 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC2F-Space: Coarse-to-Fine Space Grounding for Spatial Instructions using Vision-Language Models
Nov 19, 2025Space grounding refers to localizing a set of spatial references described in natural language instructions. Traditional methods often fail to account for complex reasoning -- such as distance, geometry, and inter-object relationships -- while vision-language models (VLMs), despite strong reasoning abilities, struggle to produce a fine-grained region of outputs. To overcome these limitations, we propose C2F-Space, a novel coarse-to-fine space-grounding framework that (i) estimates an approximated yet spatially consistent region using a VLM, then (ii) refines the region to align with the local environment through superpixelization. For the coarse estimation, we design a grid-based visual-grounding prompt with a propose-validate strategy, maximizing VLM's spatial understanding and yielding physically and semantically valid canonical region (i.e., ellipses). For the refinement, we locally adapt the region to surrounding environment without over-relaxed to free space. We construct a new space-grounding benchmark and compare C2F-Space with five state-of-the-art baselines using success rate and intersection-over-union. Our C2F-Space significantly outperforms all baselines. Our ablation study confirms the effectiveness of each module in the two-step process and their synergistic effect of the combined framework. We finally demonstrate the applicability of C2F-Space to simulated robotic pick-and-place tasks.
G$^{2}$TR: Generalized Grounded Temporal Reasoning for Robot Instruction Following by Combining Large Pre-trained Models
Oct 10, 2024Consider the scenario where a human cleans a table and a robot observing the scene is instructed with the task "Remove the cloth using which I wiped the table". Instruction following with temporal reasoning requires the robot to identify the relevant past object interaction, ground the object of interest in the present scene, and execute the task according to the human's instruction. Directly grounding utterances referencing past interactions to grounded objects is challenging due to the multi-hop nature of references to past interactions and large space of object groundings in a video stream observing the robot's workspace. Our key insight is to factor the temporal reasoning task as (i) estimating the video interval associated with event reference, (ii) performing spatial reasoning over the interaction frames to infer the intended object (iii) semantically track the object's location till the current scene to enable future robot interactions. Our approach leverages existing large pre-trained models (which possess inherent generalization capabilities) and combines them appropriately for temporal grounding tasks. Evaluation on a video-language corpus acquired with a robot manipulator displaying rich temporal interactions in spatially-complex scenes displays an average accuracy of 70.10%. The dataset, code, and videos are available at https://reail-iitdelhi.github.io/temporalreasoning.github.io/ .
Learning to Recover from Plan Execution Errors during Robot Manipulation: A Neuro-symbolic Approach
May 29, 2024

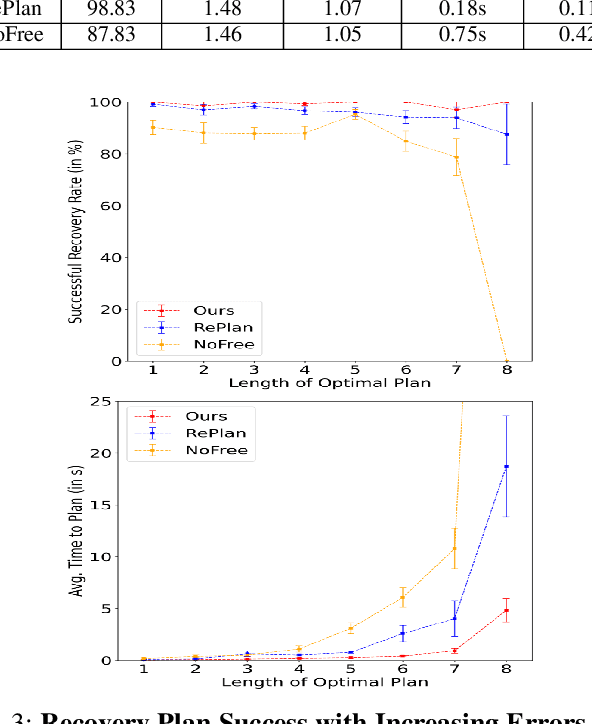

Automatically detecting and recovering from failures is an important but challenging problem for autonomous robots. Most of the recent work on learning to plan from demonstrations lacks the ability to detect and recover from errors in the absence of an explicit state representation and/or a (sub-) goal check function. We propose an approach (blending learning with symbolic search) for automated error discovery and recovery, without needing annotated data of failures. Central to our approach is a neuro-symbolic state representation, in the form of dense scene graph, structured based on the objects present within the environment. This enables efficient learning of the transition function and a discriminator that not only identifies failures but also localizes them facilitating fast re-planning via computation of heuristic distance function. We also present an anytime version of our algorithm, where instead of recovering to the last correct state, we search for a sub-goal in the original plan minimizing the total distance to the goal given a re-planning budget. Experiments on a physics simulator with a variety of simulated failures show the effectiveness of our approach compared to existing baselines, both in terms of efficiency as well as accuracy of our recovery mechanism.
Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation
Apr 11, 2024



