. This establishes TAGMol as a comprehensive framework for drug generation.
Uncertainty-aware Active Learning of NeRF-based Object Models for Robot Manipulators using Visual and Re-orientation Actions
Apr 02, 2024



Manipulating unseen objects is challenging without a 3D representation, as objects generally have occluded surfaces. This requires physical interaction with objects to build their internal representations. This paper presents an approach that enables a robot to rapidly learn the complete 3D model of a given object for manipulation in unfamiliar orientations. We use an ensemble of partially constructed NeRF models to quantify model uncertainty to determine the next action (a visual or re-orientation action) by optimizing informativeness and feasibility. Further, our approach determines when and how to grasp and re-orient an object given its partial NeRF model and re-estimates the object pose to rectify misalignments introduced during the interaction. Experiments with a simulated Franka Emika Robot Manipulator operating in a tabletop environment with benchmark objects demonstrate an improvement of (i) 14% in visual reconstruction quality (PSNR), (ii) 20% in the geometric/depth reconstruction of the object surface (F-score) and (iii) 71% in the task success rate of manipulating objects a-priori unseen orientations/stable configurations in the scene; over current methods. The project page can be found here: https://actnerf.github.io.
PhyPlan: Compositional and Adaptive Physical Task Reasoning with Physics-Informed Skill Networks for Robot Manipulators
Feb 24, 2024



Given the task of positioning a ball-like object to a goal region beyond direct reach, humans can often throw, slide, or rebound objects against the wall to attain the goal. However, enabling robots to reason similarly is non-trivial. Existing methods for physical reasoning are data-hungry and struggle with complexity and uncertainty inherent in the real world. This paper presents PhyPlan, a novel physics-informed planning framework that combines physics-informed neural networks (PINNs) with modified Monte Carlo Tree Search (MCTS) to enable embodied agents to perform dynamic physical tasks. PhyPlan leverages PINNs to simulate and predict outcomes of actions in a fast and accurate manner and uses MCTS for planning. It dynamically determines whether to consult a PINN-based simulator (coarse but fast) or engage directly with the actual environment (fine but slow) to determine optimal policy. Evaluation with robots in simulated 3D environments demonstrates the ability of our approach to solve 3D-physical reasoning tasks involving the composition of dynamic skills. Quantitatively, PhyPlan excels in several aspects: (i) it achieves lower regret when learning novel tasks compared to state-of-the-art, (ii) it expedites skill learning and enhances the speed of physical reasoning, (iii) it demonstrates higher data efficiency compared to a physics un-informed approach.
CILP: Co-simulation based Imitation Learner for Dynamic Resource Provisioning in Cloud Computing Environments
Feb 11, 2023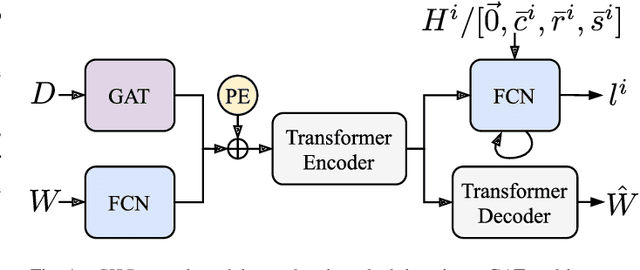

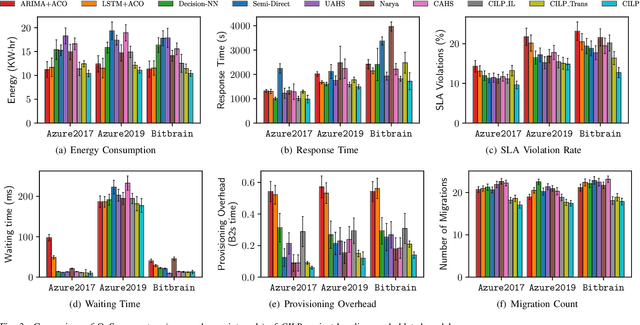

Intelligent Virtual Machine (VM) provisioning is central to cost and resource efficient computation in cloud computing environments. As bootstrapping VMs is time-consuming, a key challenge for latency-critical tasks is to predict future workload demands to provision VMs proactively. However, existing AI-based solutions \blue{tend to not holistically consider} all crucial aspects such as provisioning overheads, heterogeneous VM costs and Quality of Service (QoS) of the cloud system. To address this, we propose a novel method, called CILP, that formulates the VM provisioning problem as two sub-problems of prediction and optimization, where the provisioning plan is optimized based on predicted workload demands. CILP leverages a neural network as a surrogate model to predict future workload demands with a co-simulated digital-twin of the infrastructure to compute QoS scores. We extend the neural network to also act as an imitation learner that dynamically decides the optimal VM provisioning plan. A transformer based neural model reduces training and inference overheads while our novel two-phase decision making loop facilitates in making informed provisioning decisions. Crucially, we address limitations of prior work by including resource utilization, deployment costs and provisioning overheads to inform the provisioning decisions in our imitation learning framework. Experiments with three public benchmarks demonstrate that CILP gives up to 22% higher resource utilization, 14% higher QoS scores and 44% lower execution costs compared to the current online and offline optimization based state-of-the-art methods.
DeepFT: Fault-Tolerant Edge Computing using a Self-Supervised Deep Surrogate Model
Dec 02, 2022The emergence of latency-critical AI applications has been supported by the evolution of the edge computing paradigm. However, edge solutions are typically resource-constrained, posing reliability challenges due to heightened contention for compute and communication capacities and faulty application behavior in the presence of overload conditions. Although a large amount of generated log data can be mined for fault prediction, labeling this data for training is a manual process and thus a limiting factor for automation. Due to this, many companies resort to unsupervised fault-tolerance models. Yet, failure models of this kind can incur a loss of accuracy when they need to adapt to non-stationary workloads and diverse host characteristics. To cope with this, we propose a novel modeling approach, called DeepFT, to proactively avoid system overloads and their adverse effects by optimizing the task scheduling and migration decisions. DeepFT uses a deep surrogate model to accurately predict and diagnose faults in the system and co-simulation based self-supervised learning to dynamically adapt the model in volatile settings. It offers a highly scalable solution as the model size scales by only 3 and 1 percent per unit increase in the number of active tasks and hosts. Extensive experimentation on a Raspberry-Pi based edge cluster with DeFog benchmarks shows that DeepFT can outperform state-of-the-art baseline methods in fault-detection and QoS metrics. Specifically, DeepFT gives the highest F1 scores for fault-detection, reducing service deadline violations by up to 37\% while also improving response time by up to 9%.
DRAGON: Decentralized Fault Tolerance in Edge Federations
Aug 16, 2022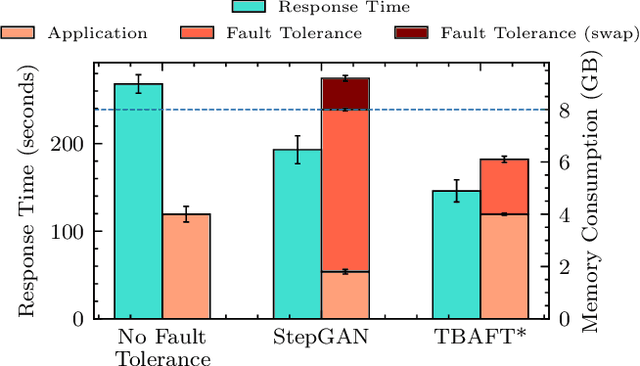
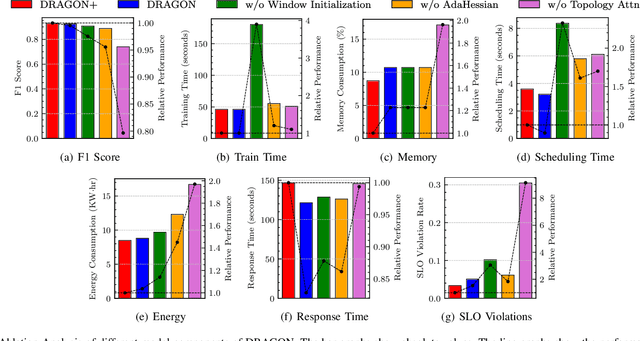
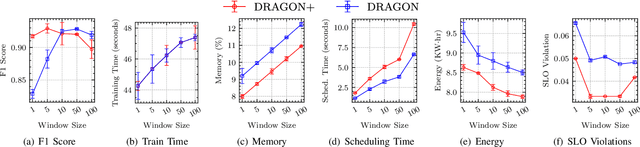
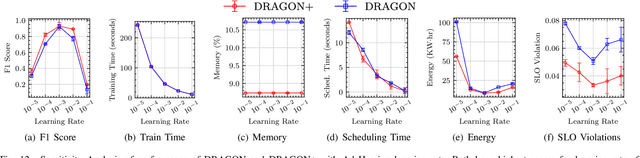
Edge Federation is a new computing paradigm that seamlessly interconnects the resources of multiple edge service providers. A key challenge in such systems is the deployment of latency-critical and AI based resource-intensive applications in constrained devices. To address this challenge, we propose a novel memory-efficient deep learning based model, namely generative optimization networks (GON). Unlike GANs, GONs use a single network to both discriminate input and generate samples, significantly reducing their memory footprint. Leveraging the low memory footprint of GONs, we propose a decentralized fault-tolerance method called DRAGON that runs simulations (as per a digital modeling twin) to quickly predict and optimize the performance of the edge federation. Extensive experiments with real-world edge computing benchmarks on multiple Raspberry-Pi based federated edge configurations show that DRAGON can outperform the baseline methods in fault-detection and Quality of Service (QoS) metrics. Specifically, the proposed method gives higher F1 scores for fault-detection than the best deep learning (DL) method, while consuming lower memory than the heuristic methods. This allows for improvement in energy consumption, response time and service level agreement violations by up to 74, 63 and 82 percent, respectively.