Our goal is to build embodied agents that can learn inductively generalizable spatial concepts in a continual manner, e.g, constructing a tower of a given height. Existing work suffers from certain limitations (a) (Liang et al., 2023) and their multi-modal extensions, rely heavily on prior knowledge and are not grounded in the demonstrations (b) (Liu et al., 2023) lack the ability to generalize due to their purely neural approach. A key challenge is to achieve a fine balance between symbolic representations which have the capability to generalize, and neural representations that are physically grounded. In response, we propose a neuro-symbolic approach by expressing inductive concepts as symbolic compositions over grounded neural concepts. Our key insight is to decompose the concept learning problem into the following steps 1) Sketch: Getting a programmatic representation for the given instruction 2) Plan: Perform Model-Based RL over the sequence of grounded neural action concepts to learn a grounded plan 3) Generalize: Abstract out a generic (lifted) Python program to facilitate generalizability. Continual learning is achieved by interspersing learning of grounded neural concepts with higher level symbolic constructs. Our experiments demonstrate that our approach significantly outperforms existing baselines in terms of its ability to learn novel concepts and generalize inductively.
Uncertainty-aware Active Learning of NeRF-based Object Models for Robot Manipulators using Visual and Re-orientation Actions
Apr 02, 2024



Manipulating unseen objects is challenging without a 3D representation, as objects generally have occluded surfaces. This requires physical interaction with objects to build their internal representations. This paper presents an approach that enables a robot to rapidly learn the complete 3D model of a given object for manipulation in unfamiliar orientations. We use an ensemble of partially constructed NeRF models to quantify model uncertainty to determine the next action (a visual or re-orientation action) by optimizing informativeness and feasibility. Further, our approach determines when and how to grasp and re-orient an object given its partial NeRF model and re-estimates the object pose to rectify misalignments introduced during the interaction. Experiments with a simulated Franka Emika Robot Manipulator operating in a tabletop environment with benchmark objects demonstrate an improvement of (i) 14% in visual reconstruction quality (PSNR), (ii) 20% in the geometric/depth reconstruction of the object surface (F-score) and (iii) 71% in the task success rate of manipulating objects a-priori unseen orientations/stable configurations in the scene; over current methods. The project page can be found here: https://actnerf.github.io.
PhyPlan: Compositional and Adaptive Physical Task Reasoning with Physics-Informed Skill Networks for Robot Manipulators
Feb 24, 2024



Given the task of positioning a ball-like object to a goal region beyond direct reach, humans can often throw, slide, or rebound objects against the wall to attain the goal. However, enabling robots to reason similarly is non-trivial. Existing methods for physical reasoning are data-hungry and struggle with complexity and uncertainty inherent in the real world. This paper presents PhyPlan, a novel physics-informed planning framework that combines physics-informed neural networks (PINNs) with modified Monte Carlo Tree Search (MCTS) to enable embodied agents to perform dynamic physical tasks. PhyPlan leverages PINNs to simulate and predict outcomes of actions in a fast and accurate manner and uses MCTS for planning. It dynamically determines whether to consult a PINN-based simulator (coarse but fast) or engage directly with the actual environment (fine but slow) to determine optimal policy. Evaluation with robots in simulated 3D environments demonstrates the ability of our approach to solve 3D-physical reasoning tasks involving the composition of dynamic skills. Quantitatively, PhyPlan excels in several aspects: (i) it achieves lower regret when learning novel tasks compared to state-of-the-art, (ii) it expedites skill learning and enhances the speed of physical reasoning, (iii) it demonstrates higher data efficiency compared to a physics un-informed approach.
Learning Neuro-symbolic Programs for Language Guided Robot Manipulation
Nov 12, 2022