ToolTango: Common sense Generalization in Predicting Sequential Tool Interactions for Robot Plan Synthesis
Jun 18, 2022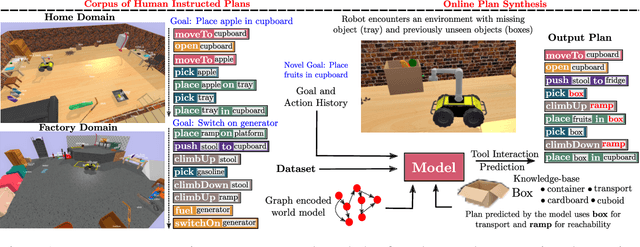
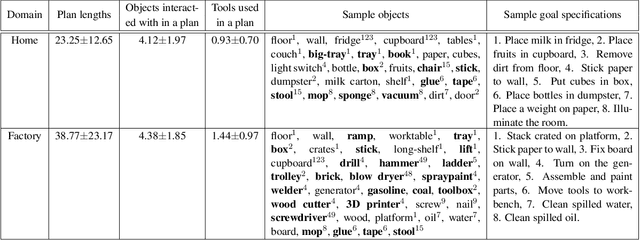
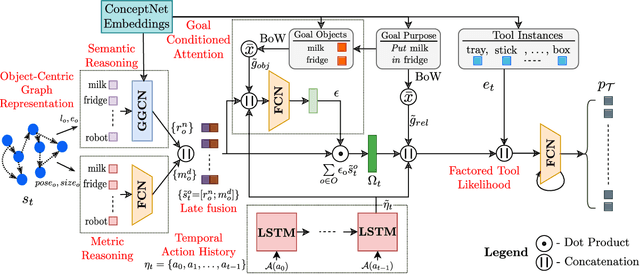

Robots assisting us in environments such as factories or homes must learn to make use of objects as tools to perform tasks, for instance using a tray to carry objects. We consider the problem of learning commonsense knowledge of when a tool may be useful and how its use may be composed with other tools to accomplish a high-level task instructed by a human. Specifically, we introduce a novel neural model, termed TOOLTANGO, that first predicts the next tool to be used, and then uses this information to predict the next action. We show that this joint model can inform learning of a fine-grained policy enabling the robot to use a particular tool in sequence and adds a significant value in making the model more accurate. TOOLTANGO encodes the world state, comprising objects and symbolic relationships between them, using a graph neural network and is trained using demonstrations from human teachers instructing a virtual robot in a physics simulator. The model learns to attend over the scene using knowledge of the goal and the action history, finally decoding the symbolic action to execute. Crucially, we address generalization to unseen environments where some known tools are missing, but alternative unseen tools are present. We show that by augmenting the representation of the environment with pre-trained embeddings derived from a knowledge-base, the model can generalize effectively to novel environments. Experimental results show at least 48.8-58.1% absolute improvement over the baselines in predicting successful symbolic plans for a simulated mobile manipulator in novel environments with unseen objects. This work takes a step in the direction of enabling robots to rapidly synthesize robust plans for complex tasks, particularly in novel settings
RadNet: Incident Prediction in Spatio-Temporal Road Graph Networks Using Traffic Forecasting
Jun 11, 2022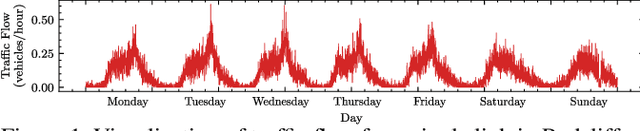

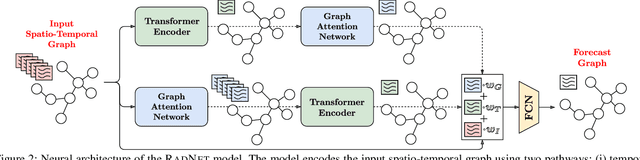

Efficient and accurate incident prediction in spatio-temporal systems is critical to minimize service downtime and optimize performance. This work aims to utilize historic data to predict and diagnose incidents using spatio-temporal forecasting. We consider the specific use case of road traffic systems where incidents take the form of anomalous events, such as accidents or broken-down vehicles. To tackle this, we develop a neural model, called RadNet, which forecasts system parameters such as average vehicle speeds for a future timestep. As such systems largely follow daily or weekly periodicity, we compare RadNet's predictions against historical averages to label incidents. Unlike prior work, RadNet infers spatial and temporal trends in both permutations, finally combining the dense representations before forecasting. This facilitates informed inference and more accurate incident detection. Experiments with two publicly available and a new road traffic dataset demonstrate that the proposed model gives up to 8% higher prediction F1 scores compared to the state-of-the-art methods.
FlexiBERT: Are Current Transformer Architectures too Homogeneous and Rigid?
May 23, 2022
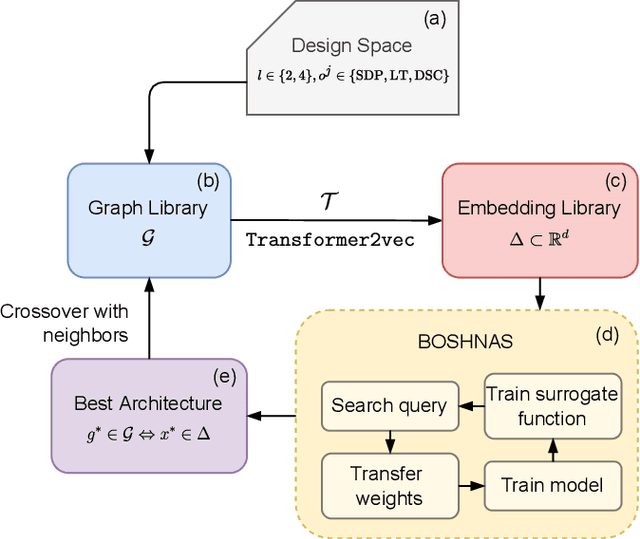
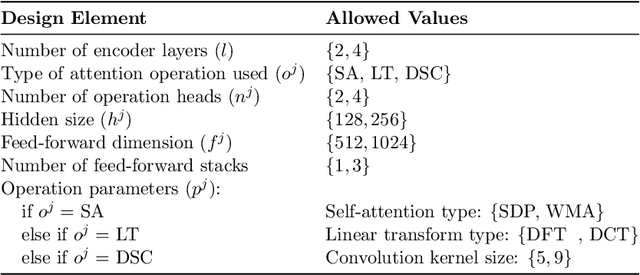
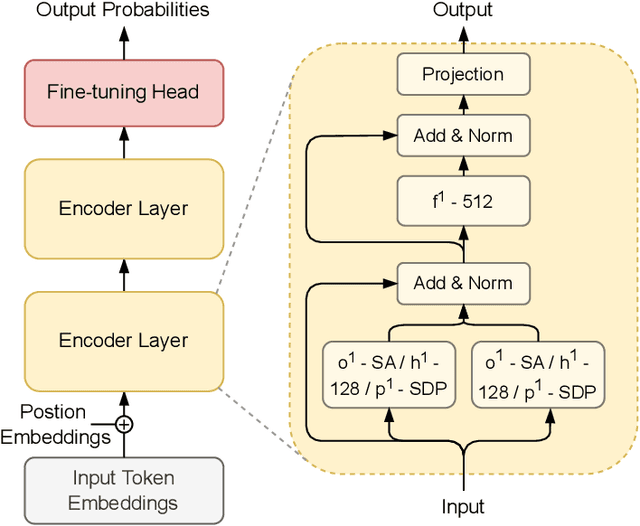
The existence of a plethora of language models makes the problem of selecting the best one for a custom task challenging. Most state-of-the-art methods leverage transformer-based models (e.g., BERT) or their variants. Training such models and exploring their hyperparameter space, however, is computationally expensive. Prior work proposes several neural architecture search (NAS) methods that employ performance predictors (e.g., surrogate models) to address this issue; however, analysis has been limited to homogeneous models that use fixed dimensionality throughout the network. This leads to sub-optimal architectures. To address this limitation, we propose a suite of heterogeneous and flexible models, namely FlexiBERT, that have varied encoder layers with a diverse set of possible operations and different hidden dimensions. For better-posed surrogate modeling in this expanded design space, we propose a new graph-similarity-based embedding scheme. We also propose a novel NAS policy, called BOSHNAS, that leverages this new scheme, Bayesian modeling, and second-order optimization, to quickly train and use a neural surrogate model to converge to the optimal architecture. A comprehensive set of experiments shows that the proposed policy, when applied to the FlexiBERT design space, pushes the performance frontier upwards compared to traditional models. FlexiBERT-Mini, one of our proposed models, has 3% fewer parameters than BERT-Mini and achieves 8.9% higher GLUE score. A FlexiBERT model with equivalent performance as the best homogeneous model achieves 2.6x smaller size. FlexiBERT-Large, another proposed model, achieves state-of-the-art results, outperforming the baseline models by at least 5.7% on the GLUE benchmark.