Given a natural language instruction, and an input and an output scene, our goal is to train a neuro-symbolic model which can output a manipulation program that can be executed by the robot on the input scene resulting in the desired output scene. Prior approaches for this task possess one of the following limitations: (i) rely on hand-coded symbols for concepts limiting generalization beyond those seen during training [1] (ii) infer action sequences from instructions but require dense sub-goal supervision [2] or (iii) lack semantics required for deeper object-centric reasoning inherent in interpreting complex instructions [3]. In contrast, our approach is neuro-symbolic and can handle linguistic as well as perceptual variations, is end-to-end differentiable requiring no intermediate supervision, and makes use of symbolic reasoning constructs which operate on a latent neural object-centric representation, allowing for deeper reasoning over the input scene. Central to our approach is a modular structure, consisting of a hierarchical instruction parser, and a manipulation module to learn disentangled action representations, both trained via RL. Our experiments on a simulated environment with a 7-DOF manipulator, consisting of instructions with varying number of steps, as well as scenes with different number of objects, and objects with unseen attribute combinations, demonstrate that our model is robust to such variations, and significantly outperforms existing baselines, particularly in generalization settings.
ToolTango: Common sense Generalization in Predicting Sequential Tool Interactions for Robot Plan Synthesis
Jun 18, 2022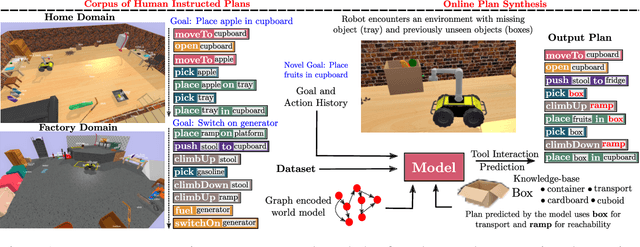
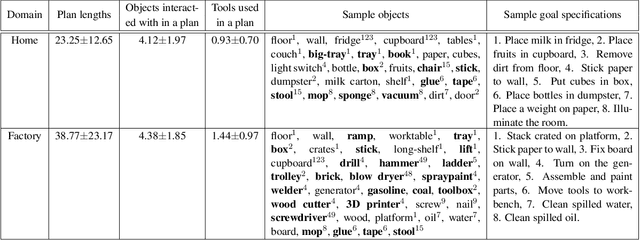
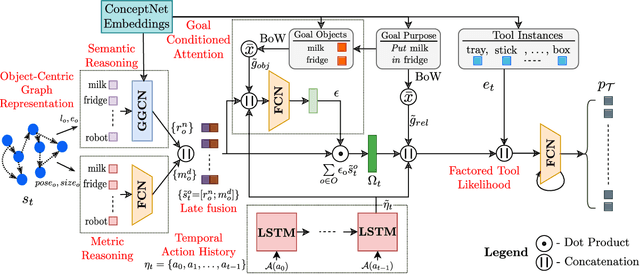

Robots assisting us in environments such as factories or homes must learn to make use of objects as tools to perform tasks, for instance using a tray to carry objects. We consider the problem of learning commonsense knowledge of when a tool may be useful and how its use may be composed with other tools to accomplish a high-level task instructed by a human. Specifically, we introduce a novel neural model, termed TOOLTANGO, that first predicts the next tool to be used, and then uses this information to predict the next action. We show that this joint model can inform learning of a fine-grained policy enabling the robot to use a particular tool in sequence and adds a significant value in making the model more accurate. TOOLTANGO encodes the world state, comprising objects and symbolic relationships between them, using a graph neural network and is trained using demonstrations from human teachers instructing a virtual robot in a physics simulator. The model learns to attend over the scene using knowledge of the goal and the action history, finally decoding the symbolic action to execute. Crucially, we address generalization to unseen environments where some known tools are missing, but alternative unseen tools are present. We show that by augmenting the representation of the environment with pre-trained embeddings derived from a knowledge-base, the model can generalize effectively to novel environments. Experimental results show at least 48.8-58.1% absolute improvement over the baselines in predicting successful symbolic plans for a simulated mobile manipulator in novel environments with unseen objects. This work takes a step in the direction of enabling robots to rapidly synthesize robust plans for complex tasks, particularly in novel settings
GoalNet: Inferring Conjunctive Goal Predicates from Human Plan Demonstrations for Robot Instruction Following
May 14, 2022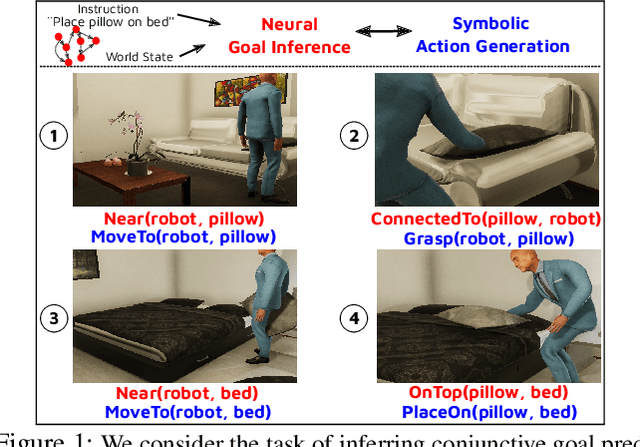