MetaNet: Automated Dynamic Selection of Scheduling Policies in Cloud Environments
May 21, 2022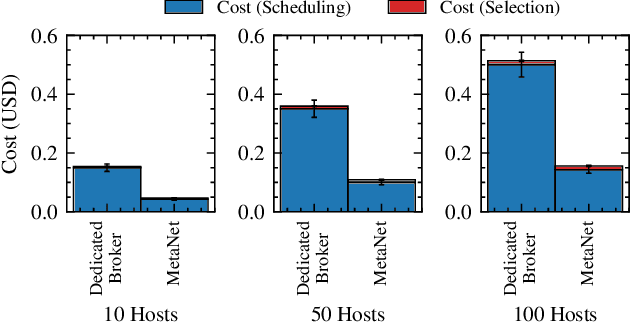
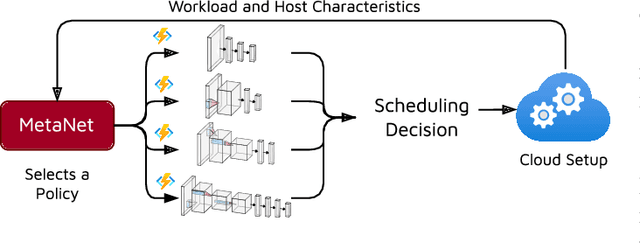
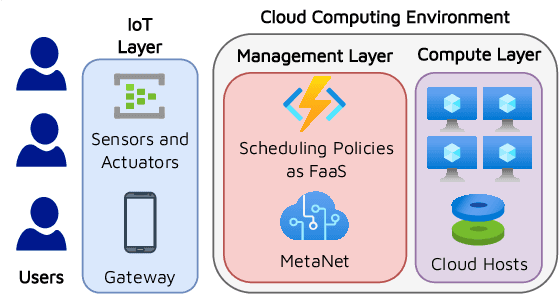
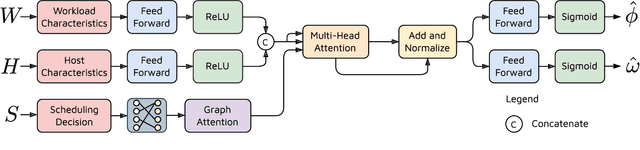
Task scheduling is a well-studied problem in the context of optimizing the Quality of Service (QoS) of cloud computing environments. In order to sustain the rapid growth of computational demands, one of the most important QoS metrics for cloud schedulers is the execution cost. In this regard, several data-driven deep neural networks (DNNs) based schedulers have been proposed in recent years to allow scalable and efficient resource management in dynamic workload settings. However, optimal scheduling frequently relies on sophisticated DNNs with high computational needs implying higher execution costs. Further, even in non-stationary environments, sophisticated schedulers might not always be required and we could briefly rely on low-cost schedulers in the interest of cost-efficiency. Therefore, this work aims to solve the non-trivial meta problem of online dynamic selection of a scheduling policy using a surrogate model called MetaNet. Unlike traditional solutions with a fixed scheduling policy, MetaNet on-the-fly chooses a scheduler from a large set of DNN based methods to optimize task scheduling and execution costs in tandem. Compared to state-of-the-art DNN schedulers, this allows for improvement in execution costs, energy consumption, response time and service level agreement violations by up to 11, 43, 8 and 13 percent, respectively.