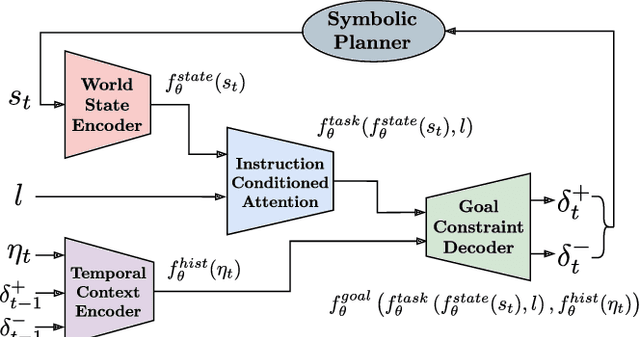
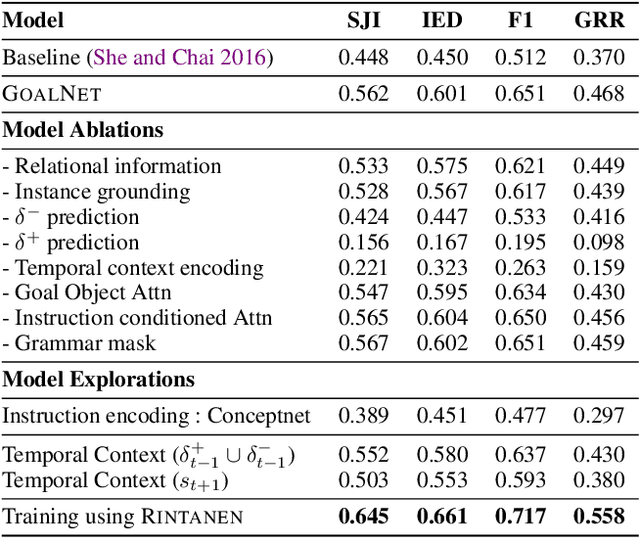
Our goal is to enable a robot to learn how to sequence its actions to perform tasks specified as natural language instructions, given successful demonstrations from a human partner. The ability to plan high-level tasks can be factored as (i) inferring specific goal predicates that characterize the task implied by a language instruction for a given world state and (ii) synthesizing a feasible goal-reaching action-sequence with such predicates. For the former, we leverage a neural network prediction model, while utilizing a symbolic planner for the latter. We introduce a novel neuro-symbolic model, GoalNet, for contextual and task dependent inference of goal predicates from human demonstrations and linguistic task descriptions. GoalNet combines (i) learning, where dense representations are acquired for language instruction and the world state that enables generalization to novel settings and (ii) planning, where the cause-effect modeling by the symbolic planner eschews irrelevant predicates facilitating multi-stage decision making in large domains. GoalNet demonstrates a significant improvement (51%) in the task completion rate in comparison to a state-of-the-art rule-based approach on a benchmark data set displaying linguistic variations, particularly for multi-stage instructions.
TANGO: Commonsense Generalization in Predicting Tool Interactions for Mobile Manipulators
May 23, 2021
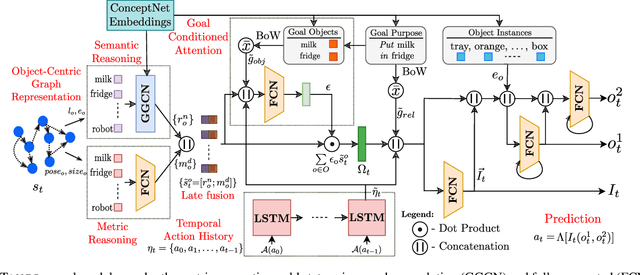
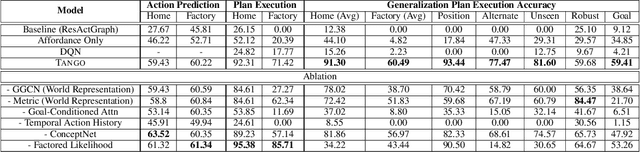
Robots assisting us in factories or homes must learn to make use of objects as tools to perform tasks, e.g., a tray for carrying objects. We consider the problem of learning commonsense knowledge of when a tool may be useful and how its use may be composed with other tools to accomplish a high-level task instructed by a human. We introduce a novel neural model, termed TANGO, for predicting task-specific tool interactions, trained using demonstrations from human teachers instructing a virtual robot. TANGO encodes the world state, comprising objects and symbolic relationships between them, using a graph neural network. The model learns to attend over the scene using knowledge of the goal and the action history, finally decoding the symbolic action to execute. Crucially, we address generalization to unseen environments where some known tools are missing, but alternative unseen tools are present. We show that by augmenting the representation of the environment with pre-trained embeddings derived from a knowledge-base, the model can generalize effectively to novel environments. Experimental results show a 60.5-78.9% absolute improvement over the baseline in predicting successful symbolic plans in unseen settings for a simulated mobile manipulator.